AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













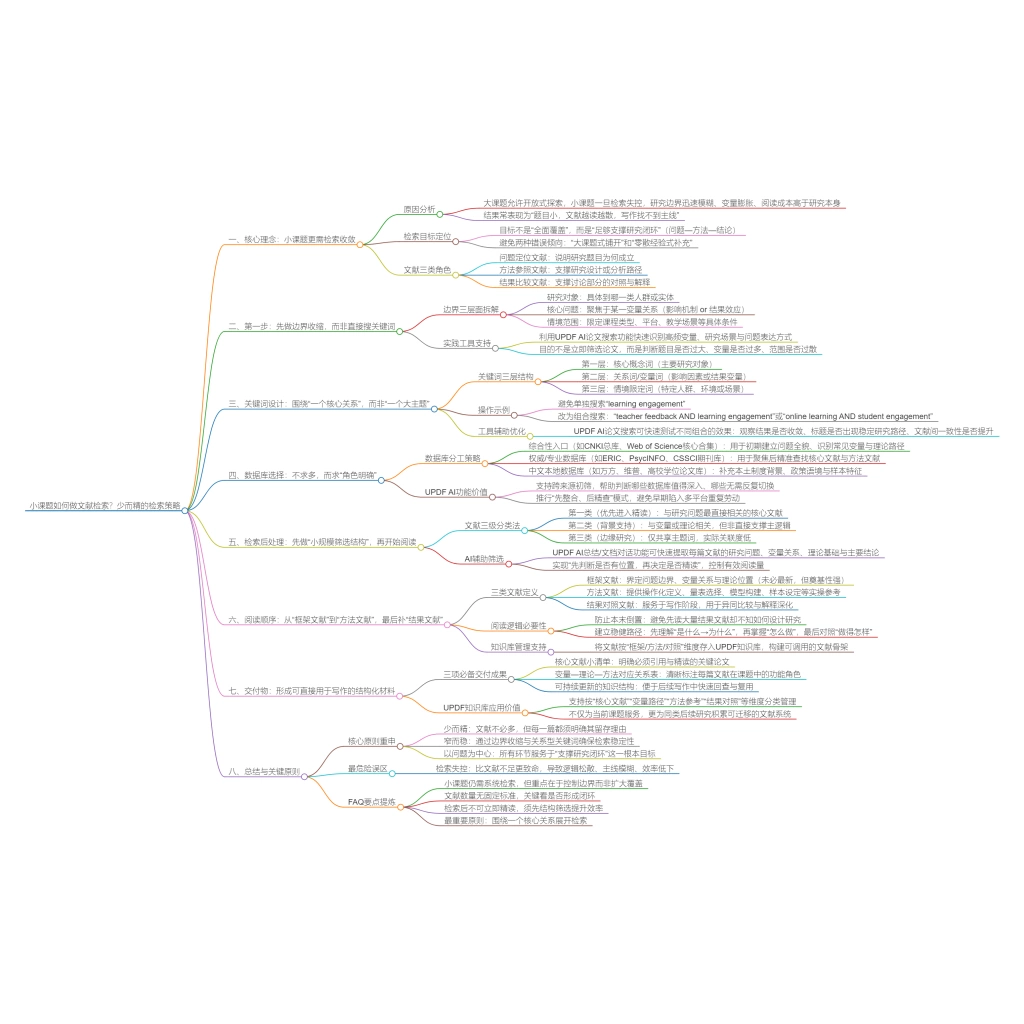
你有没有这种体验:花了两三个小时搜文献,下载了几十篇 PDF,文件夹里堆得满满当当,但真正要写论文时,却发现:好像没有一篇是“必须引用的核心文献”、说不清领域发展脉络,导师一句“这几篇经典论文你没看?”直接就让你破防。于是开始怀疑自己:是不是检索能力太差?
