AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













在写毕业论文、准备开题报告或进行文献综述时,很多人发现单一数据库的检索结果往往不够全面。
刚开始做文献检索时,很多研究者习惯只用一个熟悉的数据库。例如,有人长期使用知网,有人只依赖 Google Scholar,还有人习惯在 Web of Science 中查找英文文献。 这种做法看起来很方便,但在科研实践中重要文献是分散在不同数据库中的。
例如,一些中文研究主要集中在知网和万方;部分国际期刊论文则更容易在 Web of Science 或 Scopus 中找到;而一些开放获取论文可能主要分布在 Google Scholar 或机构仓库中。
如果只使用单一数据库,很容易出现这样的情况:
- 找到大量文献,但结构偏向某一个学科数据库
- 关键论文出现在其他数据库,却没有被检索到
- 不同数据库之间的研究信息无法互相补充
因此,在做系统文献检索时,很多研究者都会采用多数据库组合检索。简单来说,就是通过多个数据库同时或依次检索,再将结果进行整合与筛选。这样不仅可以减少文献遗漏,还可以更清晰地理解一个研究领域的整体结构。这篇文章将从实际科研流程出发,讲清楚一个问题如何在多个数据库同时检索,并建立一套稳定的组合检索策略。
一、为什么需要多个数据库组合检索?
很多新手在文献检索中会误认为某一个数据库已经“足够全面”,实际上,不同数据库的收录范围和侧重点是不同的。
例如知网主要收录中文学术期刊、硕博士论文和部分会议论文,Web of Science 更侧重国际核心期刊,Google Scholar 的覆盖面较广,但结果质量差异较大。
一些学科数据库则专门收录某一领域研究,如果只依赖一个数据库,很容易出现信息偏差。因此,在比较严谨的研究工作中,很多研究者都会至少使用两个或三个数据库交叉检索。通过这种组合方式,可以有效减少文献遗漏。
不过,多数据库检索并不是简单地“每个数据库都搜一遍”。如果没有明确策略,检索结果往往会出现大量重复文献和研究结构难以整理。
所以,多数据库检索的关键不在“多”,而在于如何组合检索策略。
