AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













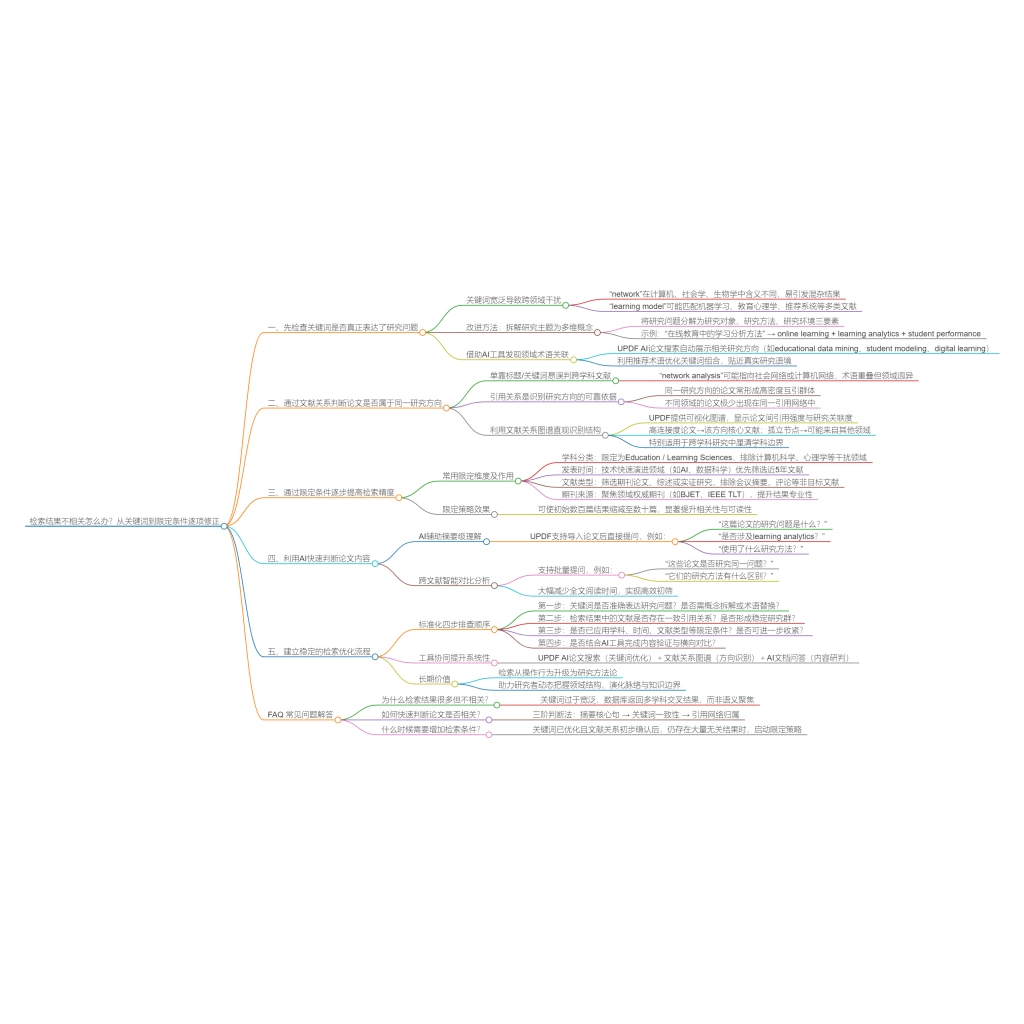
在科研过程中,文献检索与文献筛选往往被视为两个连续步骤,但在实际操作中,这二者之间却存在一个显著的“方法断层”。大量研究者虽然能够通过数据库获取足够数量的文献,却在进入筛选阶段时陷入停滞,其表现形式通常包括:无法确定优先阅读顺序、筛选标准反复变化、以及在阅读过程中不断回退至重新检索。这一现象的本质,并非执行能力不足,而是缺乏一个明确的检索—筛选衔接机制。换言之,问题并不在于“如何筛选文献”,而在于如何将“检索结果”转化为“可操作的筛选结构”。
如果这一转化缺失,研究者将不得不在无序信息中反复试探,从而导致时间成本与认知负担显著增加。因此,有必要从方法论层面,对这一过渡过程进行系统拆解。
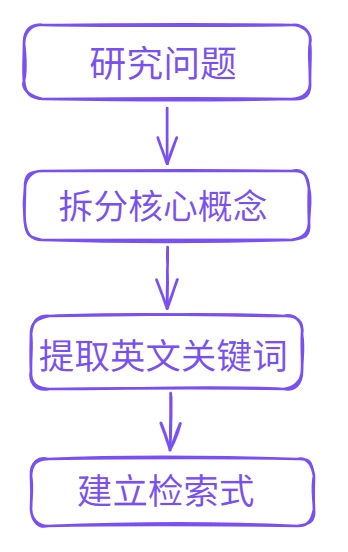
1、结构转换:从“结果列表”到“候选文献集”的建构
在完成检索之后,研究者首先面对的是一个由数据库排序机制生成的结果列表。这一列表虽然在形式上具有“相关性排序”,但在本质上仍属于信息集合,而非研究结构。如果直接基于该列表进入阅读阶段,筛选过程将缺乏稳定参照,从而难以形成一致性判断。
因此,筛选的起点必须是一次明确的结构转换,即将“结果列表”转化为“候选文献集”。这一过程的核心目标,是识别潜在的研究路径,并对文献进行初步分组,而非判断其最终价值。
