AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













在科研过程中,很多人真正卡住的第一步,并不是“不会读论文”,而是连检索关键词都不知道该怎么写。研究问题在脑子里也许已经相对清楚了,但一旦要把它转化为可以在数据库中使用的检索表达,困难就会立刻出现。中文概念似乎容易理解,换成英文却不知道该用哪个术语。同一个问题换了几种说法,得到的结果数量和质量差异巨大。有时你明明觉得这个方向一定有很多研究,但输入关键词后,结果却要么很少,要么完全不相关。
也正因为如此,越来越多研究者开始尝试用AI来辅助生成关键词。只要输入一个研究主题,AI就能快速给出一串英文表达、同义词、近义词,甚至还能附带几个相关方向。表面上看,这确实能大幅减少试错成本,也让关键词构建这件事不再那么痛苦。
但AI生成的检索关键词到底靠不靠谱? 如果直接拿来用,会不会把检索方向带偏? 如果不直接拿来用,那AI在这个环节里真正有价值的地方又是什么?
这篇文章想解决的,其实不是一个工具问题,而是一个检索方法问题。也就是说,我们真正要讨论的,不是“AI好不好用”,而是在构建检索关键词时,AI究竟适合扮演什么角色,研究者又该怎样使用它,才能既提高效率,又尽量避免翻车。
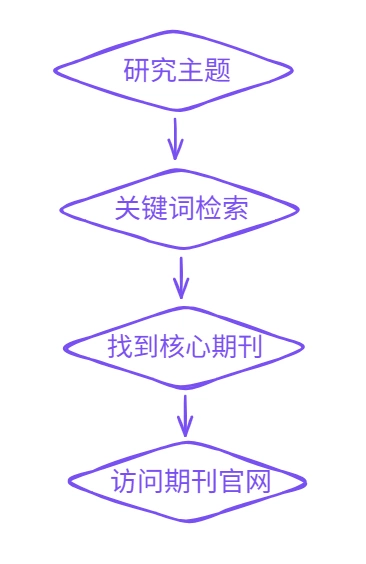
一、为什么关键词生成本来就不是一件简单的事?
很多新手会以为,关键词检索就是把研究主题翻译一下,换成英文,输入数据库就行。真正开始操作之后才会发现,事情远没有这么简单。
首先,学术研究中的同一个概念,往往存在多种表达方式,而且这些表达并不一定是简单同义词替换。有些词来自不同学科传统,有些词反映不同理论立场,还有一些词则对应不同研究场景。也就是说,你以为自己只是在换词,实际上可能已经换了一个研究语境。
