AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













真正开始写方法部分或实验设计的时候,很多人已经读了不少论文,也大概知道这个领域在研究什么,但一到“实验怎么搭”“该用什么数据集”“别人是怎么在这个数据集上做对比”的时候,信息还是不够用。
这种不够,不是因为论文数量太少,而是因为你读到的文献太分散。有的论文研究问题相近,但数据集完全不同;有的论文方法看起来很先进,却并没有在你准备使用的数据集上做实验;还有一些文章虽然提到了某个数据集,但实际上只是把它放在相关工作里顺带提一句,正文根本没有真正展开。
所以,当你进入论文写作中最讲究可比性、可复现性和实验逻辑的阶段时,不但要只按主题找论文,还要按数据集找论文。因为在很多研究领域里,尤其是计算机、人工智能、医学影像、自然语言处理、推荐系统、教育数据挖掘这些方向,数据集并不只是“拿来跑实验的素材”,它往往本身就是一个研究共同体的组织中心。围绕同一个数据集,会聚集起一整批论文。当你开始按同一数据集去找论文时,你看到的已经不再是一堆散乱的研究,而是一个更接近真实研究现场的“方法竞争场”。 这对于写实验部分尤其重要。这篇文章就想讲清楚为什么要从数据集出发找论文,怎么找,找到之后又该怎么筛、怎么比、怎么整理。
一、为什么只按主题找论文,到了实验阶段往往不够用?
很多研究者在文献检索的前半程,习惯的是按主题词搜。
比如你研究图像分类,就搜 image classification;你研究医学影像分割,就搜 medical image segmentation;你研究学习分析,就搜 learning analytics。这样的做法当然没问题,因为在研究初期,你首先要做的是看清楚这个领域在讨论什么、有哪些核心问题、常见的方法路径是什么。
