AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













很多研究者在做文献检索时,其实并不清楚自己到底是在“找几篇论文来读”,还是在“系统性地获取某一研究主题的全部关键文献”。这两种目标看起来很像,操作上却不是一回事,最终得到的研究质量也往往相差很大。
在日常学习或写作初期,大多数人都是打开数据库,输入几个关键词,翻几页结果,挑出标题看起来最接近自己研究问题的论文,然后开始下载、阅读、做笔记。这种方式并没有错,而且在很多场景下已经够用,比如你只是想大致了解一个主题,或者准备一门课程报告,需要快速找到几篇参考文献。
但问题是,一旦你的研究目标从“了解一下”变成“比较完整地梳理研究现状”,检索方式就不能继续停留在这种层面上了。因为普通检索依赖检索者当下想到的关键词、当下使用的数据库、以及当下浏览结果时的主观判断。换句话说,它能帮你找到一些文献,却未必能保证你找到的是足够全面、足够有代表性、并且可复核的一组文献。这也是为什么在写毕业论文、文献综述、开题报告、系统综述,甚至一些研究方案设计时,越来越多研究者会强调系统性文献检索。
所谓系统性文献检索,并不是把普通检索做得“更认真一点”,也不是多搜几个数据库那么简单。你需要在检索开始之前,就明确研究问题、界定检索边界、设计检索式、规定筛选标准,并在检索完成后对文献进行系统整理和可追溯记录。它更像是一种研究方法,而不只是一个查资料的动作。
这篇文章会给大家讲清楚 什么是系统性文献检索,它和普通检索到底差在哪里,哪些研究场景必须用它,以及怎样把它真正落到操作层面。
一、普通检索到底“普通”在哪里?
所谓普通检索,并不是说它低级,而是说它通常服务于一个更灵活、更开放、也更即时的目标。你可能只是对某个问题产生兴趣,想快速看看有没有相关研究;也可能是写论文时突然意识到某一部分文献不够,于是临时补搜几篇。这个时候,检索本身并不是研究设计的一部分,而更像是阅读的辅助动作。
