AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













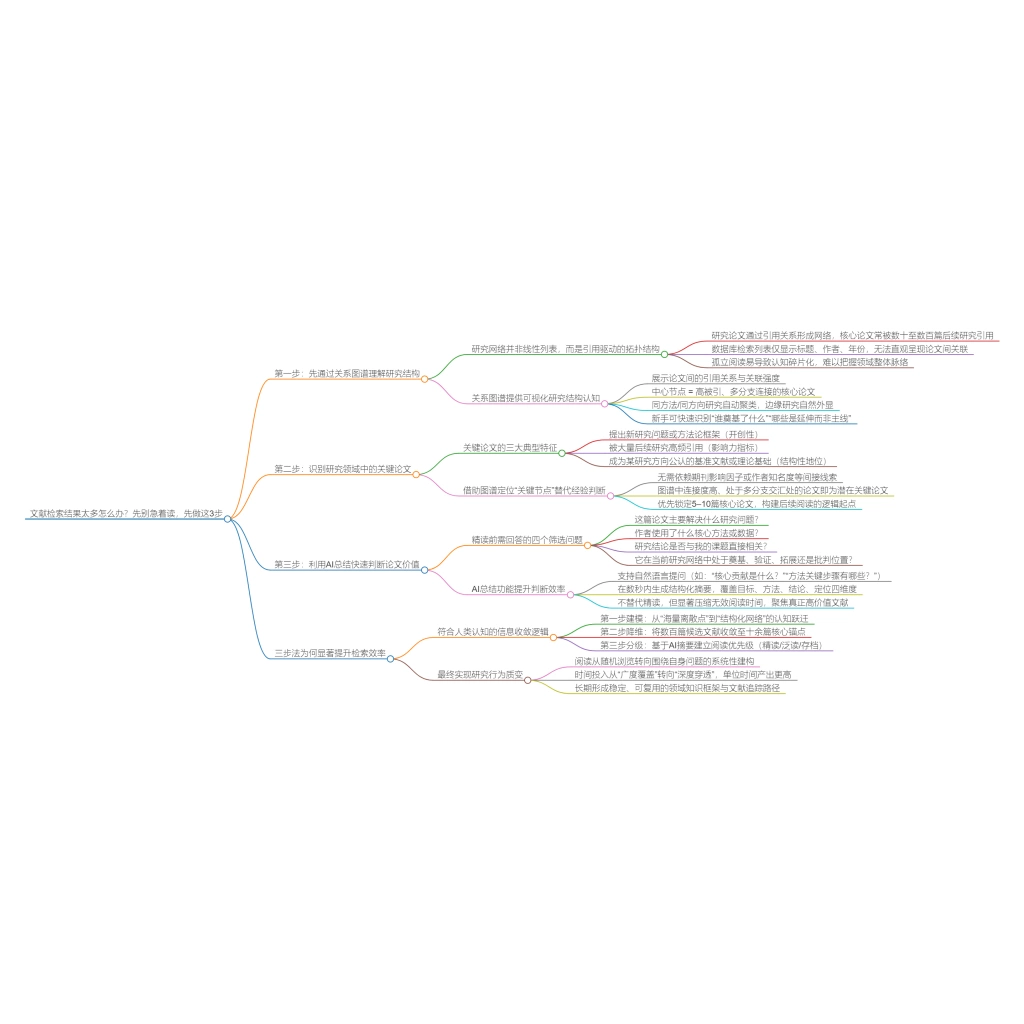
在工程类研究中,文献检索往往被误解为一个“前置操作”,即通过关键词搜索获取一定数量的论文,然后进入阅读与写作阶段。然而,从实际科研经验来看,这种线性理解往往导致两个问题:一是检索结果与研究方向之间存在偏差,二是文献数量虽多,但缺乏结构性与可用性。
究其原因,并不在于数据库或工具,而在于工程类文献本身具有明显不同于其他学科的特征。工程研究通常围绕具体技术路径、算法实现以及应用场景展开,其知识结构并非单纯以问题为中心,而是呈现出“方法驱动”的组织方式。因此,如果仍然沿用通用的“问题导向关键词检索”,往往难以有效覆盖核心研究。
本文将从关键词构建逻辑、数据库选择机制以及检索流程优化三个层面,系统分析工程类文献检索的有效方法,并说明如何在实际科研过程中建立一套可复用的检索策略。