但一旦进入实验设计阶段,问题就会发生变化。
你不再只是想知道“这个领域研究什么”,而是开始关心“别人到底在哪个数据集上做过实验”“我准备使用的数据集上有哪些代表性方法”“同一套 benchmark 下,哪些论文才真正具有可比性”。
这时候,如果还只继续按主题搜,往往会遇到三个典型问题。
第一,结果太散。 同一个主题下可能有很多论文,但它们使用的数据集完全不同。你读得越多,越容易发现这些论文彼此其实并不在同一个实验语境里。
第二,比较无效。 有些方法看上去效果很好,但如果它并没有在你关心的数据集上做实验,那么它对你自己的实验设计参考价值其实有限。
第三,容易漏掉真正该对比的论文。 很多研究并不会在标题里突出写出你关心的主题词,但它们可能恰恰在同一个数据集上做了非常扎实的实验。如果你只按主题搜,这类文献很容易从你的阅读范围里滑过去。
所以,到了这个阶段,一个更有效的思路是让数据集从“实验材料”变成“检索入口”。
二、同一数据集相关论文,通常包括哪几类?
当你开始围绕某一个数据集找论文时,别急着把所有结果都当成一类。真正有价值的做法,是先理解这些论文可能属于哪些不同类型。
一般来说,围绕同一数据集的研究,大致可以分成四类。
第一类是方法原型论文。 这类论文通常会在该数据集上第一次提出某种有代表性的方法,或者第一次把某一类模型成功跑通。它们不一定是效果最强的,但往往具有“奠基意义”。
第二类是性能改进论文。 这些研究会在同一个数据集上继续优化已有方法,例如改进网络结构、加入新模块、做损失函数设计或调整训练策略。它们在实验写作里很重要,因为很多“对比基线”就来自这一类文章。
第三类是评测 / 分析型论文。 这类研究不一定提出全新方法,但会讨论这个数据集本身的特征、偏差、评价指标或者实验设置。很多人写实验时最容易忽略它们,但实际上,这些论文能帮你避免很多方法比较上的误区。
