AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













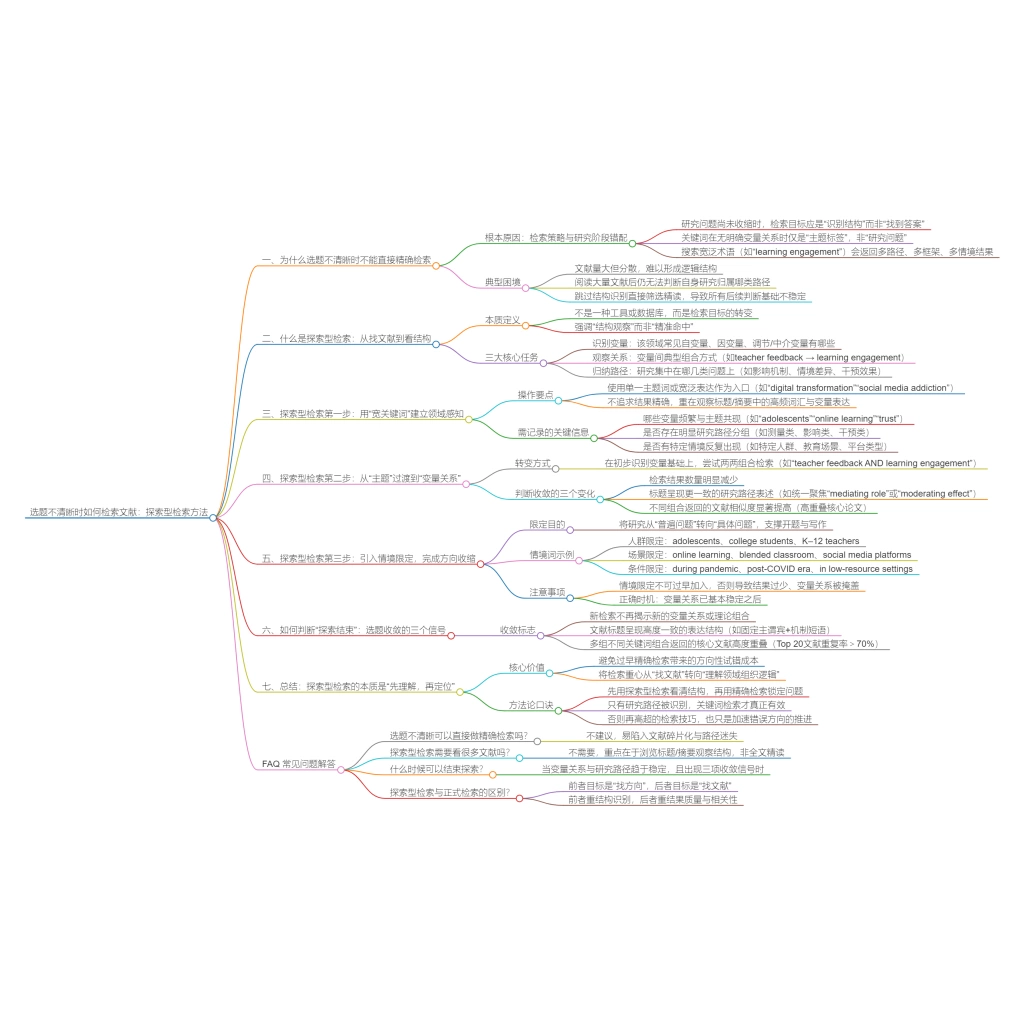
在法学研究中,文献检索并非简单的信息获取行为,而是研究设计的重要组成部分。与工程或医学不同,法学知识体系并不围绕实验数据或技术模型展开,而是建立在规范文本、判例推理以及学说解释之上。这种结构性差异,决定了法学文献检索在关键词构建与数据库选择上具有完全不同的逻辑。
如果仍然沿用“输入关键词—筛选论文”的通用路径,往往会出现两个问题:其一,检索结果缺乏稳定结构,难以形成清晰的论证体系;其二,关键判例或基础性法条被遗漏,导致研究缺乏规范支撑。因此,法学检索的核心任务,并不是扩大结果数量,而是建立一个能够同时覆盖法条、判例与学说的检索框架。

一、从关键词到概念体系:法学检索的起点转换
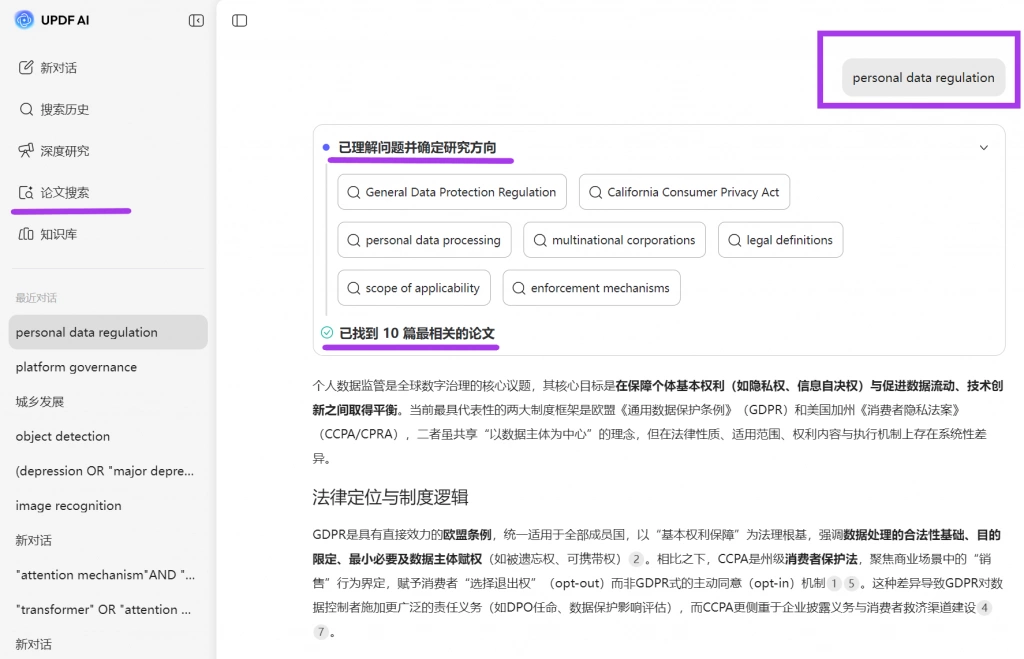
在多数研究领域,关键词通常被视为问题的直接表达,但在法学中,关键词首先是一种规范语境中的概念表达。同一法律问题,在不同法域或理论传统中,往往对应不同术语。例如,在研究“个人信息保护”时,可能出现data protection、privacy rights、informational self-determination、personal data regulation这些术语。这些表达并非简单同义替换,而是对应不同制度背景与理论路径。如果仅以单一术语进行检索,势必导致文献覆盖不完整。