普通检索最常见的特点有三个。
第一,它往往从关键词直接出发。 也就是说,你想到了什么词,就搜什么词;搜不到,就再换一个表达方式。整个过程高度依赖检索者的经验和即时判断。
第二,它通常没有严格的纳入和排除标准。 你看到哪篇顺眼、哪篇标题更贴近自己的问题、哪篇摘要看起来更容易用,就优先保留它。至于为什么留下这篇而不是另一篇,很多时候并没有明确规则。
第三,它的结果很难完全复现。 因为如果换一个人来搜,或者你自己过几天再搜一次,只要关键词、数据库、时间范围稍有变化,结果都可能不同。
这并不意味着普通检索没有价值。事实上,在很多非正式研究场景里,它反而是最有效率的。问题在于,当你的研究需要的是“尽量完整、可解释、可追溯的文献集合”时,普通检索就会显得不够稳。
二、什么是系统性文献检索?
系统性文献检索,本质上是一种有计划、有边界、有记录的文献获取方式。它强调的不是“搜到几篇论文”,而是“在明确规则下,尽可能完整地覆盖一个研究问题相关的文献范围”。
这里有几个关键词非常重要。
第一个关键词是问题导向。 系统性检索不是先想关键词,而是先想研究问题。你到底要回答什么问题?研究对象是什么?情境是什么?时间范围是什么?这些都会决定你后面的检索设计。
第二个关键词是检索策略。 在系统性检索里,关键词不会随意更换,而是要经过设计。你需要列出核心概念、同义表达、相关术语,并通过布尔逻辑把它们组织成一套可以重复执行的检索式。
第三个关键词是筛选标准。 哪些文献纳入?哪些排除?为什么?是不是只要期刊论文?是否包含会议论文?是否限定近五年?这些都不能临时决定,而要在检索前尽量明确。
第四个关键词是可追溯性。 系统性检索强调过程记录。你用了哪些数据库、哪些检索词、筛掉了多少篇文献、保留了哪些研究,理论上都应该能够说明白。这一点对于综述写作尤其重要。
所以,系统性文献检索和普通检索最大的差别,不在于“搜得更久”,而在于它从一开始就把检索当成研究设计的一部分。
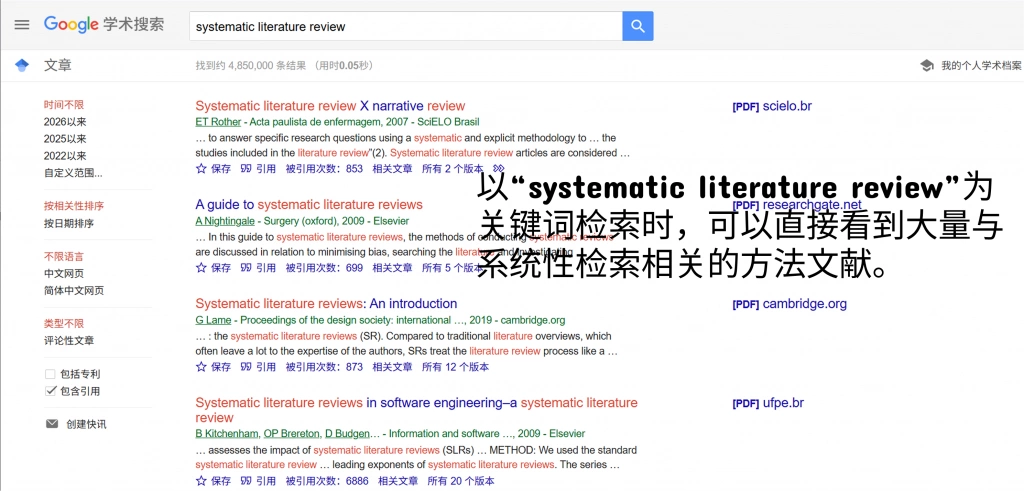