第四类是迁移 / 应用型论文。 它们可能不是围绕这个数据集本身展开,而是把已有方法迁移到这个数据集上,或者在这个数据集基础上验证某种外部能力。对于扩展阅读来说,这类文章能帮你看清楚这个数据集在更大研究网络里的位置。
也就是说,你要找的并不只是“凡是提到这个数据集的论文”,而是要逐步分辨: 哪些论文适合当方法源头,哪些适合当实验对比,哪些适合当设置参考。
三、先用数据集名称检索数据集
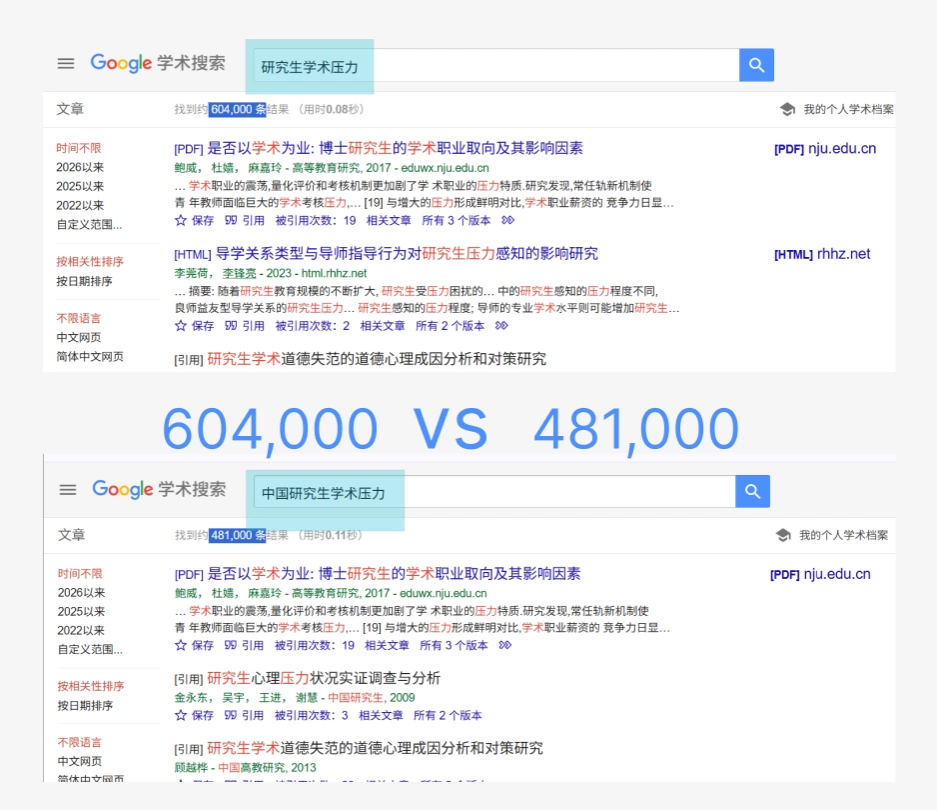
真正开始操作时,最直接的方法当然是用数据集名称本身做检索词。 但这里有个细节非常重要:不要只搜一个最表面的名字,而是要把这个数据集可能的几种写法一起考虑进去。
因为同一个数据集在不同论文里,可能会出现全称、缩写、带年份的版本名、官方名称和社区简称并存。如果你只搜其中一个,很可能会漏掉一部分研究。
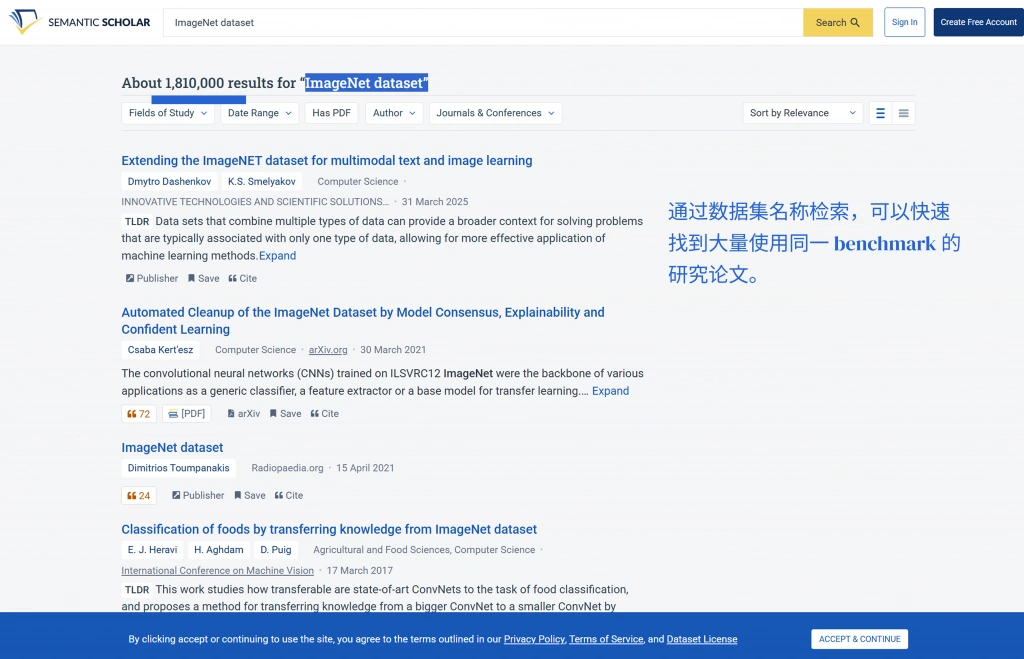
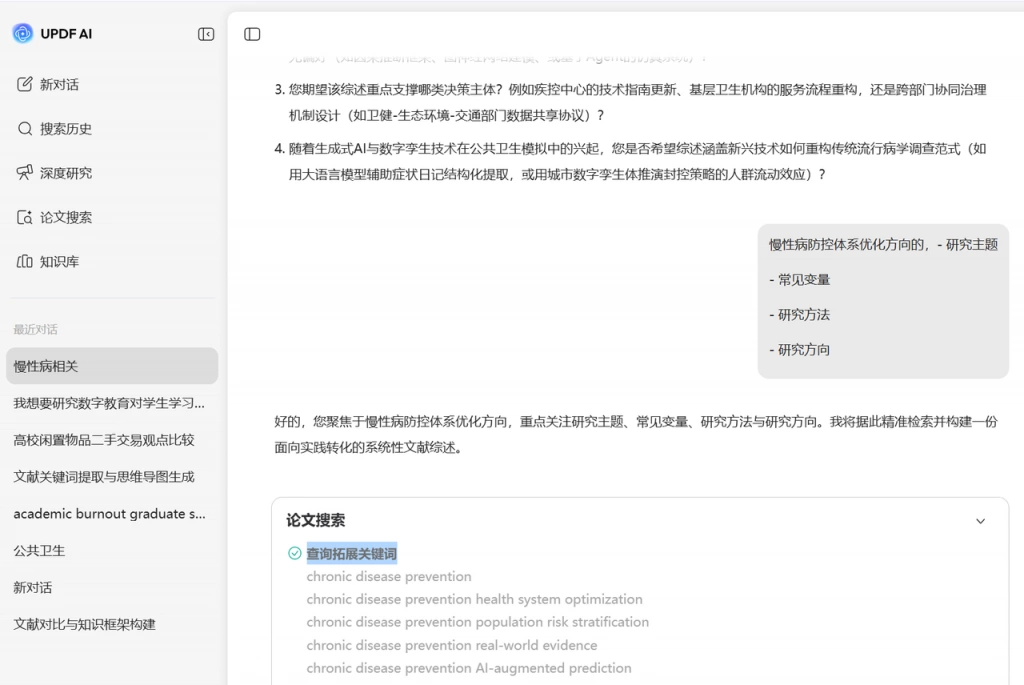
在第一轮检索里,更适合的做法是先把数据集的主名称、缩写、常见写法都列出来,然后围绕它们去看文献覆盖范围。这个阶段,UPDF AI 的论文搜索很适合当一个总入口。你不一定非要在多个平台之间来回切换,而是可以先用数据集名称直接检索,先把“这个数据集到底吸引了哪些研究”拉出来看一遍。
它的价值不在于替代所有数据库,而在于先帮你快速建立一个“数据集相关文献池”。尤其是当你刚接触某个数据集时,这一步能让你尽快知道这个数据集主要在哪些问题上被使用、哪些作者或团队频繁使用它近几年围绕它的研究是在增加还是减少。这个阶段的目标不是立刻精筛,而是先把范围圈出来。
四、怎么筛选数据集?