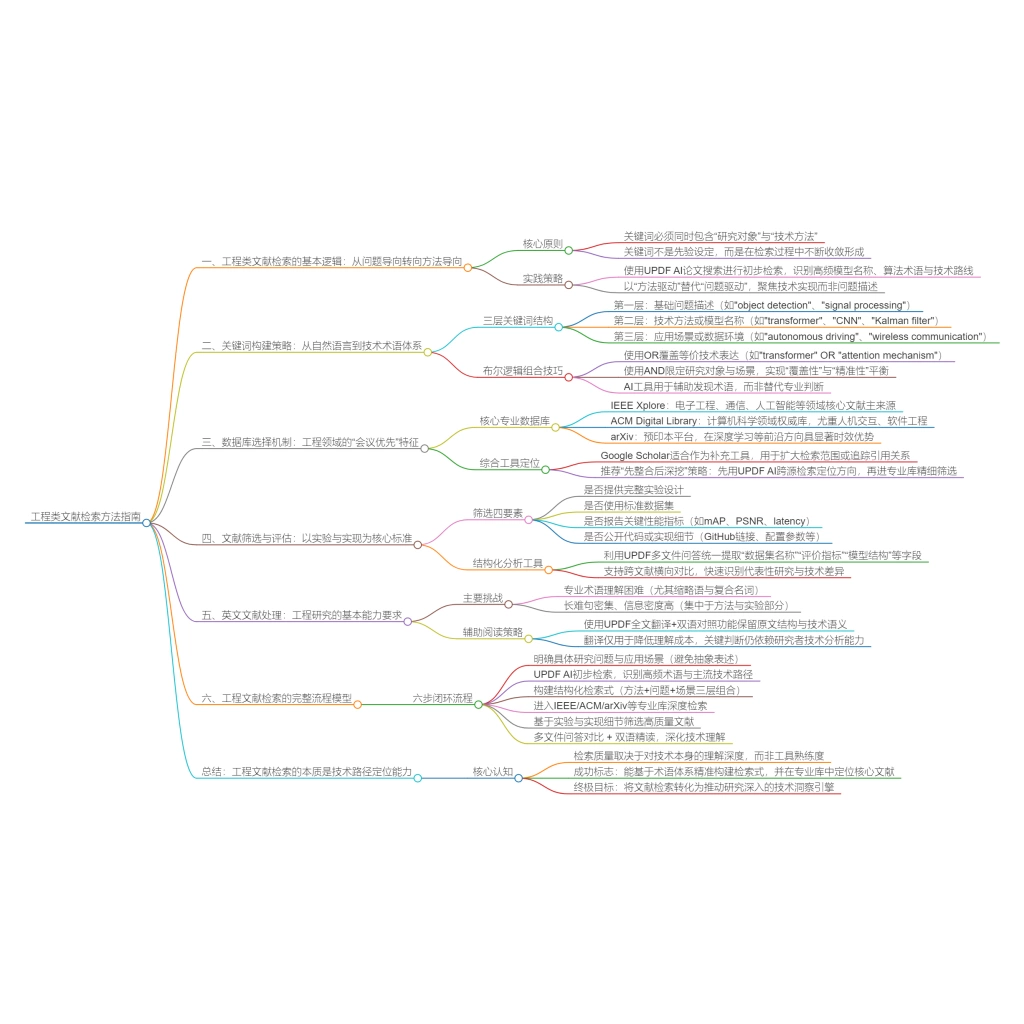
一、工程类文献检索的基本逻辑:从问题导向转向方法导向
在多数社会科学或医学研究中,文献检索往往以研究问题为起点,即通过描述问题本身来构建关键词。然而在工程领域,这种方式存在明显局限,因为大量研究并不是围绕“问题描述”展开,而是围绕“技术实现”展开。
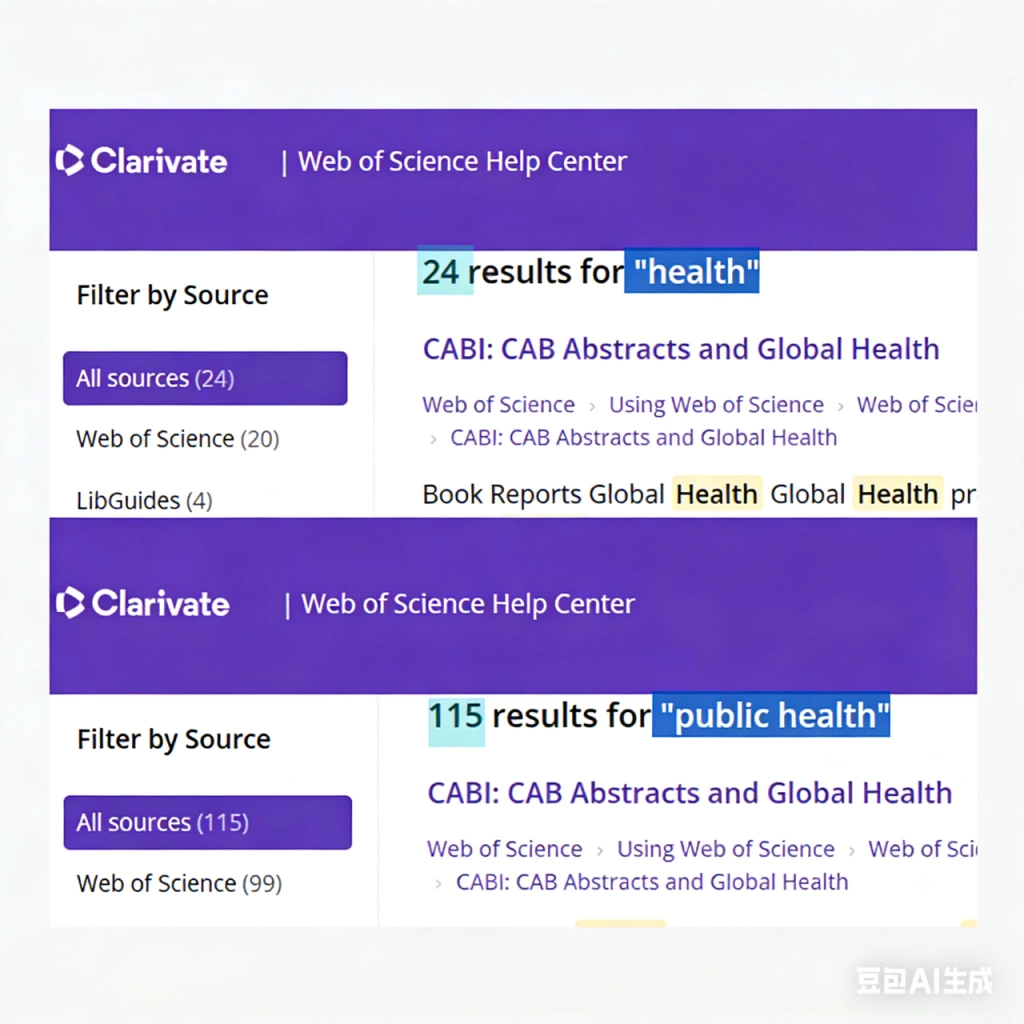
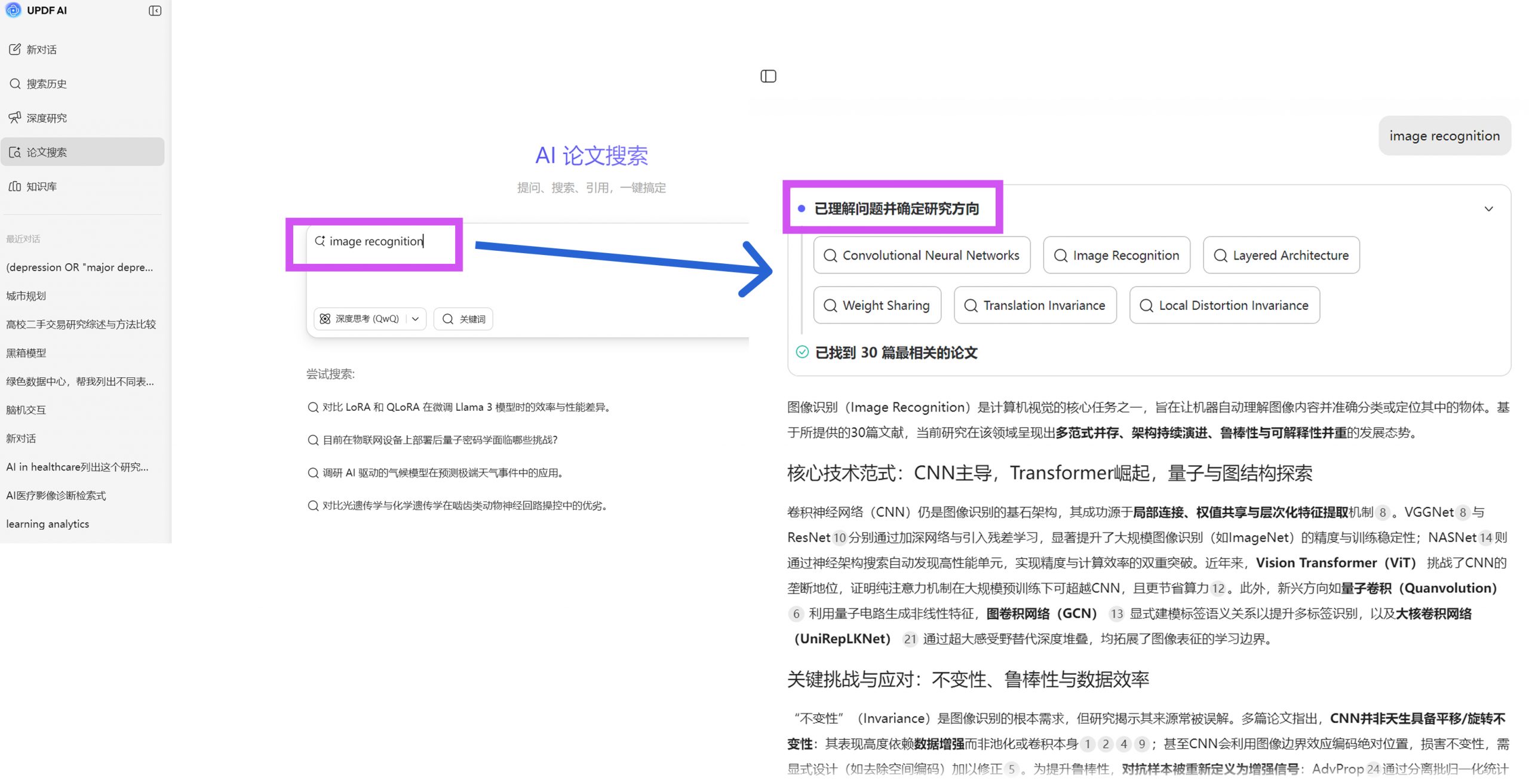
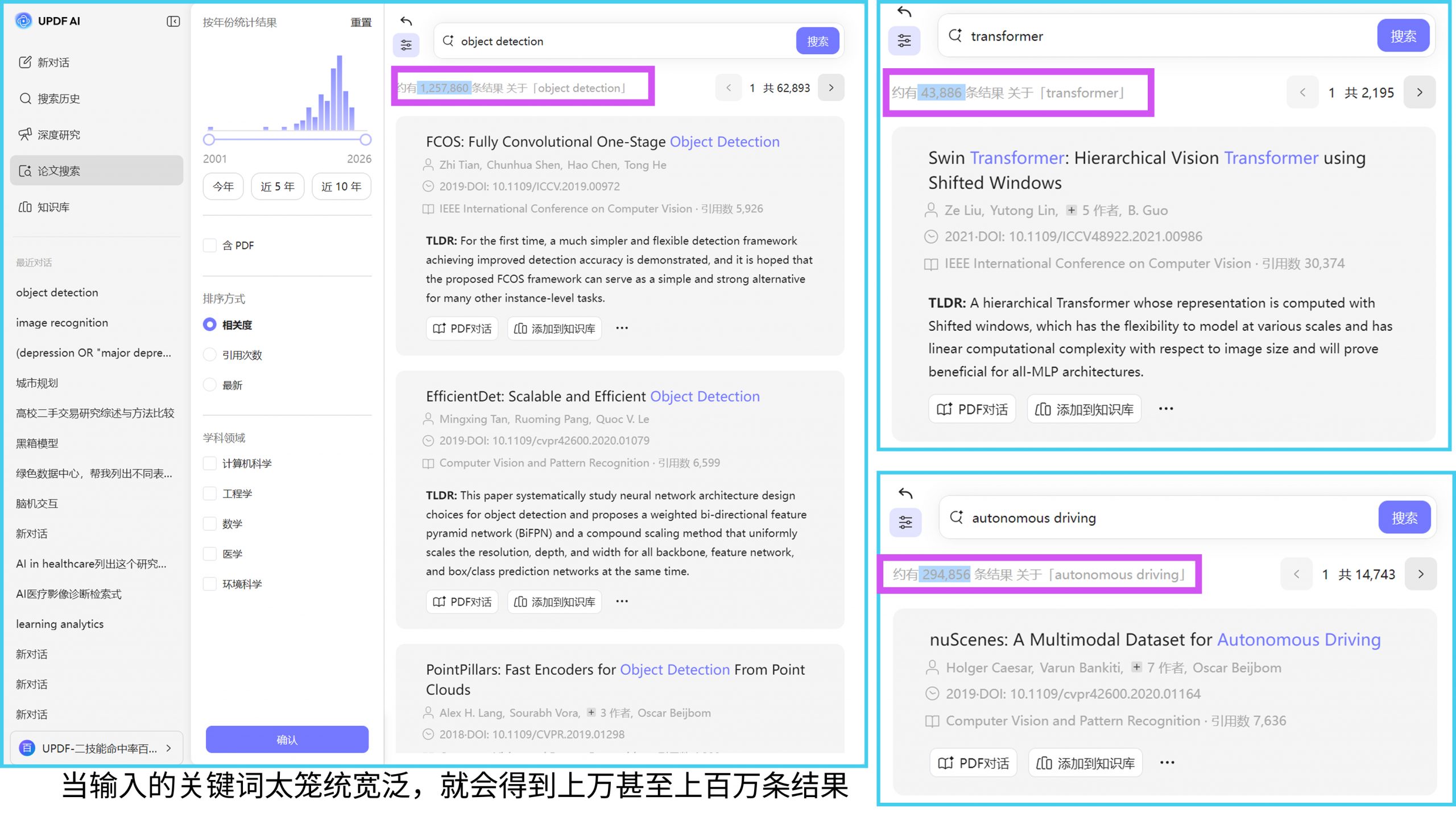
例如,在计算机视觉领域,如果仅使用“image recognition”作为检索关键词,得到的结果将高度分散,既包括传统方法,也包括深度学习模型,还可能包含应用性较弱的研究。