AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南












PDF文件是一种常见的文档格式,许多用户在日常工作中可能会遇到需要提取或识别PDF文件中的文字的情况。文字识别技术可以帮助用户将PDF中的文字内容转换为可编辑的文本,方便复制、粘贴或编辑。那么,如何准确高效地操作和应用PDF文字识别技术呢?本文将为您详细介绍相关方法和步骤。
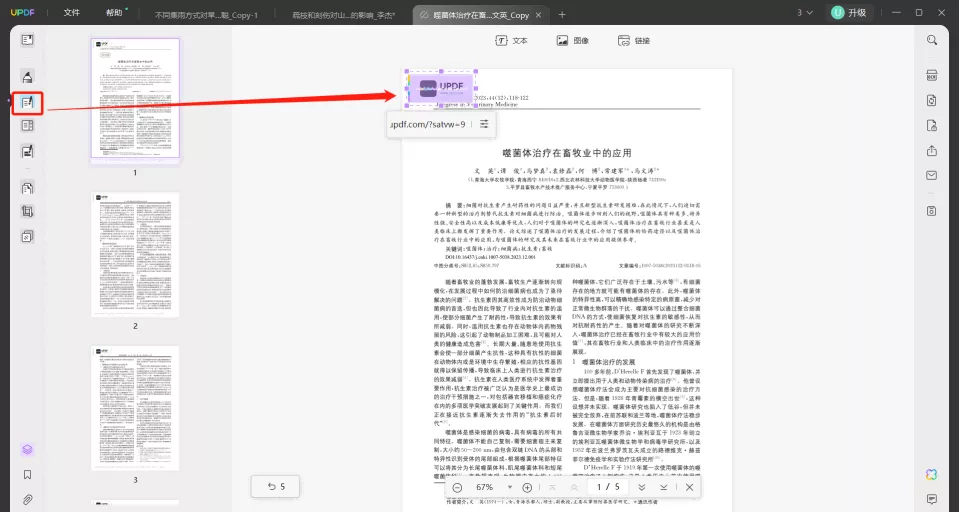
首先,要想操作PDF文字识别技术,需要借助专门的文字识别工具或软件。目前市面上有许多功能强大的PDF文字识别工具,如UPDF、Adobe Acrobat、ABBYY FineReader、Foxit PhantomPDF等,下面我们以UPDF为例,给大家介绍一下PDF文字识别技术的使用步骤。
- 点击本文中的下载按钮,在电脑或者手机上安装并打开UPDF软件。
- 导入需要识别的PDF文件,可以通过“打开”或“导入”功能进行选择。
- 在软件界面中找到文字识别或OCR(Optical Character Recognition)功能;
- 点击文字识别按钮,开始对PDF文件中的文字内容进行识别;
- 等待识别过程完成,软件会将PDF文件中的文字转换为可编辑的文本;
- 根据需要,对识别结果进行编辑、保存或导出。
在进行文字识别时,需要注意以下几点:
- 确保PDF文件清晰可读,文字排版规范,有利于文字识别的准确性;
- 选择合适的文字识别语言,以确保识别的准确性和完整性;
- 在识别大篇幅文本时,建议分段或分页进行识别,以提高效率;
- 针对特定格式的PDF文件(如表格、图片含文字等),可能需要选择对应的文字识别设置。
总的来说,PDF文字识别技术能够帮助用户快速准确地将PDF文件中的文字内容提取出来,为后续编辑PDF文档提供便利。通过选择合适的文字识别工具,并按照正确的操作步骤进行操作,用户可以轻松应用这一技术,提升工作效率和体验。