其次,检索关键词不仅决定你能不能找到文献,还决定你会找到哪一类文献。关键词过于宽泛,数据库返回的大量结果会把真正有价值的论文淹没掉;关键词过于具体,则可能让很多相关研究直接消失在检索结果之外。更麻烦的是,这两种情况并不会提前通知你,你只能通过不断试错来判断:现在这组关键词到底是太宽了,还是太窄了。
还有一点常常被忽略:文献检索从来不是“找到一个最正确的词”,而是建立一套关键词体系。真正成熟的检索式,通常并不是单个词,而是一组经过组织和筛选的表达。这些表达之间有主次之分,也有不同的覆盖范围。换句话说,关键词构建本质上是一种策略,而不是翻译动作。
正因为这个环节本身就复杂,所以AI看上去才会显得格外诱人:它似乎能迅速把你从“想不到词”的困境里解救出来。但也正因为这个环节复杂,AI一旦用得不对,风险也会被放大。
二、AI 在关键词生成上的真正优势是什么
要判断AI是否靠谱,先要看它到底擅长什么。 从实际使用来看,AI在关键词生成上的最大优势,并不是“帮你给出标准答案”,而是快速扩展表达空间。
当研究者自己想关键词时,思路通常会被原始问题绑得很紧。你会习惯性地围绕自己已经熟悉的表达来搜索,于是检索范围往往被局限在很窄的一条路径里。AI则不同。它能在短时间内给出一组可能的表达方式,包括同义词、相关术语、不同学科中的替代表达,甚至一些你一开始没想到的相邻概念。
这一点在跨学科研究里尤其有价值。很多时候,问题不是你不会检索,而是你根本不知道另一个学科怎么说这件事。AI能做的,恰恰是把这些可能的表达先铺开,让你看到一个更大的语言空间。
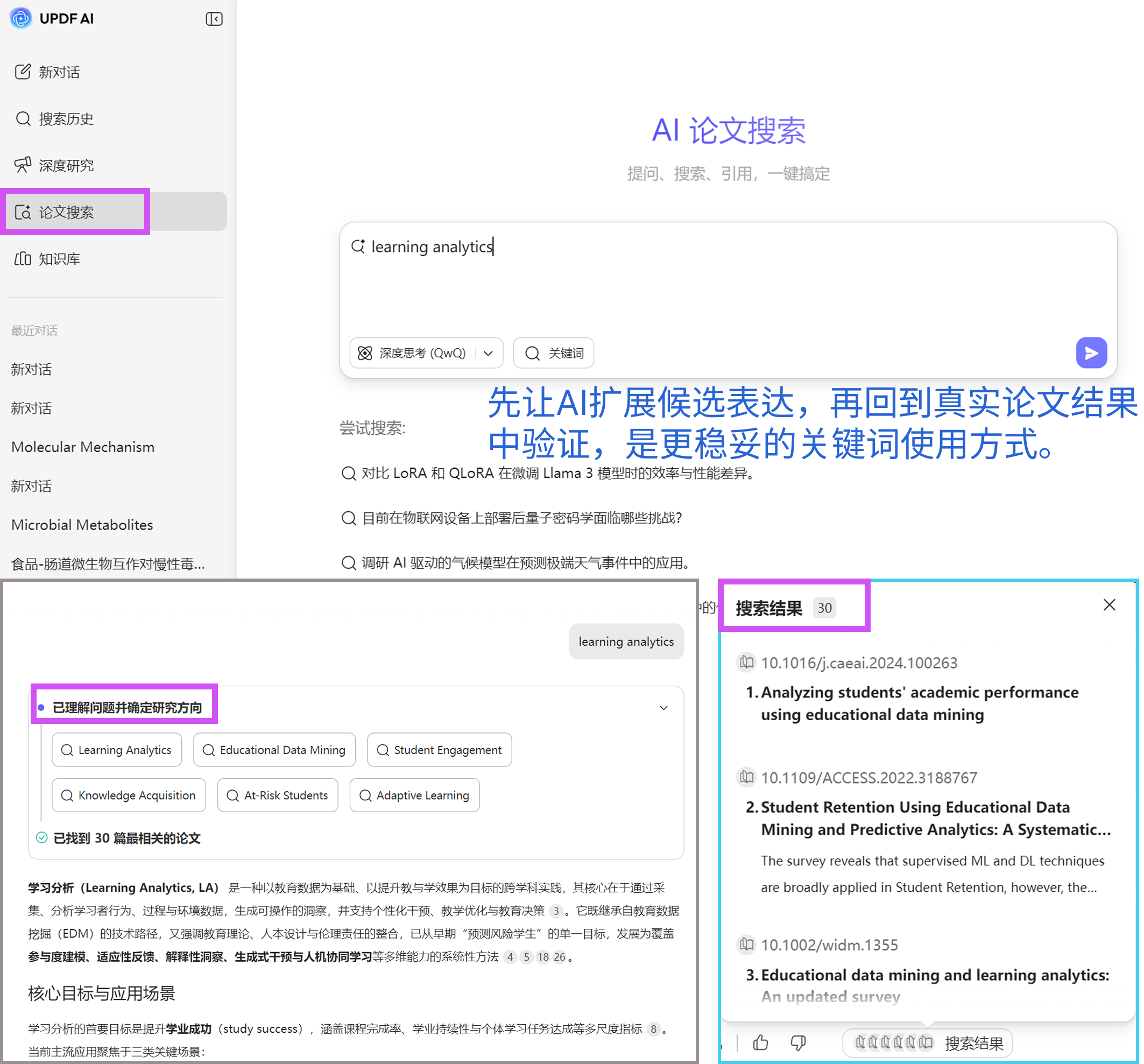
如果结合AI论文搜索来使用,这种优势会更明显。因为真正有价值的关键词,不只是语言上“看起来合理”,更重要的是能否在真实论文中出现。通过搜索结果,你可以很快看到某个术语背后到底对应哪类研究、哪些作者、哪些研究方向。也就是说,AI不只是帮你“想词”,还可以帮你把词放回真实文献环境里验证。
所以,从方法论角度讲,AI在关键词阶段最适合扮演的角色,其实是候选表达生成器,而不是最终检索式的自动生产器。
