AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













做文献检索时,很多人都会踩一个隐形坑:明明输入了核心关键词,却总觉得漏了很多相关研究。比如想检索“educational technology”,结果发现文献中还存在“education technology”“educational technologies”“educational technologist”等多种写法,甚至还有“education technological innovation”这类相关表达——只输入一个完整词组,大概率会漏掉大量关键文献。
其实,解决这个问题的关键,就是用好文献检索中的“通配符”,也叫“截词检索”。它能让数据库自动匹配同一词根的多种变化形式,不用反复输入不同词组,就能显著提高检索覆盖率,彻底告别“漏检”烦恼。今天这篇文章,从基础定义到实操技巧,再到避坑指南,手把手教你用好通配符,新手也能快速上手。
一、什么是通配符?
简单来说,通配符就是文献检索中“替代词的一部分字符”的特殊符号,核心作用是匹配同一词根的所有变体形式——不管是词形变化、单复数差异,还是相关衍生表达,只要词根一致,就能被数据库检索到。
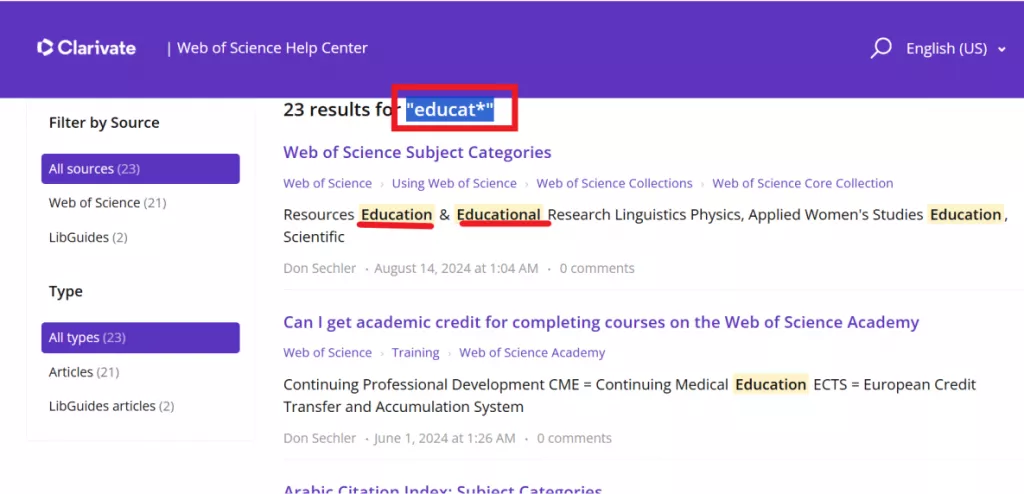
举个最直观的例子:如果你想检索“教育”相关的所有文献,不用分别输入“education”“educational”“educator”“educating”,只要输入词根“educat”,加上通配符“*”,写成 educat*,数据库就会自动返回所有包含该词根的文献,一次性覆盖所有相关词形。
补充说明:在学术检索中,“通配符检索”和“截词检索”本质是同一个概念,截词是目的,通配符是实现截词的工具,日常使用中两者可以互换称呼。
二、常见通配符符号
不同学术数据库(如Google Scholar、Web of Science、Scopus、知网)的通配符符号略有差异,但有3个符号最常用、通用性最强,记住就能应对大部分检索场景,其中星号“*”使用频率最高。
| 符号 | 用途 |
| * | 匹配多个字符 |
| ? | 替代一个字符 |
| $ | 部分数据库的截词符 |
1. 星号(*):最常用,匹配任意长度字符(0个及以上)
这是最基础、最实用的通配符,用于匹配词根后面的任意字符,不管是词尾变化、单复数,还是衍生词汇,都能覆盖。
示例:educat* → 匹配 education(教育)、educational(教育的)、educator(教育者)、educating(教育)等;
示例:student* → 匹配 student(学生,单数)、students(学生,复数)、student’s(学生的,所有格)等。
2. 问号(?):匹配单个字符