三、系统性检索与普通检索,真正的区别在哪里?
很多人以为,系统性检索只是普通检索的“加强版”,其实不完全准确。更准确地说,它们回答的是两种不同层级的问题。
普通检索解决的是我能找到哪些相关论文,而系统性检索解决的是在一套可解释的规则下,能否尽可能完整地覆盖了这个研究问题的相关文献?因此,两者的区别至少体现在以下几个方面。
- 在目标上,普通检索强调效率和实用性,系统性检索强调完整性和方法论可靠性。
- 在操作上,普通检索依赖即时判断,系统性检索依赖事先设计。
- 在结果上,普通检索更适合快速了解,系统性检索更适合正式综述、研究现状梳理和证据整合。
- 在记录上,普通检索往往没有完整痕迹,系统性检索则要求每一步都尽可能清楚。
也正因为如此,系统性检索并不是“更麻烦的检索”,而是当你的研究目标上升到一定严谨度之后,不得不采用的一种方式。
四、哪些场景必须尽量靠近“系统性检索”?
不是所有研究都必须做最严格意义上的系统综述,但有些场景,至少应该采用更接近系统性检索的思路。
第一类场景,是写文献综述。 如果你要讲的是“这个领域到底研究到了什么程度”,那就不能只凭几篇熟悉的论文做判断。否则你写出来的综述更像主观阅读总结,而不是研究现状分析。
第二类场景,是写开题报告。 开题的核心问题之一,是证明你的研究问题成立,且你知道这个问题在现有研究里处于什么位置。如果前期检索太随意,很容易导致研究定位失准。
第三类场景,是做方法比较或证据整合。 比如你要比较某类方法的效果,或者梳理某个问题在不同研究中的结论,这种情况下文献来源如果不系统,后面的比较就很容易失真。
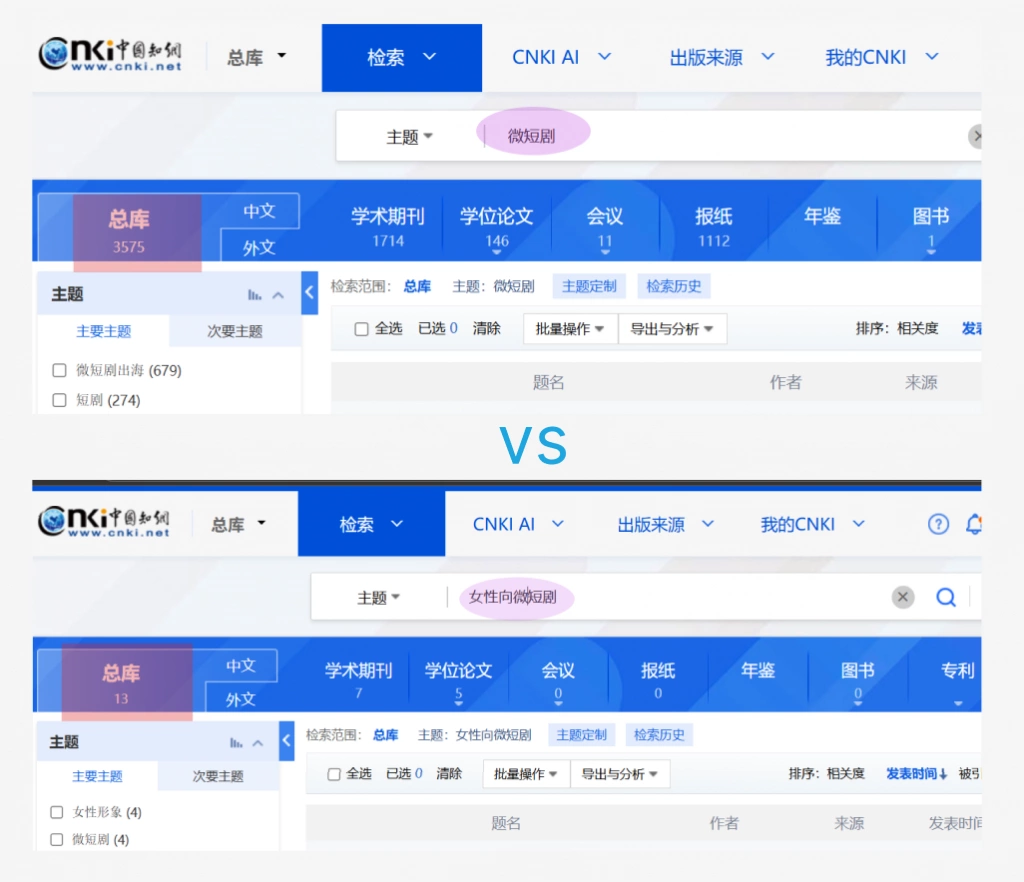
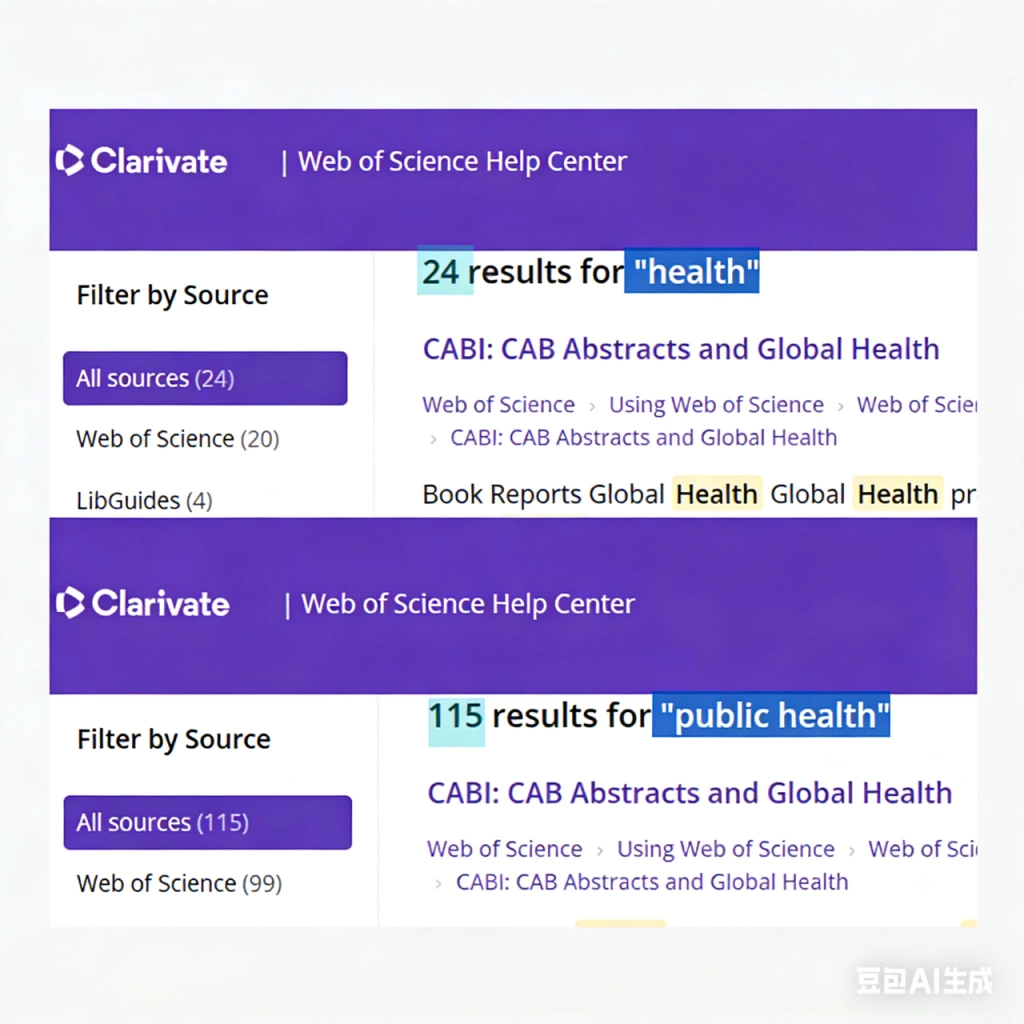
第四类场景,是跨学科研究。 因为跨学科检索最容易遗漏文献。不同领域对同一个概念的表达可能不同,如果不提前设计检索策略,只靠普通检索很难真正覆盖到位。
五、系统性检索到底怎么做?