这一步是很多人最容易忽略的。
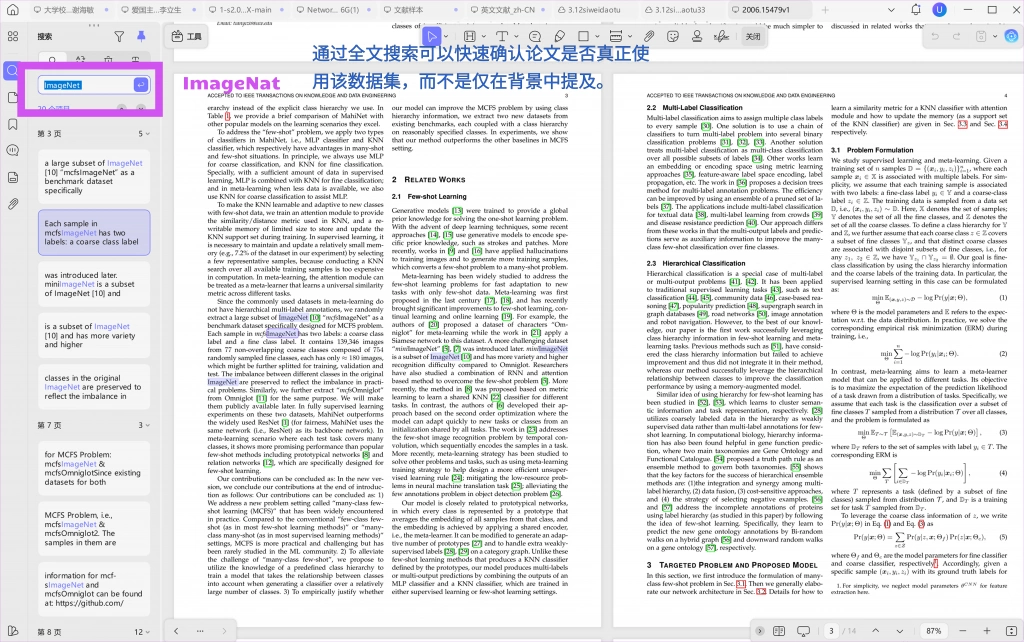
你搜到一批论文之后,不能因为标题或摘要里出现了数据集名称,就默认它们都值得读。现实里经常会出现这种情况:一篇文章在 related work 里提到过这个数据集,或者在背景介绍中顺带说了一句,但正文根本没有真正把它作为实验对象。
如果你不做进一步确认,就很容易把很多“表面相关”的论文误收入自己的文献池,后面一对比才发现,它们并不在同一个实验体系里。
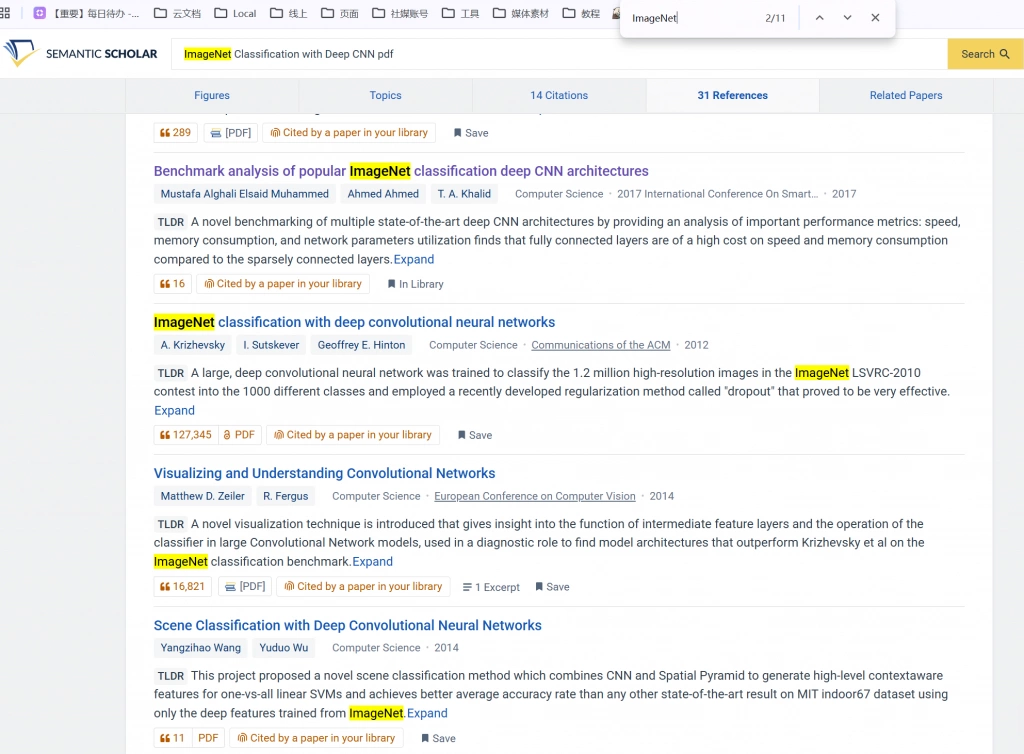
这时候,全文搜索就比只看标题和摘要更有效。 在 UPDF 里,你可以直接对 PDF 做全文搜索,快速定位数据集名称出现的位置。这样你可以非常快地判断:
- 它是只在背景里出现,还是在实验部分高频出现
- 它是辅助数据集,还是主实验数据集
- 它出现在方法说明、实验设置、结果对比还是消融实验中
这一步的意义非常大,因为它能帮你把“提到这个数据集的论文”和“真正围绕这个数据集展开实验的论文”区分开来。对于写实验部分的人来说,后者才是真正值得优先保留的材料。