因此,法学检索的第一步,不应直接构建关键词,而应构建一个概念集合。在实践中,可以通过 UPDF 的 AI 论文搜索功能输入一个基础概念,快速获取相关文献,并观察标题与摘要中的术语变化,从而识别该问题在不同语境中的表达方式。
这一过程的关键,不在于筛选文献,而在于建立“概念分布图”,为后续检索提供结构基础。
二、关键词结构化:从单一表达转向组合逻辑
在形成概念集合之后,需要将其转化为结构化检索式。与自然科学强调精确匹配不同,法学检索更强调语义覆盖与规范限定的平衡。
一个有效的检索结构通常包括三个维度:
第一是核心法律概念,即研究问题本身,例如contract liability或administrative discretion。
第二是规范类型或法律来源,例如statute、case law、regulation。
第三是法域或制度背景,例如European Union、United States、China。
通过布尔逻辑进行组合,可以形成如下检索式:(”data protection” OR “privacy rights”)AND (“case law” OR “judgment”)AND (“European Union”)。这种结构一方面通过OR扩展概念范围,避免遗漏;另一方面通过AND限定研究语境,提高结果的解释价值。
需要强调的是,法学检索式具有明显的迭代特征。研究者需要根据检索结果不断调整关键词组合,而不是一次性设定后固定不变。
三、数据库差异:法学研究的多源结构特征
与工程领域依赖会议论文不同,法学研究的文献来源呈现出明显的多层结构。这意味着数据库选择必须围绕“资料类型”展开,而非使用习惯。