三、AI 生成关键词为什么会翻车
如果AI在扩展表达方面这么有用,为什么很多人一用就翻车?原因通常不是AI完全没价值,而是使用方式出了问题。
第一种最常见的错误,是直接复制使用。 也就是说,AI生成了一长串词,你觉得看起来都挺像那么回事,于是全部塞进检索式里。结果很可能有两种:要么结果多到不可控,要么方向直接跑偏。因为AI给出的词里,往往既有核心表达,也有边缘相关词,甚至可能混入一些语义相近但学术场景不同的表达。如果不加筛选,检索式几乎必然失控。
第二种错误,是把AI输出当成“专业术语清单”。
事实上,AI生成的表达未必都符合某个具体学科的学术用语习惯。有些词在一般语义上没问题,但在专业文献里并不是常用检索入口。如果直接拿去用,得到的结果可能不稳定,甚至误导你对领域结构的判断。
第三种错误,是关键词只做“扩展”,不做“收敛”。
有些研究者在使用AI之后,检索式越写越长,觉得自己覆盖越来越完整。实际情况往往相反:词越多,噪音越大,后期筛选成本也越高。真正高质量的检索式,通常不是词越多越好,而是经过验证之后,保留最有效的那几组表达。
说到底,AI之所以会让关键词翻车,不是因为它生成不了词,而是因为研究者没有建立“生成—验证—收敛”这个完整过程。
四、正确用法是先生成,再验证,再收敛
如果想把AI用在关键词阶段,又尽量不翻车,一个相对稳妥的流程通常是三步。
第一步,先用AI做候选生成。 这一步的目标很明确:不是要立刻得到最终检索式,而是把可能的表达先铺开。你可以输入研究问题、研究对象或一个较宽泛的主题,让AI列出相关术语、同义词、替代表达和相邻概念。这个阶段要做的是“开”,也就是扩大语言空间。
第二步,把这些词放回文献环境里做结果验证。 这一步不能停留在语言层面,而必须进入真实检索。更具体地说,你需要把候选词逐个或分组放入AI论文搜索中,看它们到底能检索出什么样的文献。这里真正要观察的不是结果数量,而是结果质量。比如:能不能检索到本领域经典论文?结果是否集中在同一研究方向?有没有大量明显无关的文献混进来?