相比之下,如果将关键词扩展为“convolutional neural network AND image recognition”,则可以显著提升结果的相关性与技术一致性。由此,我们可以总结出工程检索的核心原则是关键词必须同时包含“研究对象”与“技术方法”。
在实际操作中,可以通过 UPDF AI 的论文搜索对一个宽泛主题进行初步检索,从返回结果中观察高频出现的模型名称、算法术语以及技术路线。这一过程的关键并非筛选文献,而是识别该领域的“主流技术表达方式”,并据此反向构建更精确的检索式。
换言之,在工程领域,关键词并不是先验设定,而是在检索过程中不断收敛形成的。
二、关键词构建策略:从自然语言到技术术语体系
工程类文献检索的第二个关键点,在于术语精度控制。与医学领域依赖主题词体系不同,工程领域虽然缺乏统一的控制词表,但其术语具有高度标准化特征,尤其是在算法名称与模型结构方面。
一个成熟的关键词体系通常包含三个层次:
第一层是基础问题描述,例如“object detection”“signal processing”等。
第二层是技术方法或模型名称,例如“transformer”“CNN”“Kalman filter”等。
第三层是应用场景或数据环境,例如“autonomous driving”“wireless communication”等。
在实际检索中,这三个层次需要通过布尔逻辑(AND / OR)进行组合,从而构建结构化检索式。例如(”transformer” OR “attention mechanism”)AND “object detection” AND “autonomous driving”,这一检索式的优势在于,它不仅覆盖了不同技术表达方式(通过OR扩展),同时通过AND限定了应用场景,从而实现“覆盖与精准”的平衡。
在这一阶段,AI工具的价值在于辅助发现术语,而非替代判断。通过UPDF AI 的论文搜索观察文献标题与摘要中的高频词,可以快速补全关键词体系,避免遗漏关键技术路径。
三、数据库选择机制:工程领域的“会议优先”特征
