AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
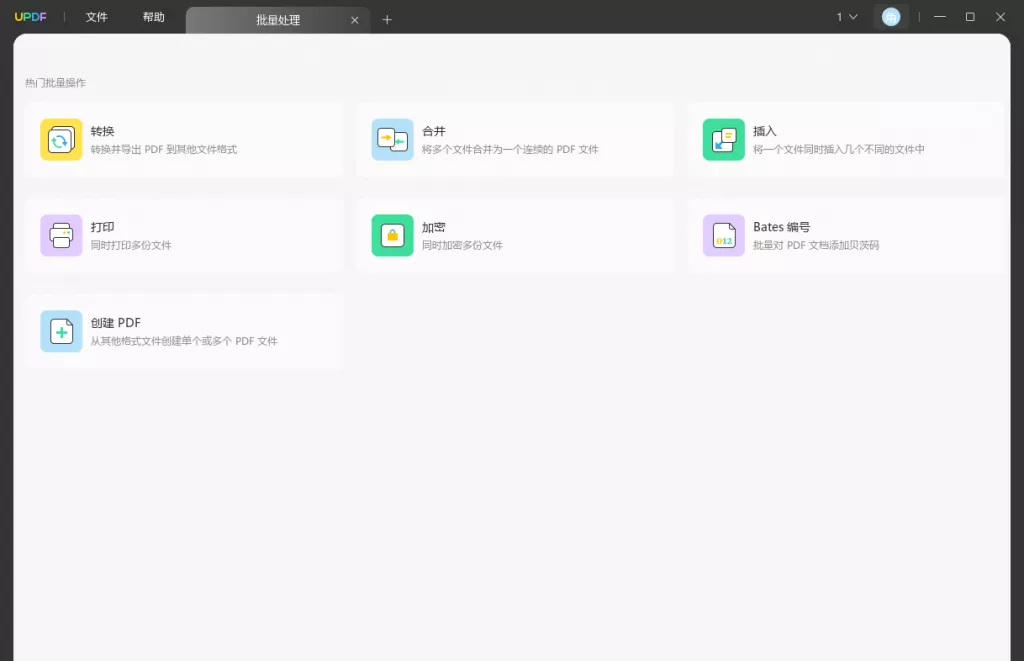
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南












在数字化时代,PDF文件已经成为了我们生活和工作中不可或缺的一部分。无论是合同、报告、还是电子书,PDF格式的文件因其兼容性和安全性被广泛应用。然而,在某些情况下,我们可能需要将PDF中的某些页面或全部页面提取为图片格式,以便于分享、编辑或者使用在其他项目中。那么,如何实现这一功能呢?本文将为您提供全面的解决方案,教您如何将PDF页面单独提取为图片,甚至提取整个PDF文件的所有页面。
为什么需要将PDF页面提取为图片?
在许多情况下,将PDF页面转换为图片格式可以提高文件的实用性。首先,图片格式可以更方便地在社交媒体上分享,因大多数平台对图片文件支持更好。其次,有些情况下我们需要对PDF文件中的特定内容进行编辑,而图片格式在图像处理软件中更为易用。最后,将PDF转为图片可以确保在分享过程中保持格式的完整性。
提取PDF页面的方法
提取PDF页面为图片可以通过多种方式实现,包括在线工具、桌面软件和一系列程序语言。以下是一些常用的方法:
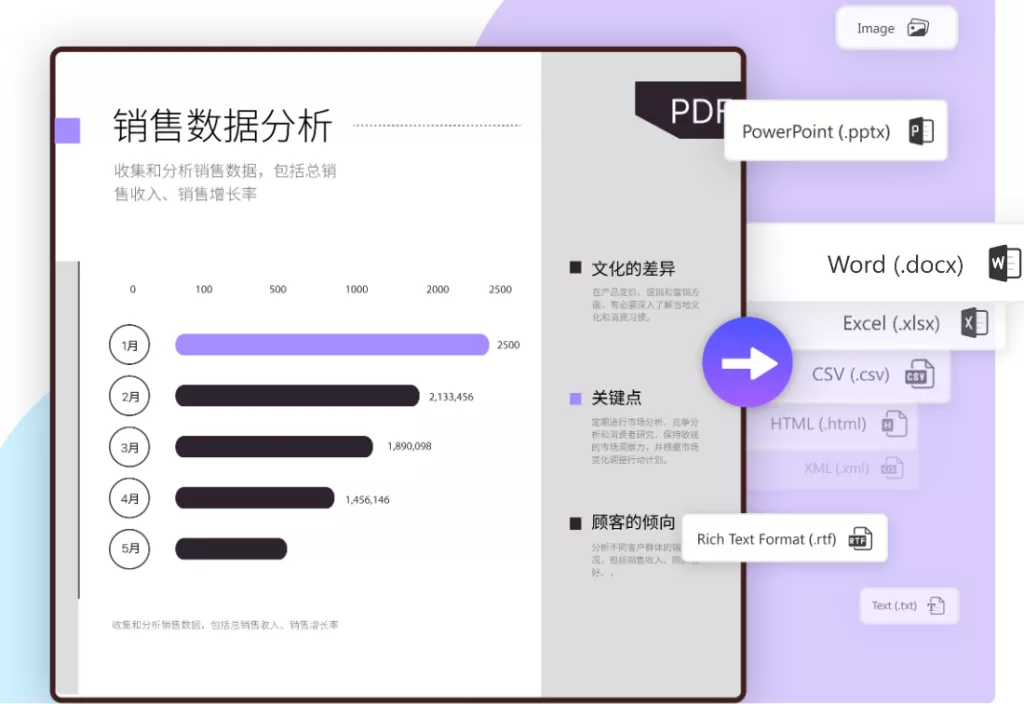