第三步,根据结果做关键词收敛。 经过验证之后,你会很快发现,有些词虽然看起来漂亮,但结果不稳定;有些词虽然不那么“高级”,却能精准命中核心研究。这个时候,就要删掉低效表达,保留最有效的3到5组核心词。最终形成的,不是一长串堆砌出来的表达,而是一套可以持续复用、并且逻辑清楚的检索式。
这三步里最关键的,是第二步。因为AI最擅长的是给你“可能性”,而真正让关键词变靠谱的,是你有没有通过文献结果完成验证。
五、怎么判断一个关键词到底“靠不靠谱”
很多人以为,关键词是否靠谱主要看“我喜不喜欢这个表达”或“它听起来专不专业”。但在检索实践里,一个关键词是否有效,实际上有更客观的判断标准。
第一个标准,是它能不能找到该领域的代表性论文。 如果一组关键词连本领域最常见、最有影响力的论文都找不到,那基本可以判定它有问题。无论它在语言上多漂亮,只要不能触达核心研究,就不适合作为主检索词。
第二个标准,是检索结果有没有明显的主题集中性。 靠谱的关键词往往会把结果收敛在几个相对一致的研究群体里。如果结果横跨多个完全不同的学科或问题域,而且无关结果很多,说明关键词太宽或语义偏移。
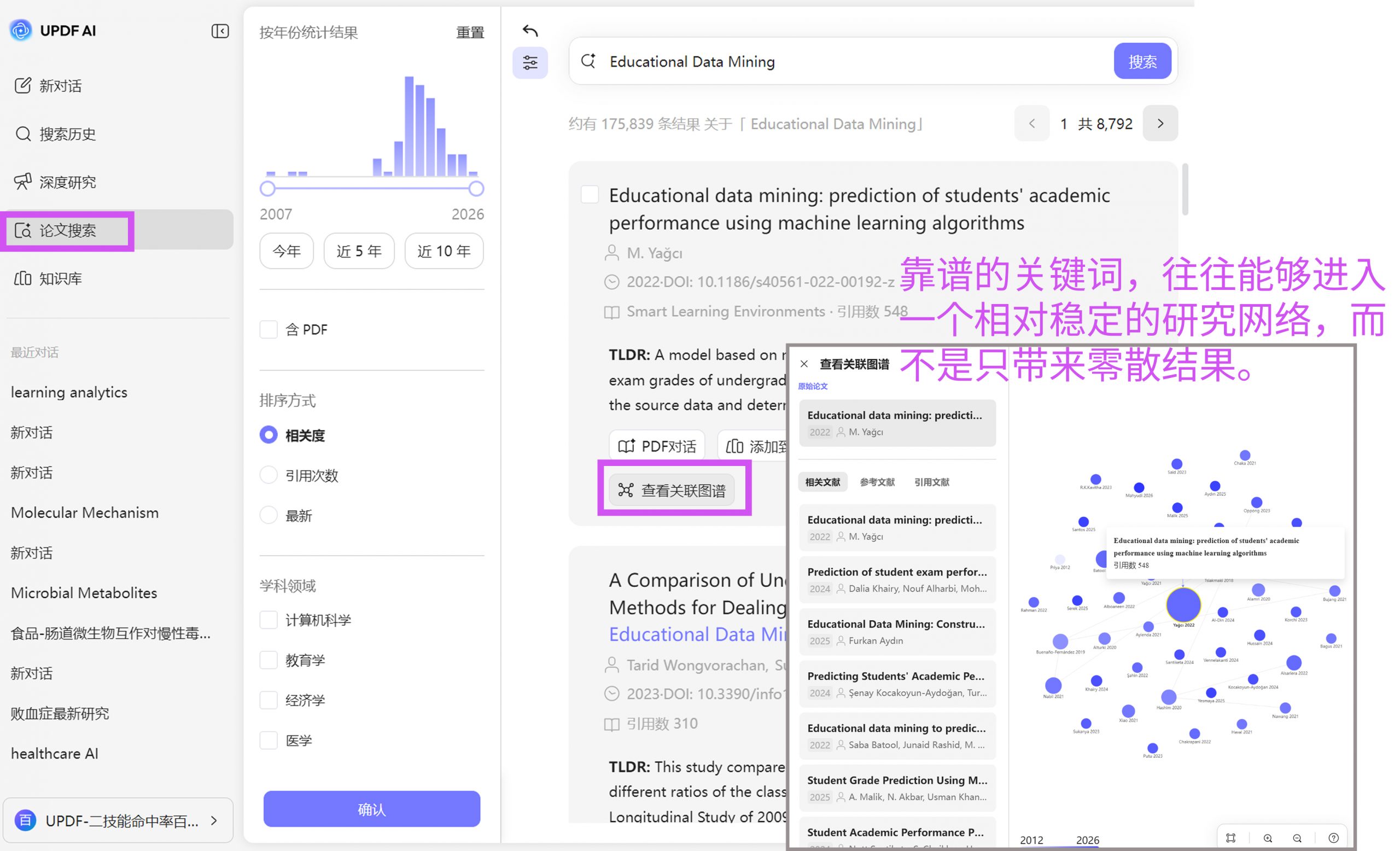
第三个标准,是它能否在后续扩展时形成稳定路径。 也就是说,一组好的关键词,不仅能找到初始文献,还能通过这些文献继续扩展出更完整的研究网络。这时候,文献关系图谱就很有帮助。你可以观察用某组关键词找到的论文,在引用网络中是否形成相对稳定的研究结构。如果能够清晰看到几个核心节点和分支方向,说明这组词的质量相对较高;如果图谱上结果零散、关联弱,那就要怀疑关键词本身是否偏了。