很多人看完“系统性检索”的定义之后,会觉得它听起来很对,但操作上还是模糊。真正落到实践中,至少要做四步。
第一步,先把研究问题说清楚。 不要急着写关键词,先把问题拆成几个核心维度。比如研究对象、核心变量、研究情境、时间范围、文献类型等。这个动作会直接决定后面的检索精度。
第二步,设计检索式。 把核心概念扩展成关键词组,再组织成一套可重复执行的检索表达。这个过程最好不是想到什么搜什么,而是先列词,再组合,再试搜,再优化。
第三步,建立筛选规则。 例如是否只保留期刊论文,是否限定近十年,是否排除非英文或非中文文献,是否去掉明显不相关的研究场景。规则不一定要极其复杂,但一定要提前想清楚。
第四步,做结构化整理。 系统性检索真正难的不是“搜到”,而是“整理”。如果你前面搜到几十篇、上百篇文献,最后还是散落在文件夹和标签里,那前面的系统性也会打折。
这个阶段,工具就很重要了。比如围绕一个研究主题,先用 UPDF AI 的深度研究快速把主要问题、主要方向和代表性研究拉出一个结构框架,再把筛选后的文献放进去持续补充,会比从零散 PDF 文件开始整理高效很多。
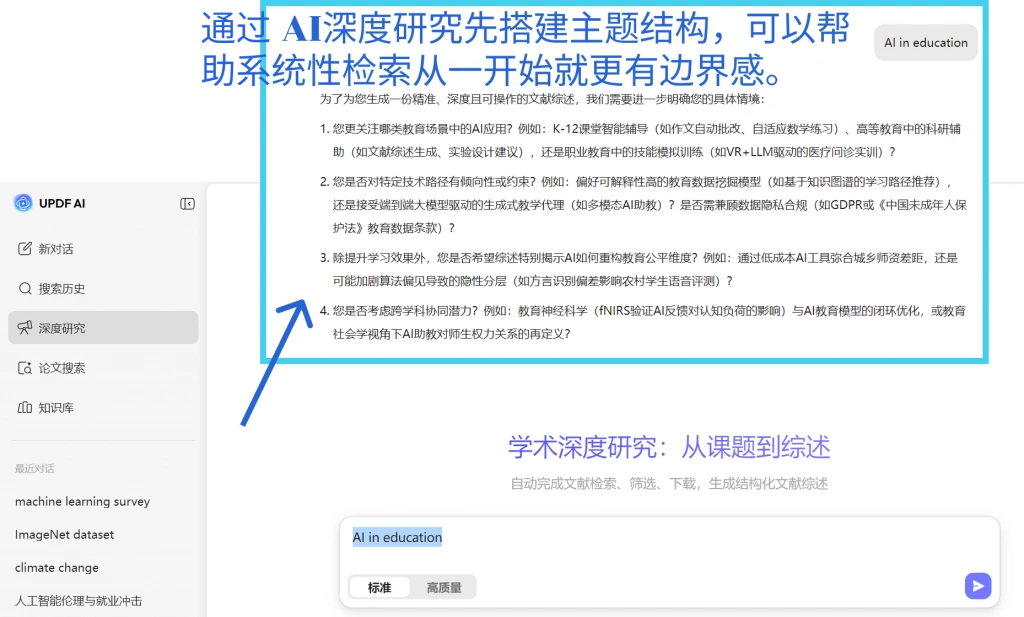
六、系统性检索后的难题,不是找不到文献,而是看不清关系
一旦你真正开始按系统性方式检索,新的问题很快就会出现:
文献并不少,甚至可能很多,但如何比较它们、判断它们之间的关系,反而变成更大的工作量。
这也是为什么很多人前期检索做得还可以,真正到写综述时却仍然很乱。因为系统性检索拿到的是一个“更完整的文献集合”,而不是自动生成的结论。你还需要对这些文献进行比较、归类和解释。
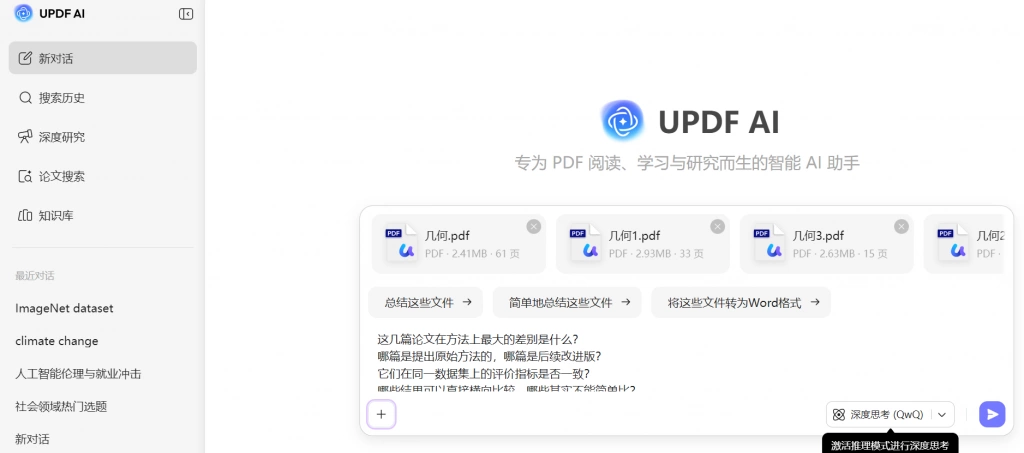
在这种情况下,UPDF AI 的多文件问答就比单篇阅读更有帮助。你可以把同一主题下筛选出来的一批核心文献一起放进去,直接问:
- 这些研究主要分成哪几类?
- 它们在方法设计上最大的差异是什么?
- 哪些论文结论相近,哪些存在明显分歧?
- 哪些研究是真正的基础文献,哪些只是应用型延伸?
这样做的意义不在于“省事”,而在于把系统性检索后最耗时的一步——关系判断——尽量结构化。