在数据库选择方面,工程领域与其他学科存在显著差异。许多新手倾向于依赖综合数据库,例如Google Scholar,但在工程研究中,这种方式往往难以获取最前沿成果。这是因为工程领域的核心研究,尤其是在计算机科学与电子工程方向,通常首先发表在高水平会议(Conference),而非期刊。
因此,工程文献检索必须优先考虑以下数据库:
- IEEE Xplore:覆盖电子工程、通信、人工智能等领域,是获取工程类核心文献的主要来源之一。
- ACM Digital Library:重点覆盖计算机科学领域,尤其在人机交互、软件工程等方向具有重要价值。
- arXiv:作为预印本平台,收录大量尚未正式发表的最新研究,在深度学习等领域具有明显前沿优势。
相比之下,Google Scholar更适合作为补充工具,用于扩大检索范围或查找引用关系。
在实际操作中,可以先通过 UPDF AI 的论文搜索进行跨源检索,快速定位研究方向与核心论文,再进入专业数据库进行精细筛选。这种“先整合后深挖”的策略,可以显著提高效率。
四、文献筛选与评估:以实验与实现为核心标准
工程类论文的价值评估,与其他学科相比,更强调实验验证与实现细节。因此,在筛选文献时,仅凭标题与摘要往往不足以判断其价值。在实际研究中,很多论文在方法描述上高度相似,但实验结果差异显著。如果缺乏系统对比,很难判断哪一方案更具优势。
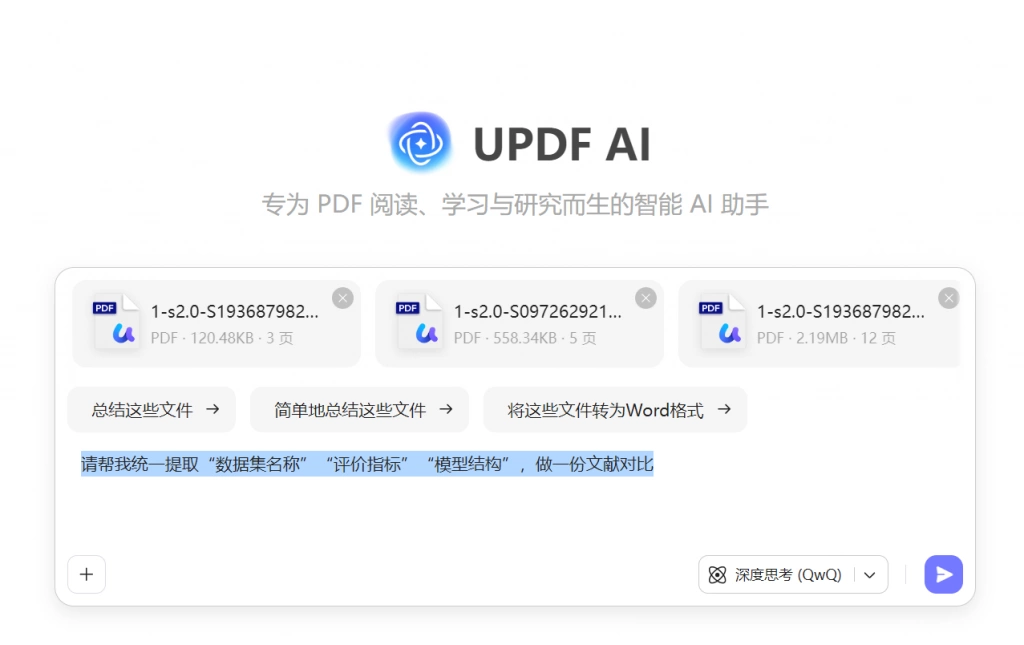
在这一阶段,可以利用UPDF的多文件问答对多篇论文进行结构化提问,例如统一提取“数据集名称”“评价指标”“模型结构”等信息。这种方式可以在较短时间内完成跨文献对比,从而识别出真正具有代表性的研究。
五、英文文献处理:工程研究的基本能力要求
工程领域的核心研究几乎全部以英文发表,这不仅体现在期刊与会议,也体现在技术文档与开源项目中。因此,文献检索与阅读不可避免地依赖英文环境。