1. 在线工具:网络上有许多免费的在线服务可以快速将PDF文件转换为图片,例如Smallpdf、PDF to Image等。这些工具通常操作简单,用户只需上传想要转换的PDF文件,选择输出图片格式(如JPEG、PNG等),然后下载转换后的文件即可。
2. 电脑软件:如果您希望处理更大的PDF文件,或者需要更精细的设置,电脑软件可能更为合适。常用的软件包括UPDF、Adobe Acrobat、Nitro PDF、PDF-XChange等。这些软件通常提供批量处理、页面选择等功能,用户可以更为灵活地控制转换过程。
3. 编程语言:对于开发者而言,可以使用Python中的一些库(如PyMuPDF、Pillow等)来进行PDF页面的提取和转换。这种方法在处理大量文件或自动化任务时非常便利,但要求用户具备一定的编程基础。
使用在线工具提取PDF页面
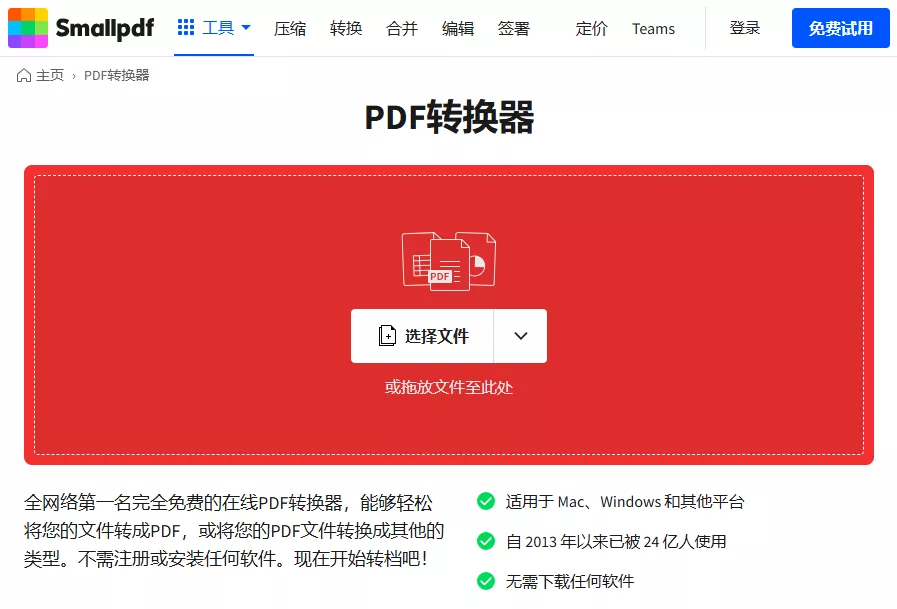
1. 选择在线工具
首先,您需要在互联网中搜索一个适合您的在线PDF转图片工具。以Smallpdf为例,进入其官方网站后,您将看到多个功能选项,如“PDF转JPEG”、“PDF压缩”等。
2. 上传PDF文件
点击“PDF转JPEG”选项后,您会看到一个文件上传框。在这里,您可以直接拖拽您的PDF文件,或者点击“选择文件”进行浏览。工具支持多种浏览器和设备,确保在不同的环境下都能顺利使用。
3. 选择输出格式
上传后,您可以选择是否提取全部页面或仅提取特定页面。有些工具还允许您选择输出的图片格式(如JPEG或PNG),以及图片的质量设置。
4. 下载转换后的图片