1️⃣ 学术数据库:如Web of Science、Scopus,用于获取法学期刊论文与理论研究。
2️⃣ 法律数据库: 如Westlaw、LexisNexis,用于检索判例与法条,是法学研究的核心资源。
3️⃣ 区域数据库:如CNKI或各国官方法律网站,用于获取本地法律资料与政策文本。
法学检索的关键,不在于选择一个“最佳数据库”,而在于建立不同数据库之间的对应关系。例如,通过学术论文识别关键判例,再在法律数据库中查找原始裁判文书。
在这一过程中,可以先通过UPDF的AI论文搜索获取相关研究,再逐步延伸至具体法律数据库,从而实现“学说—判例—法条”的联动。
四、文献筛选标准:从相关性转向规范价值判断
在法学研究中,文献筛选并非单纯基于主题相关性,而是基于其在论证体系中的功能。
主要判断维度包括:
- 是否引用关键判例或核心法条
- 是否提出明确的法律解释路径
- 是否在该领域具有代表性
这一判断过程通常需要深入阅读,而难以通过摘要完成。
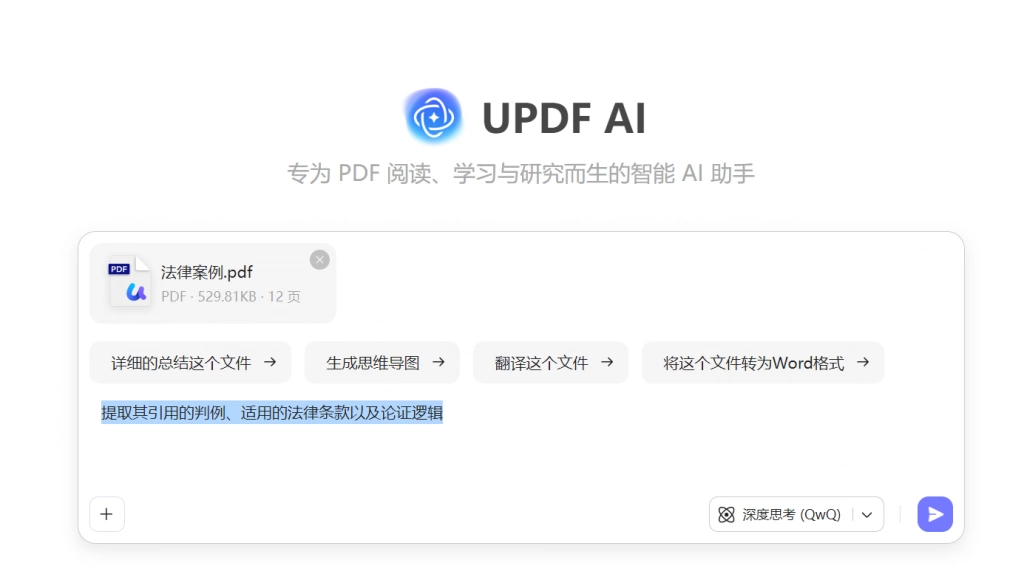
在实践中,可以借助 UPDF 的多文件问答功能对多篇文献进行统一提问,例如提取其引用的判例、适用的法律条款以及论证逻辑。通过这种方式,可以快速识别不同研究之间的解释差异,并确定哪些文献构成研究基础。
五、法条与判例定位:检索能力的核心体现
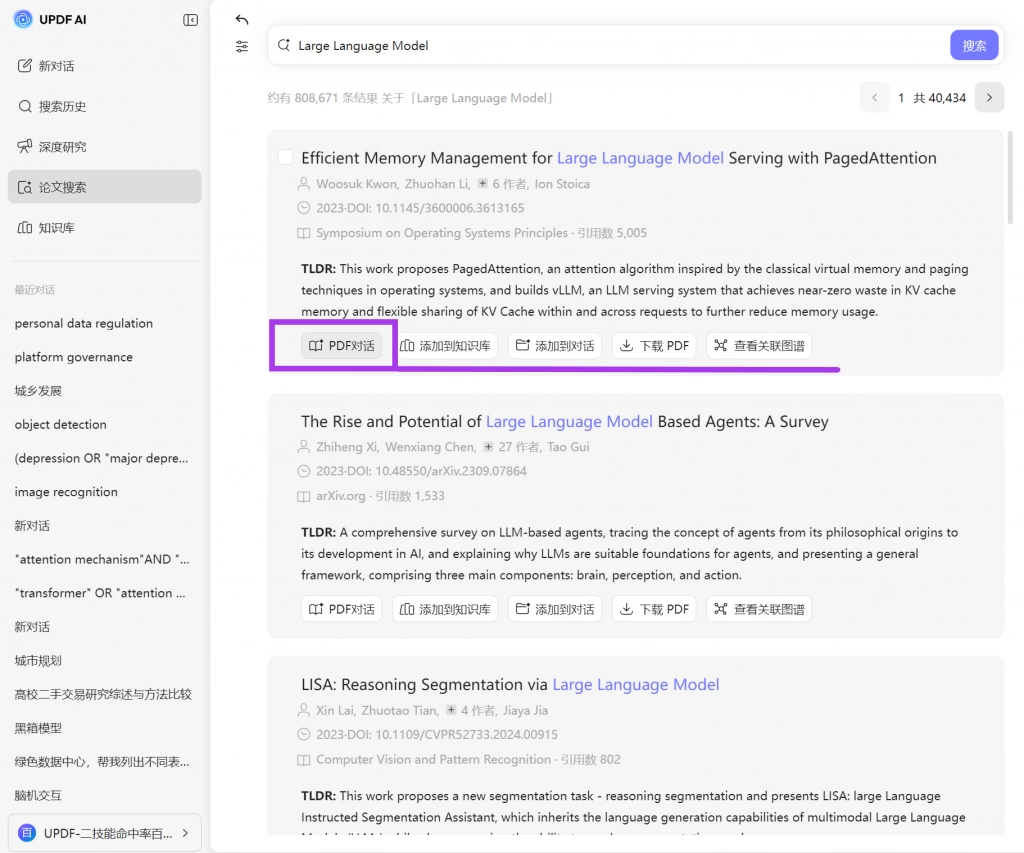