用于匹配词根中某一个位置的单个字符,适合词形差异很小的情况(比如单复数变化、拼写差异)。
示例:wom?n → 匹配 woman(女人,单数)、women(女人,复数);
示例:col?r → 匹配 color(美式拼写)、colour(英式拼写)。
3. 美元符号($):匹配0-1个字符(部分数据库适用)
部分数据库(如Scopus)支持美元符号,作用是匹配词根后面0个或1个字符,适合不确定词尾是否有变化的情况。
示例:technolog$ → 匹配 technology(技术,单数)、technologies(技术,复数)。
核心提醒:使用前可简单查看数据库的“检索帮助”,确认该数据库支持的通配符符号,避免因符号不符导致检索失败。
三、3个实用截词技巧
掌握通配符的关键,不是死记硬背符号,而是理解词根结构,根据检索需求灵活运用。以下3个技巧,覆盖大部分学术检索场景,新手可直接套用。
技巧1:词根扩展,覆盖同一概念的不同词形
很多学术词汇存在多种语法变化(如名词、形容词、动词形式),用词根+通配符,能一次性覆盖所有相关词形,避免漏检。
示例:研究“教育技术”,不用分别输入“education technology”“educational technology”,直接用 educat* AND technolog*,就能覆盖:
– education technology(教育技术)、educational technology(教育技术);
– educational technologies(教育技术,复数)、education technological(教育技术的)。
适用场景:研究主题较广、处于文献探索阶段,需要全面覆盖相关文献时。
技巧2:单复数扩展,避免因单复数差异漏检
英文关键词的单复数变化,是最容易导致漏检的原因之一,用通配符能轻松解决这个问题,无需分别输入单复数形式。
示例:检索“学生相关研究”,输入 student*,既能匹配“student(单数)”,也能匹配“students(复数)”“student’s(所有格)”,避免因只输入单复数中的一种,漏掉相关文献。
补充:中文关键词无单复数差异,但部分中文词汇有近义词衍生,可结合OR运算符搭配使用,效果类似。
技巧3:相关表达扩展,覆盖同一概念的不同学术表述
很多学术概念在文献中会有不同的衍生表达,用通配符扩展词根,能一次性覆盖这些相关术语,不用反复修改关键词。
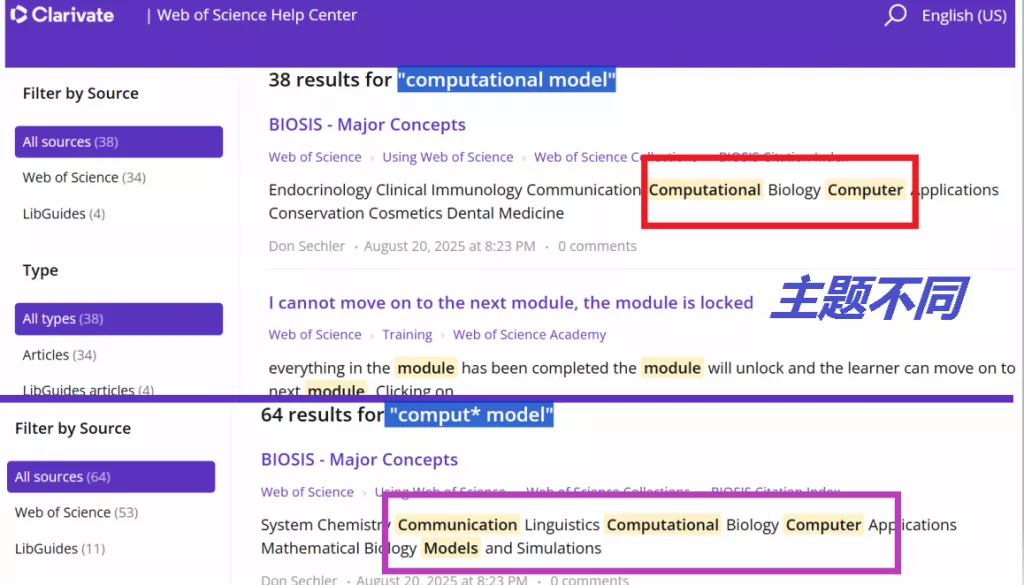
示例:研究“计算机相关研究”,输入 comput*,可匹配:
– computer(计算机)、computing(计算)、computational(计算的);
– computer science(计算机科学)、computational model(计算模型)等相关表达。
四、如何判断截词检索是否有效?