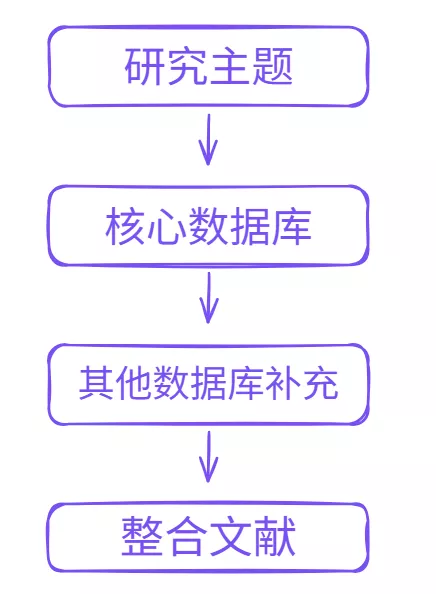
二、组合检索的第一步:确定核心数据库
在进行多数据库检索之前,最好先确定一个核心数据库。例如,在社会科学研究中,很多研究者会先在知网或 Web of Science 中进行第一轮检索。通过这一步,可以找到一些高被引论文或综述文章,从而了解研究主题的大致发展脉络。
当核心文献逐渐明确后,再到其他数据库中进行补充检索,就会更加有针对性。
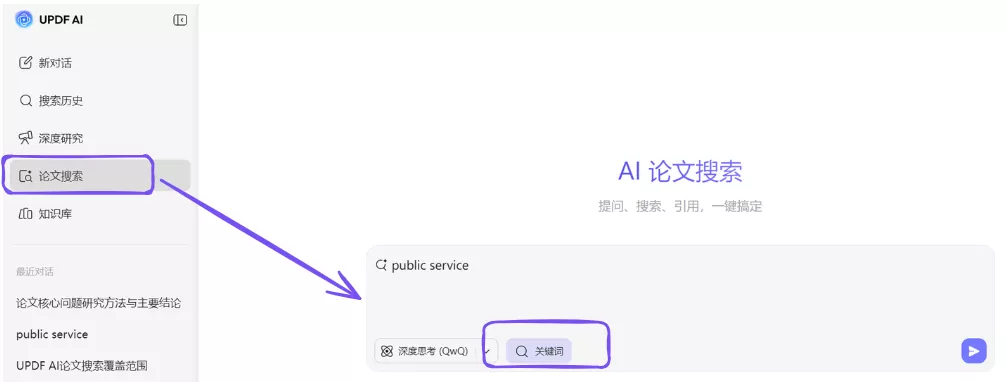
在这个阶段,UPDF AI 的 AI 论文搜索功能可以作为一个很实用的入口。 因为它聚合了来自多个学术数据库的论文资源,并支持语义搜索。研究者可以直接输入研究主题,快速获得一批相关论文,并观察这些论文的关键词、研究方法和引用关系。
由于 UPDF AI 论文搜索可检索超过2.2亿篇学术论文资源,它在“快速建立领域文献列表”这一阶段往往非常高效。
通过这一步,研究者可以先形成一个基础文献集合,再到其他数据库中继续扩展。
三、组合检索的第二步:跨数据库扩展文献
当第一批核心文献确定后,接下来就可以跨数据库扩展检索。这一阶段的目标不是重新开始检索,而是围绕已经找到的核心论文进行扩展。我们可以查看核心论文的参考文献、搜索论文作者的其他研究或者检索相同关键词在其他数据库中的结果。
例如,如果你在某个数据库中找到一篇重要论文,可以用论文标题或作者名称在其他数据库中再次搜索。很多时候,你会发现同一研究团队在不同期刊中发表过一系列相关研究。
通过这种方式,可以逐渐扩大文献范围,同时避免盲目检索。
但随着文献数量增加,研究者不知道不同数据库检索结果如何统一分析。如果只是逐篇阅读论文,很容易陷入反复切换数据库和 PDF 的低效状态。
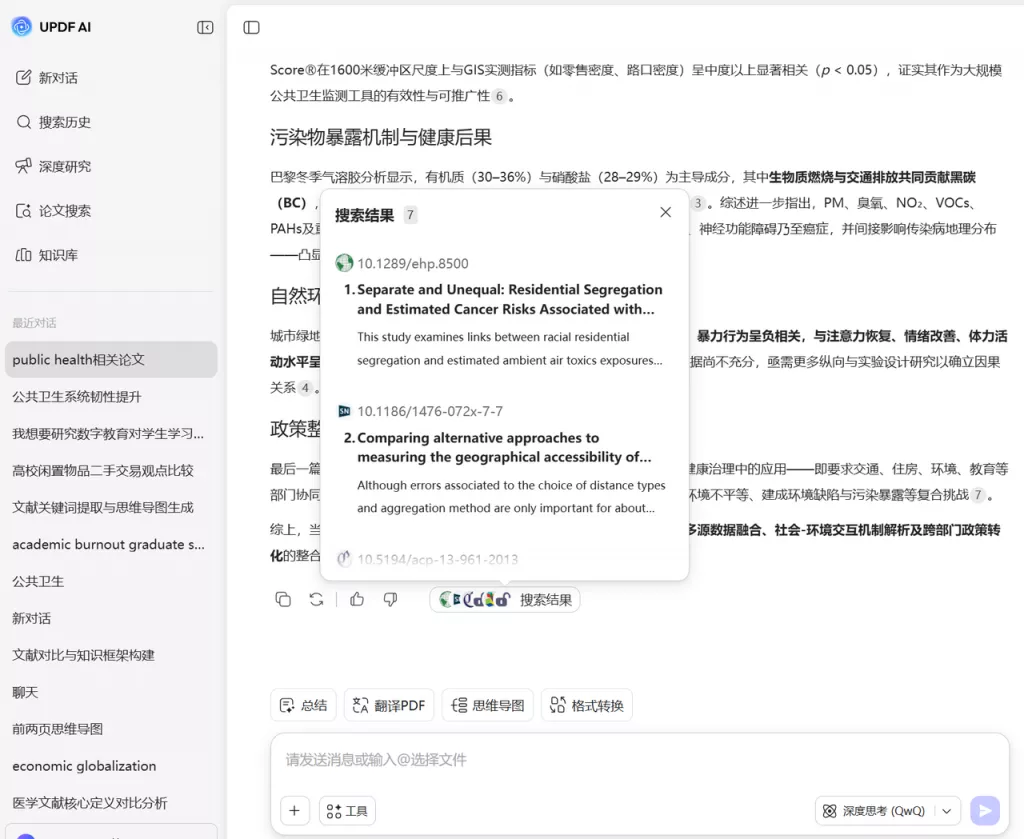
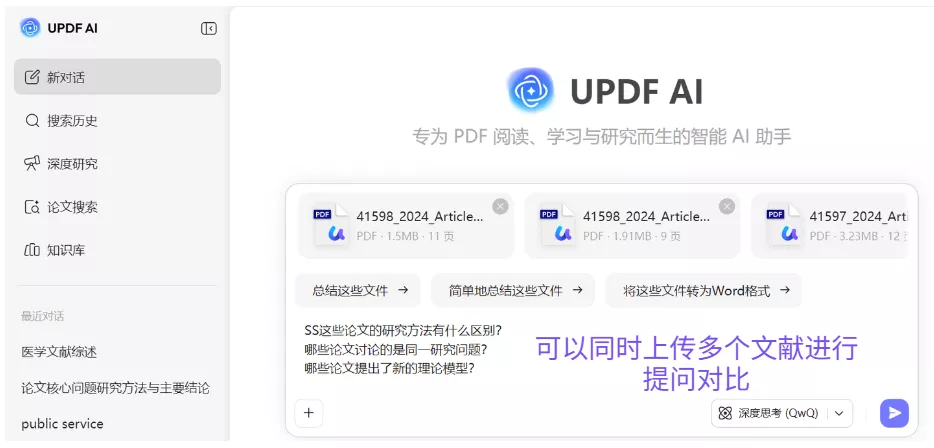
在这种情况下,UPDF AI 的多文件问答功能可以帮助提高效率。 研究者可以把来自不同数据库的多篇论文导入 UPDF,然后向 AI 提问,例如:
- 这些论文的研究方法有什么区别?