所以,判断关键词靠不靠谱,最根本的标准并不是“词对不对”,而是它能不能帮你进入一个真实存在的研究网络。
六、别只让 AI 生成词,要让文献反过来修正词
更成熟一点的做法,其实不是一直让AI“往前生成”关键词,而是让已经找到的文献反过来“修正”关键词。
具体来说,当你已经有了一批初步相关的论文之后,最有价值的信息往往不再来自AI本身,而来自这些论文真实使用的语言。你可以观察它们的标题、摘要、关键词栏、方法描述,看看同一个研究问题在真实文献中到底是怎么被表达的。
这时候,AI可以帮助你从这批文献中总结高频表达、识别同一概念的不同说法,并快速比较这些表达对应的研究差异。这样形成的关键词体系,会比“从零生成”更贴近学术语境,也更适合后续迭代。
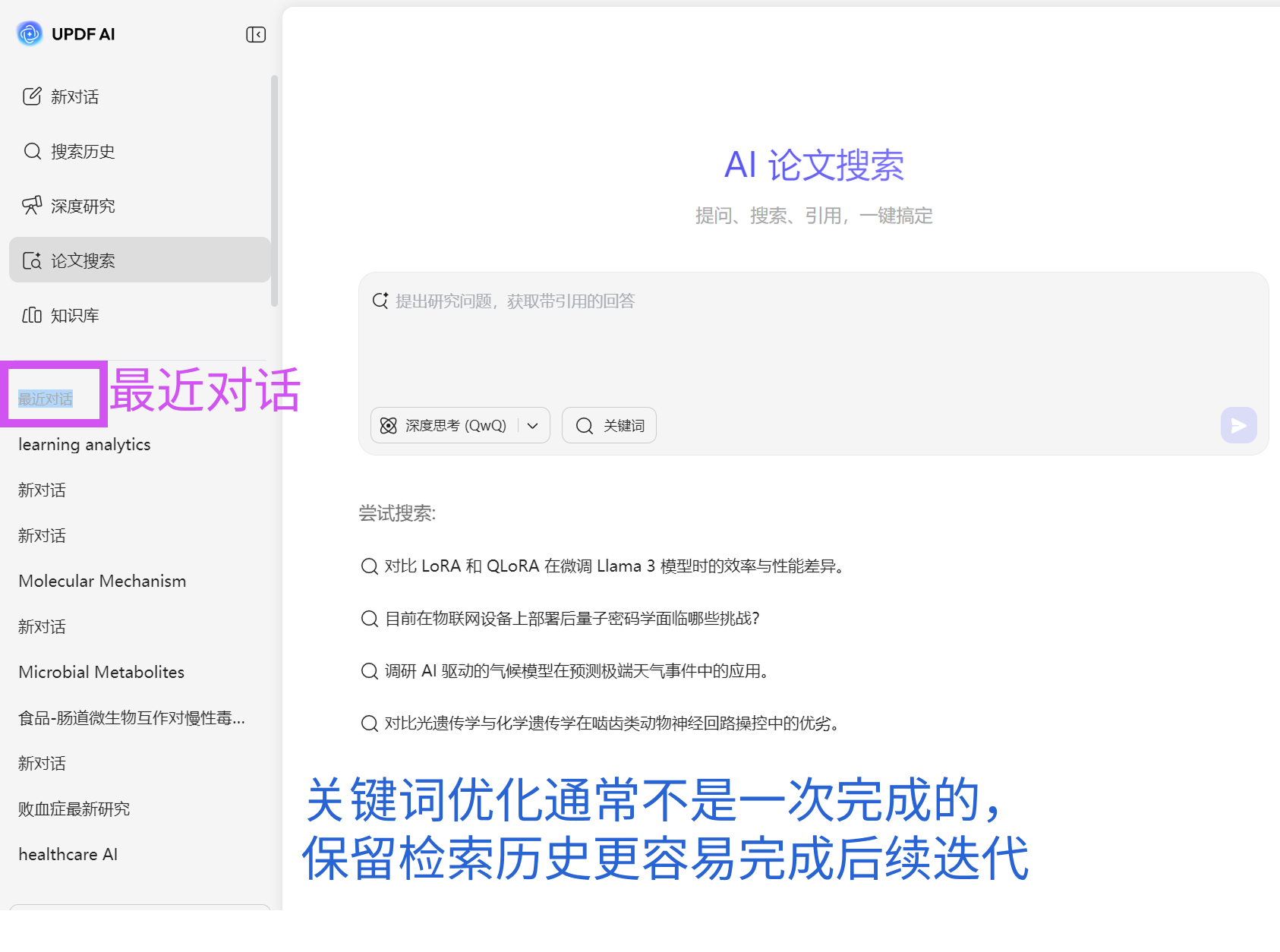
如果结合最近对话/搜索历史来使用,这个过程还会更稳定。因为关键词优化通常不是一次完成的,而是一个逐步调整的过程。把每次试过的表达、对应的结果印象、有效或无效的判断保留下来,后面再回看时,你会很清楚自己是怎样一步步把检索式修到更稳定的。
换句话说,真正成熟的关键词策略,不是一次性交给AI,而是让AI、真实文献和自己的判断,三者不断互相修正。
七、一个更稳妥的关键词工作流
把前面的内容压缩成一个可执行的方法,其实可以形成一套很稳妥的工作流。