转换完成后,系统将提供一个下载链接,您只需点击链接即可将转换后的图片保存到您的设备中。通常,下载后的图片文件会被压缩为一个ZIP文件,您需解压后才能使用。
利用电脑软件提取PDF页面的步骤
1. 安装软件
选择一款适合的PDF格式转换软件,例如UPDF或PDF-XChange。下载并安装软件后,按照软件提示完成注册或授权。
2. 打开PDF文件
打开软件后,使用“文件”菜单中的“打开”选项,选择并打开您需要转换的PDF文件。
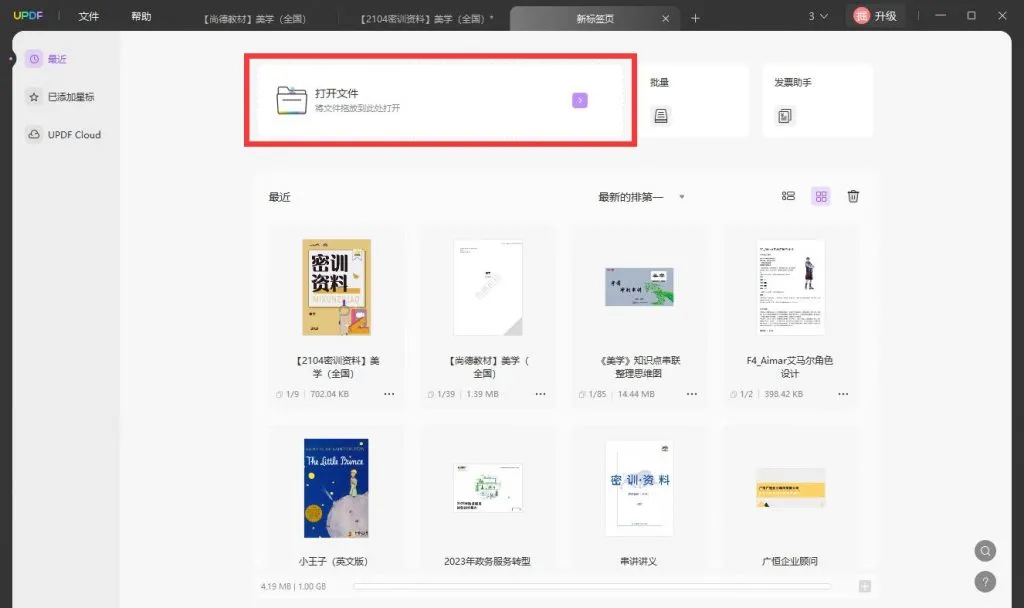
3. 选择PDF格式转换功能
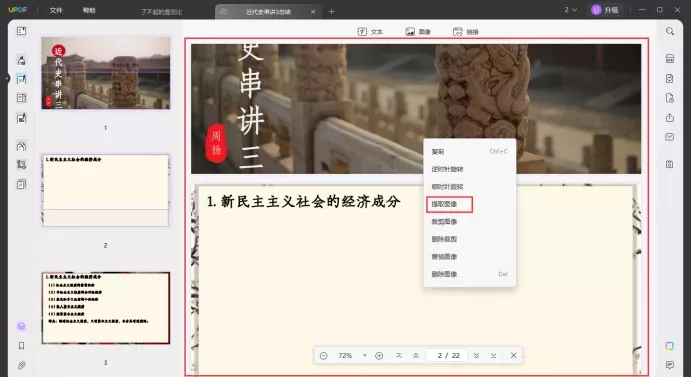
在UPDF中,您可以使用“工具”中的“导出PDF”功能,或者直接在右侧面板中选择“图片”选项,您可以按照需要选择单页或多页转换。
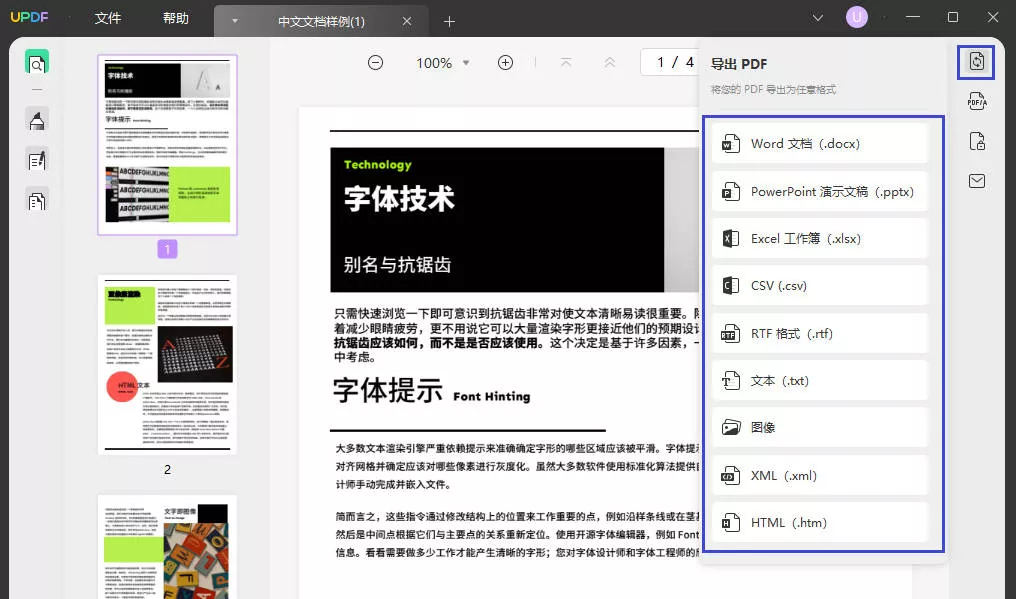
4. 设置参数
在输出设置中,您可以选择输出格式(如JPEG、PNG等),以及分辨率、质量等参数。这些设置对最终图片文件的效果有重要影响。
5. 保存文件
设置完成后,您可以指定一个保存路径,点击“保存”,软件便会自动将所选页面转换为图片并保存到指定位置。
使用编程语言提取PDF页面的步骤
对于熟悉编程的用户,Python提供了丰富的库,可以高效地提取PDF页面并转换为图片。
1. 安装相关库
您可以使用pip工具安装PyMuPDF和Pillow库:
“`bash pip install PyMuPDF Pillow “`2. 编写代码