其实,大多数人不是不会搜,而是 一直在用低效方式瞎搜。文献搜索拼的从来不是手速,而是策略。下面这几条底层技巧,几乎决定了你能不能快速找到真正的核心论文。
一、你可能一开始就搜错了:关键词太“泛”
这是最常见的问题,比如很多同学喜欢这样搜:新能源 材料 研究,结果全是“大而全”的普通论文。原因很简单:关键词越泛,结果越水。搜索引擎只会做“字符串匹配”,不会帮你理解语义。
真正有效的关键词,往往具备三个特征:
① 用专业术语,而不是口语描述
❌ 图像算法
✅ Vision Transformer / U-Net / ResNet
② 用具体任务,而不是大方向
❌ 医学影像
✅ lung nodule detection
③ 直接搜文献类型
加上 review / survey / meta-analysis
很多时候,一篇综述就能帮你省下几十篇阅读时间。
👉 技巧总结:关键词越具体,结果越精准。
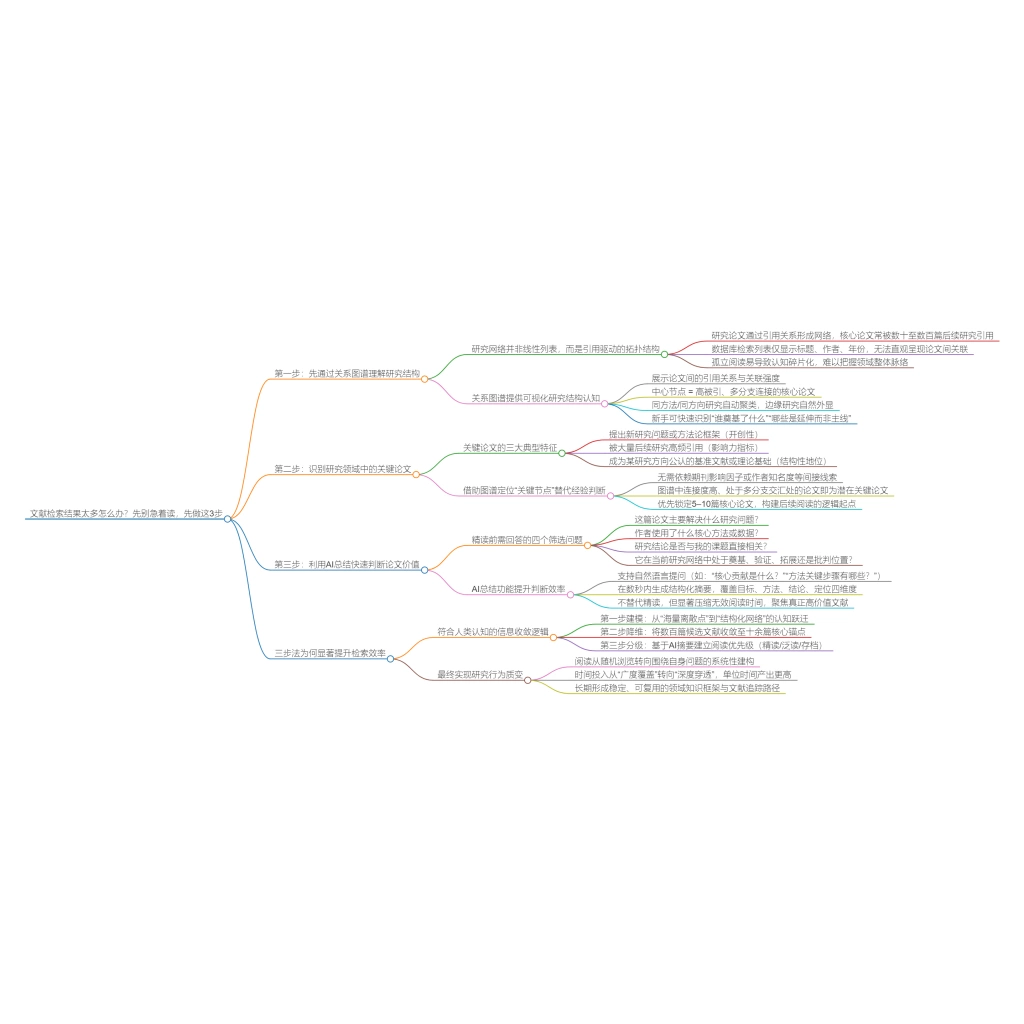
二、你读得太早了:没有“先筛选”
另一个低效习惯是:一搜到论文 → 立刻点开 → 从头读到尾。
但现实是:读 1 篇 ≈ 30–60 分钟,读 30 篇 = 一整天没了,而且很可能 80% 都没价值。
真正高效的流程是三步筛选法:
① 标题判断相关性(10 秒)
② 摘要+结论快速浏览(2 分钟)
③ 只有高度相关才精读
记住一句话:阅读是高成本行为,只给核心论文。
先筛选,再投入。很多时候 100 篇文献里,真正值得读的可能只有 10–20 篇。
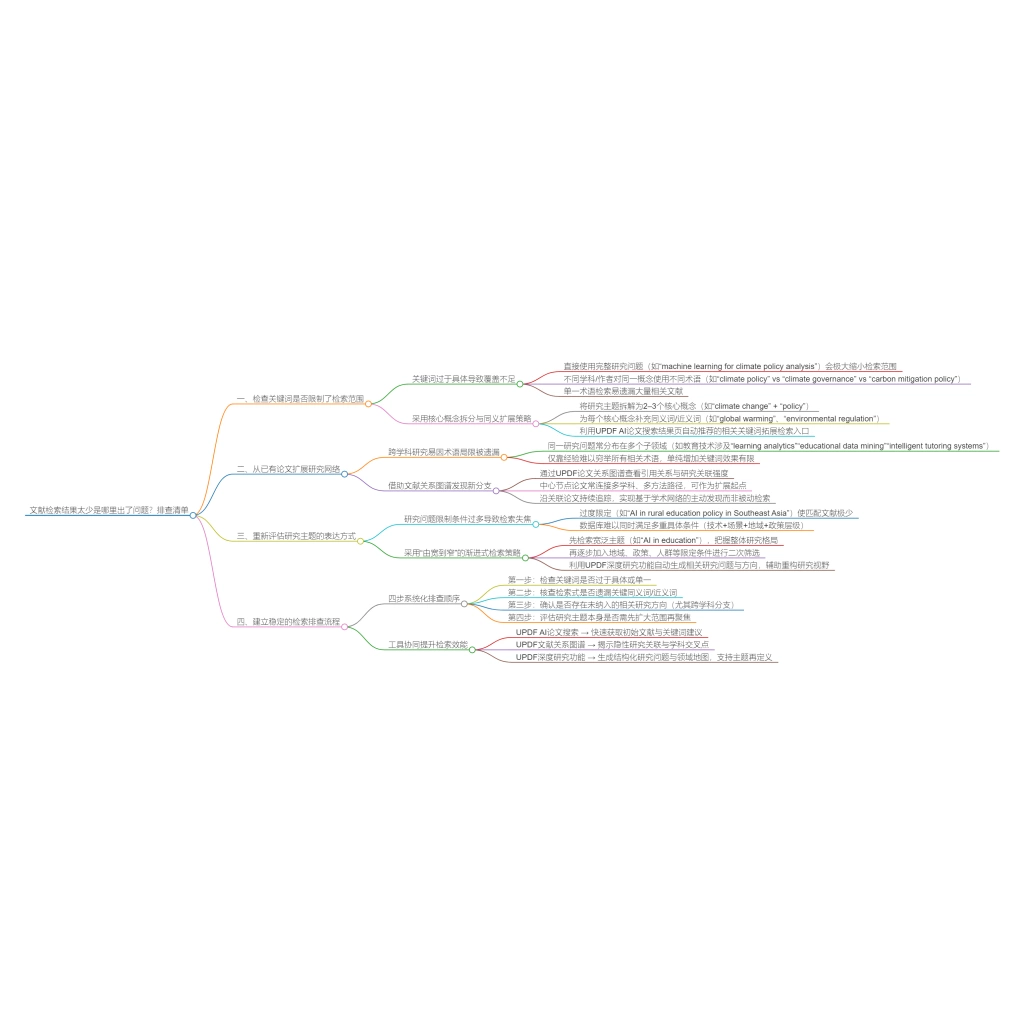
三、你只靠搜索,没有利用“引用网络”
这是新手和导师差距最大的地方。多数人只会换关键词 → 重新搜索 → 翻页,但真正的高手几乎不用翻页,他们用的是引用关系。