- 哪些论文讨论的是同一研究问题?
- 哪些论文提出了新的理论模型?
AI 会根据多个文件内容生成对比分析,从而帮助研究者更快识别关键文献和研究方向。
对于需要阅读几十篇甚至上百篇论文的人来说,这种跨文献分析方式可以节省大量时间。
四、组合检索的第三步:建立统一文献库
当多个数据库的文献逐渐整合之后,最后一个重要步骤是 建立统一文献库。如果没有统一管理,研究者很容易遇到这些问题:
- 不同数据库下载的论文分散在电脑各处
- 不记得某篇论文来自哪个数据库
- 写论文时需要重新查找文献
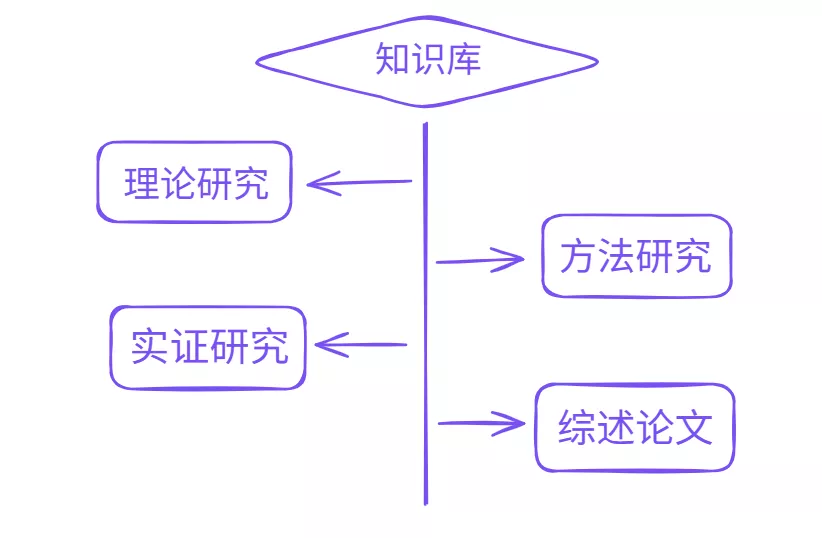
因此,在多数据库检索完成后,最好把所有核心论文集中整理。在 UPDF 的知识库功能中,可以按照研究主题建立不同分类。
当新的论文导入时,可以直接归入对应分类。这样一来,无论论文最初来自哪个数据库,都可以在同一系统中统一管理。
这种方式不仅能减少文献混乱,还能帮助研究者逐渐形成自己的学术资料库。对于需要长期做科研的人来说,这一点尤为重要。
五、一个更稳定的多数据库检索流程
如果把前面几个步骤整合起来,就可以形成一个比较稳定的多数据库检索流程。
第一步:选择核心数据库进行初始检索
确定研究主题,找到第一批核心论文。
第二步:利用论文信息扩展检索
通过作者、关键词、参考文献在其他数据库中继续检索。
第三步:整合不同数据库的文献
避免重复,同时补充遗漏研究。
第四步:跨文献对比分析
利用 AI 工具快速理解不同研究之间的关系。
第五步:建立统一知识库
将所有文献分类存储,方便后续阅读和引用。
通过这样的组合策略,多数据库检索就不再是一件混乱的事情,而是一种系统化的研究过程。
常见问题
Q1:为什么需要多个数据库检索?
A:不同数据库收录范围不同,多数据库检索可以减少文献遗漏。
Q2:多个数据库检索会不会重复很多论文?
A:会有重复,但通过整理和分类可以减少影响。
Q3:如何统一管理不同数据库下载的文献?
A:可以使用 UPDF 知识库进行集中管理和分类。
总结
在科研工作中,单一数据库检索往往难以覆盖所有重要文献。 因此,多数据库组合检索逐渐成为越来越常见的研究方法。
不过,多数据库检索的关键不在“数量”,而在于是否建立了清晰策略。通过先确定核心数据库,再进行跨数据库扩展,并将文献统一整理到知识库中,研究者可以逐渐建立完整的文献体系。
在这一过程中,像 UPDF 这样的 AI 学术工具可以在多个环节提供帮助,例如:
- 通过AI论文搜索快速建立基础文献列表
- 通过多文件问答进行跨文献对比分析
- 通过知识库统一管理来自不同数据库的文献
当检索、阅读和整理形成完整流程时,多数据库检索就不再是繁琐操作,而会成为科研工作中非常稳定的一部分。