以下是一个简单的示例代码,演示如何将PDF的每一页提取为JPEG格式的图片:
“`python import fitz PyMuPDF from PIL import Image pdf_file = ‘your_file.pdf’ doc = fitz.open(pdf_file) for page_num in range(len(doc)): page = doc.load_page(page_num) 加载页面 pix = page.get_pixmap() 将页面转换为Pixmap对象 img = Image.frombytes(“RGB”, [pix.width, pix.height], pix.samples) 生成PIL图像对象 img.save(f’page_{page_num + 1}.jpg’) 保存为JPEG文件 “`3. 运行程序
将上述代码保存为一个Python文件并运行,程序将自动提取PDF文件的每一页并保存为图片。
提取PDF页面的注意事项
1. 文件质量:在提取PDF页面时,不同的工具和设置会影响最终图片的质量,建议根据实际需求进行选择。
2. 隐私问题:使用在线工具时,确保不上传敏感或私密的PDF文件,以免造成信息泄露。
3. 版权问题:提取PDF页面时,确保您有权处理该文件,避免侵犯他人版权。
总结
将PDF页面提取为图片的过程在数字处理工作中十分常见,通过在线工具、桌面软件或编程语言等多种方式,用户可以根据自身需求选择合适的方法。无论是为了便捷的分享,还是进行深度的编辑,掌握这一技能都能为您的工作与生活带来便利。