在实际过程中,研究者常面临两个问题:一是专业术语理解困难,二是长句结构影响阅读效率。尤其是在方法与实验部分,文本往往高度压缩,信息密度极高。
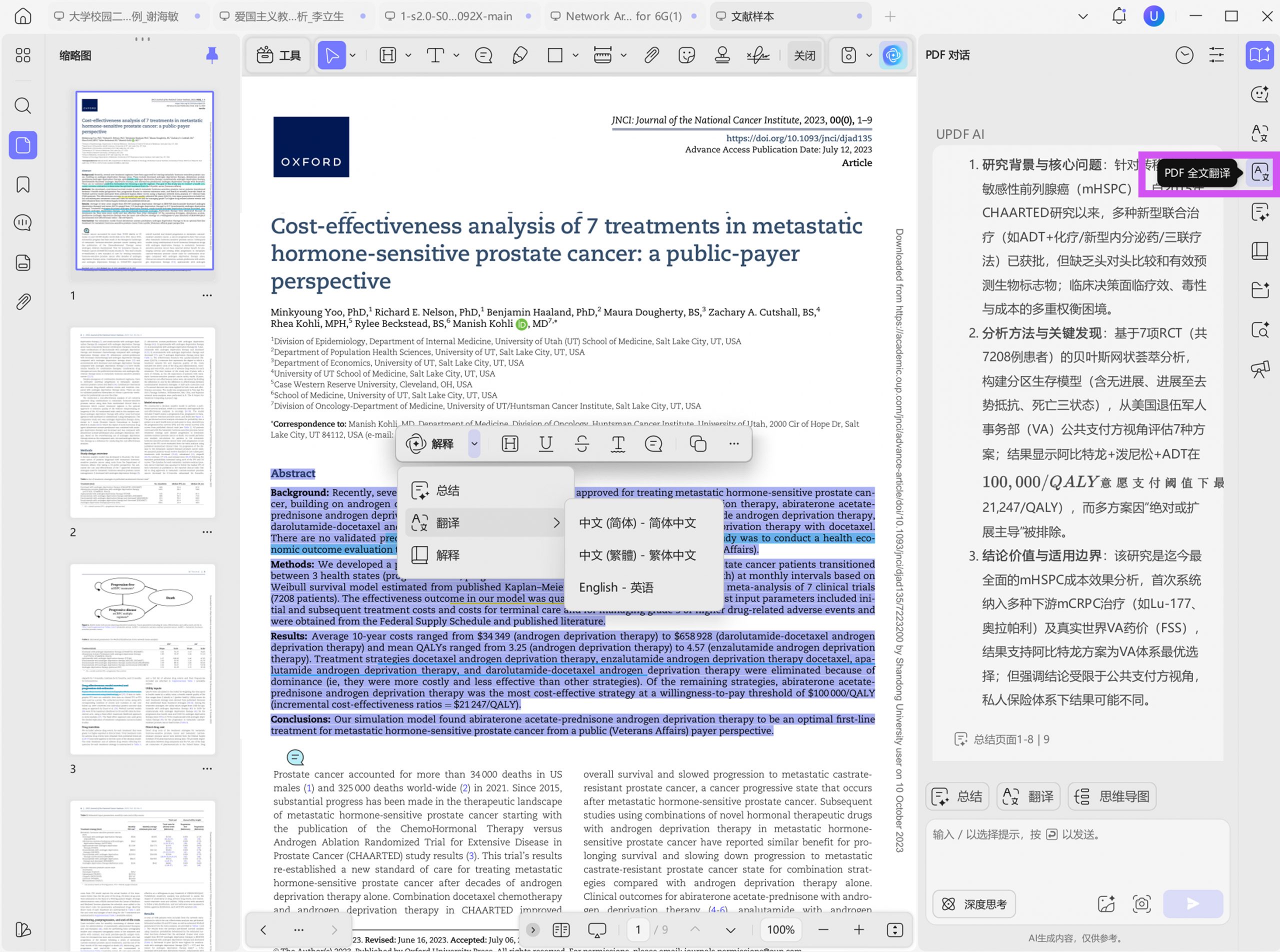
为提高阅读效率,可以通过UPDF文档阅读中的全文翻译与双语对照进行辅助理解。这种方式能够在保留原文结构的基础上提供语义解释,尤其适用于复杂算法描述与实验分析部分。
需要强调的是,翻译工具的作用在于降低理解成本,而不是替代技术判断。关键仍在于研究者是否能够基于内容进行分析与推理。
六、工程文献检索的完整流程模型
综合以上分析,可以构建一套工程类文献检索流程:
- 首先,明确研究问题与应用场景,避免使用过于抽象的描述。
- 其次,通过AI论文搜索进行初步检索,识别高频术语与技术路径。
- 随后,构建结构化检索式,结合方法、问题与应用场景进行组合。在此基础上,进入IEEE、ACM等专业数据库进行深度检索。
- 完成检索后,根据实验设计与实现细节筛选文献。通过多文件问答进行跨文献对比,识别核心研究。
- 最后,结合翻译工具进行深入阅读与理解。
这一流程的关键在于,每一步都围绕“技术路径”展开,而不是简单的信息收集。
常见问题
- 工程类文献为什么更看重会议论文?
因为前沿研究通常首先发表在会议。
- 关键词为什么要包含方法?
工程研究以技术实现为核心,仅描述问题难以筛选结果。
- 是否可以只用Google Scholar?
不建议,缺乏对会议论文的精确筛选能力。
- 如何快速判断论文价值?
重点查看实验设计、数据集与性能指标。
总结
从整体来看,工程类文献检索的核心,并不在于工具或数据库,而在于是否能够准确描述技术问题,并在复杂的研究空间中定位主流方法。
当你能够基于技术术语构建关键词体系,并在专业数据库中定位核心文献,再通过跨文献对比理解方法差异时,文献检索将不再是低效重复劳动,而成为推动研究深入的重要工具。在这一过程中,工具所提供的只是效率提升,而真正决定检索质量的,始终是研究者对技术本身的理解深度。