法学检索与其他学科的一个根本区别,在于必须实现对具体规范文本的精确定位。很多研究者虽然能够找到相关论文,但无法快速定位其中引用的法条或判例,从而影响论证深度。因此,检索不仅包括文献查找,还包括规范文本定位能力。
在实际操作中,可以利用 UPDF 的全文搜索或文档对话功能,在PDF中快速定位特定法条编号、案例名称或关键词。这一能力在处理长篇判决书时尤为重要,可以显著提升效率。更重要的是,它能够帮助研究者建立论文与规范文本之间的直接对应关系,从而增强论证的严谨性。
六、文献整合:从材料收集到论证结构建构
法学研究的最终目标,是构建一个具有说服力的论证体系。因此,文献检索的终点并不是获得资料,而是形成结构。
在整合阶段,可以按照以下逻辑进行分类:
- 按法律问题划分
- 按理论立场分类
- 按判例支持路径组织
通过这种方式,不同文献不再是孤立存在,而是成为论证结构中的组成部分。
在实践中,可以结合多文件问答对不同观点进行对比,从而明确各类文献在整体论证中的位置。
七、常见问题
1.法学检索为什么不能只用关键词? 因为同一法律问题在不同法域中存在多种表达方式。
2.为什么必须查判例? 判例是法律解释的重要依据,直接影响论证有效性。
3.如何提高检索效率? 建立结构化关键词体系,并结合多数据库使用。
4.文献过多如何处理? 应按论证路径进行分类,而不是继续扩大检索范围。
总结
从整体来看,法学文献检索并不是信息获取过程,而是一种围绕规范文本与法律解释展开的结构建构活动。它要求研究者在检索过程中不断调整概念表达,识别不同法域与理论路径,并最终形成一个具有解释力的论证体系。
当检索能够服务于这一过程时,它就不再是研究的前期准备,而成为研究本身的重要组成部分。