在实践中,可以借助UPDF的AI论文搜索功能对检索结果进行整体性观察,并重点关注以下结构性信号:
- 标题与摘要中反复出现的变量组合(variable co-occurrence patterns)
- 不同文献之间共享的理论术语(theoretical anchors)
- 某些研究路径呈现出的聚集性分布(clustered distribution)
通过这种方式,原本线性排列的结果列表,可以被重构为若干具有内部一致性的文献子集。此时,筛选工作才真正拥有了结构基础。
2、筛选标准的形式化:从经验判断到可复用规则
在传统操作中,文献筛选往往依赖研究者的主观判断,例如“这篇看起来更相关”或“这篇更接近我的主题”。然而,这种经验性判断难以保证一致性,也无法在多轮筛选中保持稳定。
因此,有必要将筛选标准进行形式化(formalization),即将其转化为可重复执行的判断规则。一个成熟的筛选标准体系,通常应包含以下维度:
第一,文献是否明确呈现变量关系结构(explicit variable linkage),而非仅停留在概念描述; 第二,是否嵌入特定理论框架(theoretical positioning),并具备解释路径; 第三,其研究方法是否具有可比较性(methodological comparability); 第四,该文献在研究网络中是否具有一定的代表性或影响力(representativeness)。
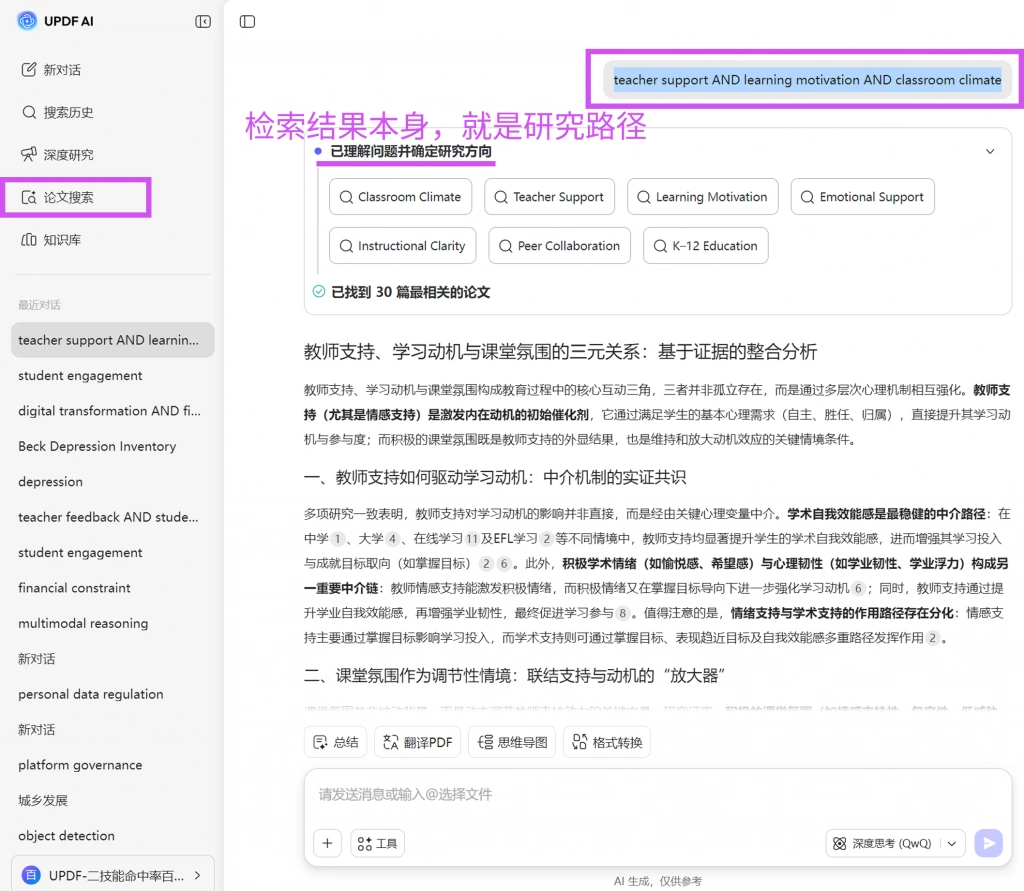
在操作层面,可以利用UPDF的AI总结或文档对话功能对文献进行快速结构提取,例如统一提问:
- 该研究的核心变量是什么?
- 变量之间的关系如何定义?
- 所采用的理论框架是什么?
通过这种结构化提问,可以在短时间内完成对大量文献的标准化评估,从而避免因阅读顺序不同而导致的判断偏差。
3、分层筛选机制:初筛与精筛的功能区分
在筛选流程中,一个关键问题在于时间分配。若在早期阶段投入过多精读时间,将显著降低整体效率;反之,如果筛选过于粗略,则可能遗漏关键文献。因此,有必要引入分层筛选机制。
该机制通常包括两个层级:
第一层为初筛(screening),其目标是基于标题与摘要完成快速收敛。此阶段应以结构信息提取为主,而非深入阅读。AI总结功能在此阶段尤为关键,因为它可以在不阅读全文的情况下,提取变量、方法与结论。
第二层为精筛(selection),其目标是对核心文献进行深度分析,并评估其在研究框架中的具体作用。此阶段才需要投入较多阅读时间,并结合文档对话对关键问题进行深入探究。
通过这一分层机制,可以实现资源的合理分配,使筛选过程既高效又可靠。
4、路径识别:从单篇筛选到研究结构构建
随着筛选的推进,研究者需要完成一个重要转变:从关注单篇文献,转向识别研究路径。在多数领域中,文献并不是孤立存在的,而是围绕特定变量组合与理论框架形成若干稳定路径。
因此,在筛选过程中,应逐步完成文献的路径划分,例如:
- 基于不同变量关系形成的因果路径
- 基于不同理论视角形成的解释路径
- 基于不同方法设计形成的研究路径
这一过程的目标,是将文献集合转化为一个具有层级结构的网络,而非简单列表。
5、交付物定义:筛选结果的结构化输出