很多人使用通配符后,会遇到一个新问题:检索结果突然变得非常多,甚至出现大量无关文献。比如输入comput*,可能返回计算机科学、计算生物学、计算机视觉等完全不同方向的论文,反而增加筛选难度。
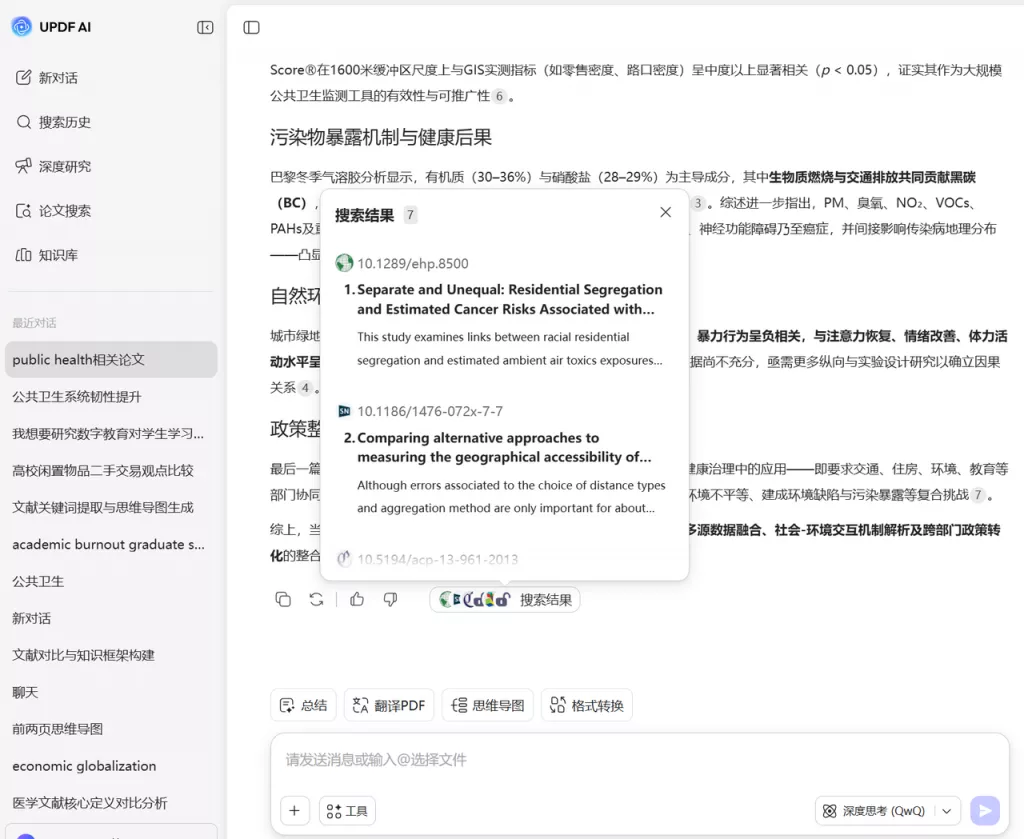
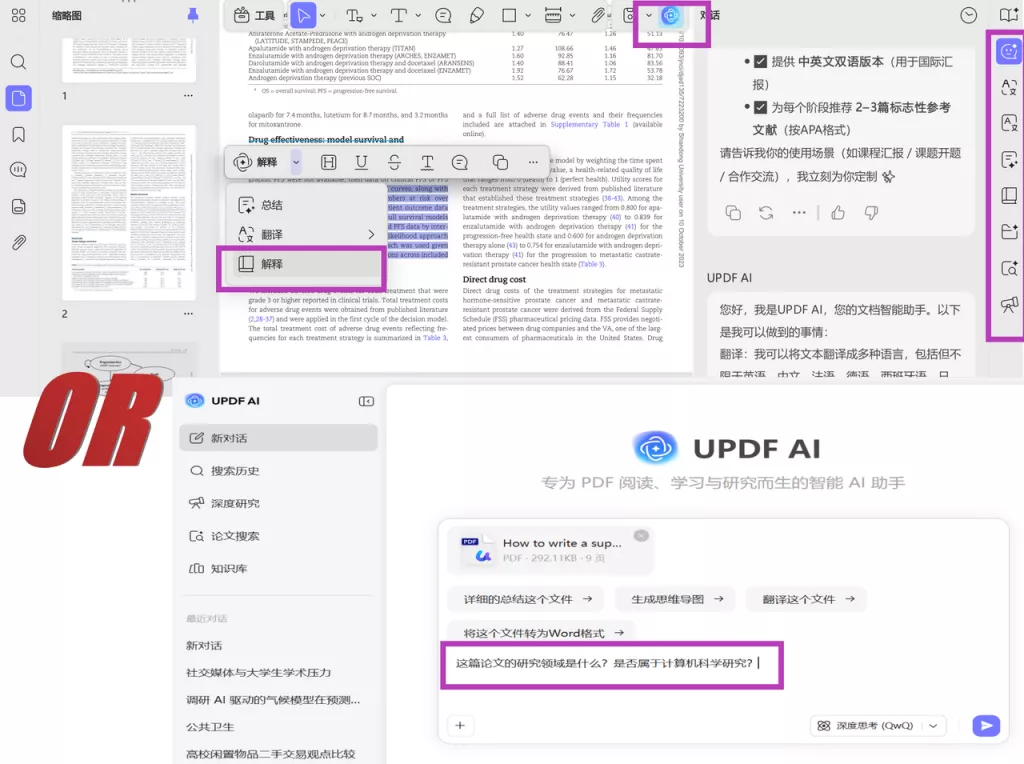
这时候,关键不是盲目删除通配符,而是快速判断截词后的文献是否符合研究方向。我常用的高效方法是:将不同检索式(带通配符和不带通配符)的核心论文,统一导入UPDF中,借助UPDF AI功能快速筛选,不用逐篇精读。
具体做法:
1. 导入核心论文后,直接向UPDF AI提问,快速确认关键信息:
– 这篇论文的研究领域是什么?是否符合我的研究方向?