五、围绕同一数据集,把论文放到一起做比较
当你已经筛出一批确实使用了同一数据集的论文之后,接下来最重要的不是继续盲目扩展,而是开始比较。因为同一数据集论文真正的价值,恰恰体现在“可以放在一起比”。
你需要看的通常不是某一篇文章本身有多强,而是:
- 它用了什么方法
- 它跟之前的方法比,改了哪里
- 它的实验设置有没有变化
- 它的评价指标和别人的是否一致
- 它的结果提升到底是不是在同一个条件下得到的
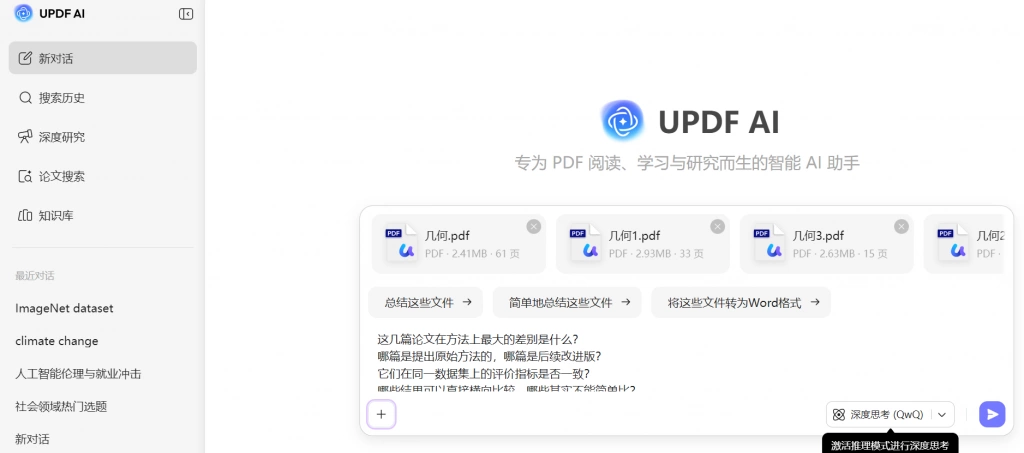
这一步如果靠手动一篇篇翻,非常耗时间,而且很容易看乱。 在这种情况下,UPDF AI 的多文件问答会比单篇阅读更有效。你可以把几篇都使用了同一数据集的论文一起放进去,然后直接问:
- 这几篇论文在方法上最大的差别是什么?
- 哪篇是提出原始方法的,哪篇是后续改进版?
- 它们在同一数据集上的评价指标是否一致?
- 哪些结果可以直接横向比较,哪些其实不能简单比?