筛选的最终价值,不在于减少文献数量,而在于生成一组可直接支持研究的结构化成果。因此,有必要对筛选阶段的交付物进行明确界定。
一个完整的筛选交付物,应至少包括:
- 核心文献集合:经过筛选后保留的关键文献
- 结构化分类体系:按变量、理论或方法划分
- 文献摘要信息:每篇文献的关键要素说明
在实践中,可以通过UPDF的知识库功能对上述内容进行统一管理,并为每篇文献添加变量、理论与方法标签。这样不仅可以支持当前研究,还能够为后续检索提供复用基础。
6、过程复用:从一次筛选到方法体系的沉淀
在完成筛选之后,如果未对过程进行记录,则下一次检索仍需从零开始。因此,筛选流程的最后一步,应是建立过程复用机制。
具体而言,应记录以下内容:
- 检索式与关键词组合
- 筛选标准与判断规则
- 文献分类与路径划分依据
通过这一机制,可以将一次筛选经验转化为可重复使用的方法模板,从而显著提升后续研究效率。
FAQ
1️⃣ 为什么检索后很难进入筛选? 因为缺乏结构转换步骤,结果列表未转化为候选文献集。
2️⃣ 筛选标准如何建立? 应形式化为变量、理论与方法三个维度。
3️⃣ 如何提高筛选效率? 通过分层筛选与AI结构提取减少无效阅读。
4️⃣ 筛选的最终目标是什么? 生成结构化文献体系,而非简单减少数量。
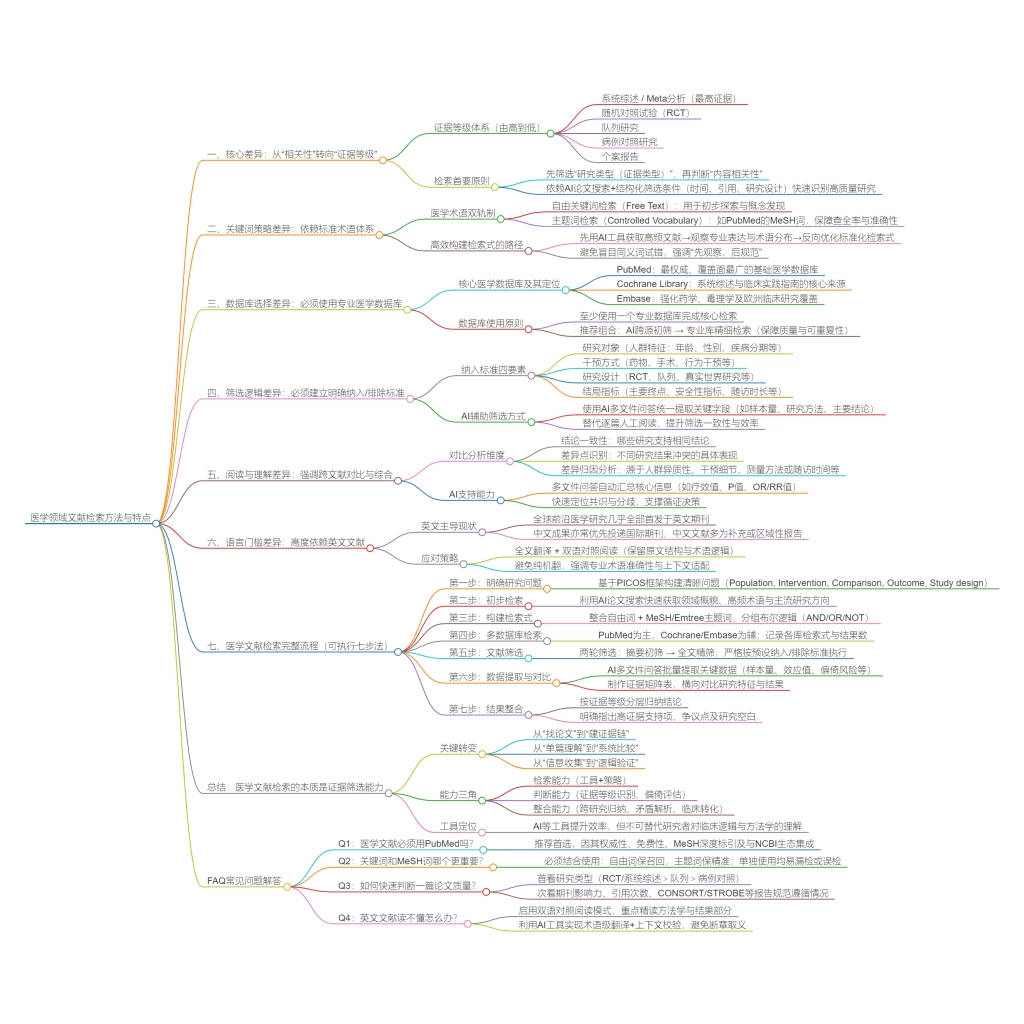
7、总结
从方法论角度来看,文献筛选并不是简单的过滤行为,而是一种结构生成机制。它通过对文献的识别、分类与重组,使研究者能够从无序信息中构建出具有解释力的研究框架。
当检索与筛选之间建立起稳定衔接时,文献处理将不再是重复劳动,而成为研究不断深化的基础。