– 文中的核心概念(如model、technology)具体指什么?
– 研究内容是否和我关注的主题一致?
2. 通过AI问答、AI解释功能,1-2分钟就能判断一篇论文的相关性,快速对比不同截词策略的效果,找到最适合自己的检索范围,避免被无关文献淹没。
五、通配符使用的3个注意事项
通配符虽好用,但使用不当会产生大量检索噪音,甚至导致检索结果失控。记住以下3个注意事项,既能发挥通配符的作用,又能保证检索精准度。
1. 不要截得太短,至少保留4-5个字母作为词根
这是最常见的误区:词根截得太短,会匹配到大量无关词汇,导致检索结果混乱。
反面示例:输入 cat*,可能匹配 category(类别)、catalyst(催化剂)、catabolism(分解代谢)等,和“猫”无关的词汇,完全偏离检索主题;
正确做法:至少保留4-5个字母作为词根,比如 catal*(匹配catalyst、catalytic等),既覆盖相关词形,又避免无关噪音。
2. 先观察结果,再使用通配符扩展(由窄到宽)
很多新手一开始就用通配符,容易导致检索范围过大、噪音过多。正确的检索顺序是:
1. 先用完整关键词检索(如 educational technology),观察检索结果的数量和相关性;
2. 若结果过少,说明有漏检,再使用通配符扩展词根(如 educat* AND technolog*);
3. 观察扩展后的结果,若噪音过多,可结合NOT运算符排除无关内容,逐步优化。
3. 与AND/OR组合使用,提升检索效率
通配符很少单独使用,结合布尔运算符(AND/OR),能既扩大覆盖范围,又锁定核心概念,检索结果更精准。
示例:研究“教育技术在教学中的应用”,可写成:
educat* AND technolog* AND (teaching OR instruction)
既用通配符覆盖“教育”“技术”的所有词形,又用OR扩展“教学”的同义词,同时用AND锁定核心概念,检索效率大幅提升。
通配符检索常见问题解答
1. 什么是文献检索中的通配符?
通配符是用于替代词的一部分字符的检索符号,核心作用是匹配同一词根的多种变体形式,比如 educat* 可匹配 education、educational等,避免漏检。
2. 通配符和截词有什么区别?
在学术检索中,两者基本是同一个概念。截词(Truncation)是检索目的(截取词根、扩展词形),通配符是实现截词的工具,常用的通配符有*、?、$等。
3. 哪些数据库支持通配符检索?
大多数学术数据库都支持,比如Google Scholar、Web of Science、Scopus、知网、万方等,但不同数据库的通配符符号可能略有差异,使用前可查看数据库的检索帮助。
总结
通配符(截词检索)是文献检索中最实用的技巧之一,核心价值在于“用一个词根,覆盖所有相关词形”,帮你避免因词形变化、表达差异导致的漏检,同时减少反复输入关键词的麻烦。
推荐一套新手可直接套用的检索流程:
1. 初始检索:用完整关键词检索,观察结果数量和相关性;
2. 扩展检索:若结果过少,用通配符扩展词根,覆盖相关词形;
3. 优化检索:结合AND/OR锁定核心概念,用NOT排除无关噪音;
4. 效果验证:用UPDF AI功能,快速判断文献相关性,调整截词范围。
掌握这个流程,再用好通配符,你会发现文献检索不再有“漏检”的遗憾,既能全面覆盖相关文献,又能精准过滤噪音,为学术研究、论文写作节省大量时间。