这种比较方式特别适合写实验综述、baseline 选择和 related work。因为你不再只是“读到很多论文”,而是在围绕同一个数据集搭建一张方法比较表。
六、按数据集建自己的实验文献池整理
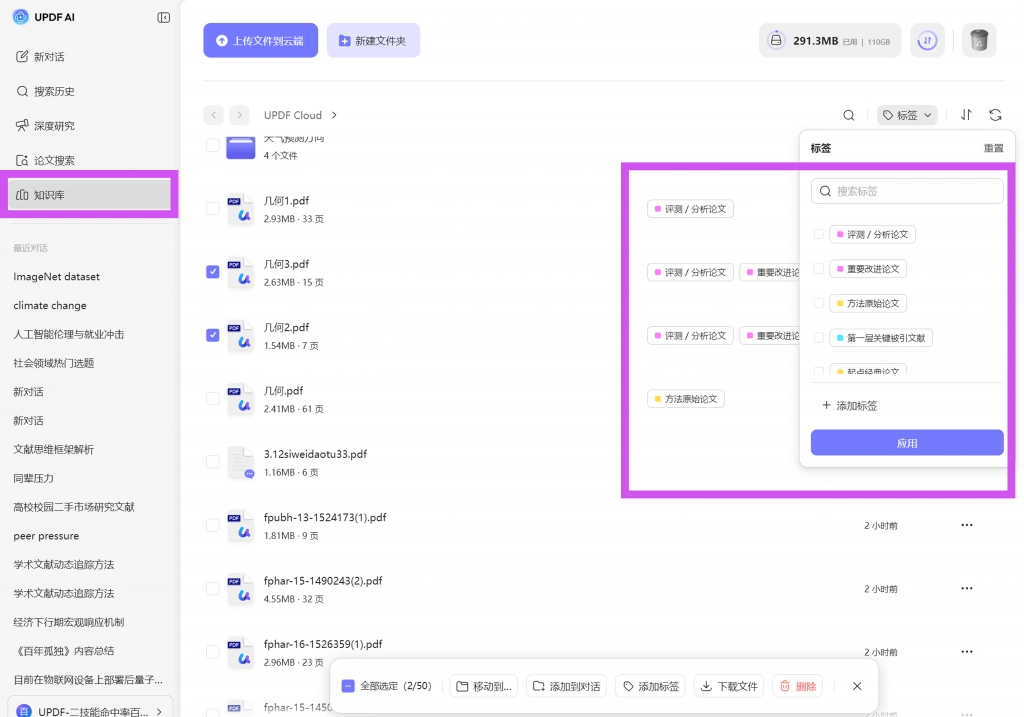
到这里,很多人会再次掉回老问题:论文找到了,也比过了,但文件还是越来越乱。 所以最后一步一定不是“继续下载”,而是整理成自己的实验资料池。最稳妥的做法,是按数据集建立一个长期可更新的分类。
比如你可以围绕某个数据集,分成方法原始论文、重要改进论文、评测 / 分析论文迁移 / 应用论文。
如果你在 UPDF AI 的知识库里继续做这一层整理,会比把 PDF 文件散落在电脑桌面或下载文件夹里高效得多。因为后续你一旦继续补文献、改实验、写综述,都可以回到同一个结构里,而不是重新从零开始。
真正成熟的实验型文献检索,不是“每次写论文都重新搜一遍”,而是逐渐形成自己围绕某一数据集的长期资料库。
常见问题
问题1:为什么要专门找同一数据集的论文?
答:因为只有在同一数据集上做实验的研究,才更适合直接比较方法效果和实验设置。
问题2:只搜数据集名称就够了吗?
答:不够,还要确认论文是否真的把这个数据集用于核心实验,而不是只在正文里顺带提到。
问题3:怎么快速确认一篇论文有没有真正使用该数据集?
答:可以直接用 UPDF AI 的全文搜索定位数据集名称,重点看它是否出现在实验设置和结果部分。
问题4:找到很多同一数据集论文之后,最该做什么?
答:不是继续囤文献,而是尽快比较它们的方法差异、指标设置和结果可比性。
问题5:这类论文后面怎么整理才不容易乱?
答:最好围绕数据集本身建立分类,把方法原型、改进论文和评测论文分开整理。
总结
如何找同一数据集相关论文,本质上不是一个简单的检索问题,而是一个实验准备问题。 你要做的,不只是找到提到某个数据集的文章,而是围绕这个数据集建立一套真正可用于方法比较、实验参考和论文写作的文献体系。
更有效的路径通常是:
- 先用数据集名称做第一轮检索
- 再用全文搜索确认论文是否真正使用该数据集
- 接着把多篇论文放在一起比较方法、指标和实验设置
- 最后按数据集把这些文献整理成自己的长期资料池
如果这个过程中结合 UPDF AI 的论文搜索、全文搜索和 AI 多文件问答,你会更容易从“找到论文”走向“真正看懂这个数据集上的研究格局”。对写方法和实验的人来说,这一步往往不是辅助工作,而是决定你实验设计是否扎实的关键步骤。