原因很简单:重要论文一定被大量引用。所以更高效的方式是:
1️⃣ 找到一篇高引用综述或经典论文
2️⃣ 看它“引用了谁”和“被谁引用”
你会发现:被反复引用的 = 领域基石,最近引用多的 = 最新进展。顺着这条线走,几乎不会踩雷。相比盲目搜索,这种方式更像是“顺藤摸瓜”。
四、你读完就关:没有做任何整理
很多人都有这种错觉:我读过了,应该记住了。但两天后就全忘。
问题在于:只阅读,不加工,大脑几乎不会长期记忆。真正有效的阅读一定包含:高亮重点、写批注、记录创新点、横向对比、做思维导图/表格。

只有“重新整理信息”,知识才会变成自己的。现在不少人会直接在 PDF 阅读工具里完成这些操作:批注记录思路、一键总结论文核心、多篇同时对比问答、自动生成思维导图,阅读效率提高了很多。
五、你在“收集论文”,而不是“建立结构”
很多同学的文献夹是这样的:
📁 paper1.pdf
📁 paper2_final.pdf
📁 最新版_真的最终版.pdf
文件越来越多,但认知并没有增长,因为收集 ≠ 理解。真正有效的做法是:
- 建立对比表格(方法/数据/创新点)
- 梳理技术演进路线
- 总结每一类研究思路
当你能说清:“这个领域主要分三条路线,各自代表论文是……”说明你才真正掌握了文献。科研本质是建立知识结构,而不是堆文件。
总结
为什么你总是找不到核心论文?说到底,是这几个习惯在拖后腿:关键词太泛、不筛选直接读、不用引用网络、只看不整理、只收集不归纳。而高效检索的正确姿势其实很简单:精准搜 → 快速筛 → 深度读 → 做整理 → 顺引用扩展。
当你换成这套策略后,会明显感觉到:搜得更少、找得更准、读得更快、写得更顺。同样时间,效率翻倍。
文献搜索从来不是苦力活,而是方法活。掌握逻辑,比多花时间重要得多。