七、怎样保证系统性检索不是做完就散?
最后一个常被低估的问题是:很多人即使做了一次比较规范的检索,后面也没有积累下来。结果就是,下次写相关主题时,又要重新开始。
如果想让系统性检索真正产生复利,最关键的是把结果沉淀下来。 这也是为什么我会把第三个功能放在全文搜索上。因为系统性检索并不是一次性产出,而是一个后续可复用的体系。你在整理文献时,后面一定会不断回看、补查、验证某个术语或某个方法是否真的在这批文献中出现过。全文搜索能让你在已有文献池里快速校验,而不是每次都重新靠记忆翻找。
换句话说,系统性检索的真正价值,不只是第一次检索时“更完整”,而是它让你后面所有关于这个主题的阅读、写作和比较,都有了一个更稳的底座。
关于系统性文献检索的常见问题
问题1:系统性文献检索是不是只适用于医学或系统综述?
回答:不是,很多开题报告、文献综述和方法比较研究,其实都需要接近系统性检索的思路。
问题2:普通检索就一定不可靠吗?
回答:不一定,普通检索适合初步了解主题,但如果要做正式研究综述,它通常不够完整。
问题3:系统性检索最关键的一步是什么?
回答:不是搜得多,而是先把研究问题、检索式和筛选标准设计清楚。
问题4:为什么系统性检索后还是会觉得乱?
回答:因为检索只是第一步,后续还需要做文献比较和结构化整理。
问题5:怎么提高系统性检索后的分析效率?
回答:可以用 UPDF AI 的多文件问答对核心文献做集中比较,再用全文搜索校验关键概念是否真正覆盖。
总结
系统性文献检索和普通检索的差别,不在于前者更复杂、后者更简单,而在于它们服务的研究目标不同。普通检索适合快速了解问题,系统性检索则适合在明确研究问题之后,尽可能完整、可解释、可复核地构建文献基础。
如果你的目标只是找到几篇论文开始读,普通检索已经足够;但如果你要写的是综述、开题、方法比较或者研究现状分析,那么检索本身就不能再只是一个临时动作,而应该成为研究设计的一部分。
在实际操作中,结合 UPDF AI 的深度研究、AI多文件问答和全文搜索,可以更快地先把研究问题结构化,再把文献关系看清楚,最后在已有文献池中持续验证和补充。 这时候,文献检索就不再只是“找资料”,而是真正开始服务于研究判断本身。