先让AI围绕研究主题生成一组候选表达。 然后把这些表达放进真实检索中测试结果。 再结合文献关系图谱判断这些关键词找到的文献是否形成稳定研究网络。 接着保留高效表达,删除噪音词,形成第一版检索式。 最后把试过的关键词和结果印象保留在搜索历史 / 最近对话中,后续持续修正。
这套流程的核心,不是“让AI帮你决定关键词”,而是把AI纳入一个可验证、可迭代、可修正的检索过程里。
这样一来,AI既能发挥它在扩展表达上的优势,又不会因为直接替你做决定而把方向带偏。
常见问题
- AI生成的关键词能不能直接拿来检索? 不建议直接使用。更稳妥的做法是先把它当作候选表达,再通过真实检索结果验证。
- 关键词是不是越多越好? 不是。关键词太多会增加噪音,真正有效的是经过筛选和收敛后的核心表达。
- 如何判断一组关键词是否真的靠谱? 看它能否命中领域代表性论文,结果是否集中,以及是否能形成稳定的研究网络。
- AI最适合用在关键词阶段的哪个环节? 最适合用于扩展表达空间和提供候选词,而不是替代最终决策。
总结
AI辅助生成检索关键词当然可以用,但它真正靠谱的前提,从来不是“它比人更懂关键词”,而是研究者知道该把它放在哪个环节。 如果你把AI当作最终答案提供者,检索很容易翻车;如果你把AI当作候选表达生成器,再通过真实文献结果去验证和收敛,它就会成为一个非常高效的加速工具。所以,最稳妥的做法是先生成,后验证,再收敛,最后迭代。
真正好的关键词,不是一开始就“灵光一现”想到的,而是在不断比较、修正和淘汰中慢慢建立起来的。AI的价值,也正在于它能把这个试错过程变得更快,但它无法替代你做最后的判断。