AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













在进行文献检索时,很多研究者往往不会只依赖一个数据库。为了尽可能覆盖更多研究成果,人们通常会同时使用多个学术平台,例如 Web of Science、Scopus、Google Scholar,甚至还会结合一些专业数据库进行补充检索。这样做的好处是可以扩大文献来源,减少遗漏重要研究的风险。
然而,多数据库检索也会带来一个几乎所有研究者都会遇到的问题:文献重复。
不同数据库之间的收录范围往往存在大量重叠,一篇论文可能同时出现在多个平台的检索结果中。如果没有及时进行整理,这些重复文献很容易在阅读过程中反复出现,逐渐增加研究者的筛选成本。
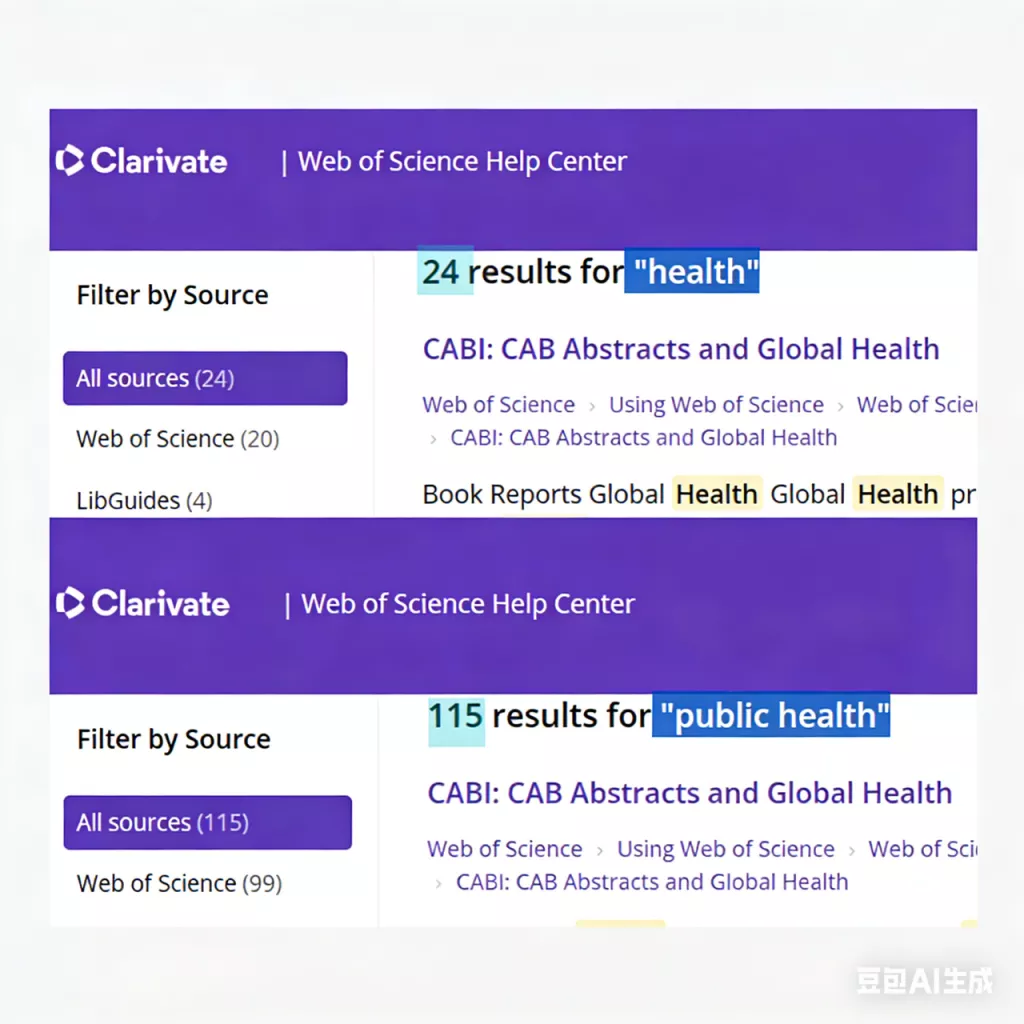
一篇国际期刊论文可能同时被 Web of Science、Scopus 和 Google Scholar 收录。如果在这些数据库中分别检索同一关键词,就会多次看到同一研究。
刚开始时,这种重复似乎并不会造成太大影响。但随着文献数量逐渐增加,例如达到50篇、100篇甚至更多,重复问题就会变得非常明显。如果没有建立合理的去重策略,研究者很容易在重复阅读中消耗大量时间。
因此,在进行多数据库检索时,去重并不是一个简单的整理步骤,而是一种重要的文献管理策略。它不仅可以减少重复文件,更能帮助研究者更快识别核心研究。这篇文章将从实际科研流程出发,详细讲解多数据库检索如何去重,以及如何减少重复阅读。
一、为什么多数据库检索容易产生重复文献?
要解决重复问题,首先需要理解它是如何产生的。在学术出版体系中,一篇论文往往会被多个数据库同时收录,这些数据库之间存在大量交叉。因此,如果研究者在不同数据库中使用相同关键词检索,很可能会多次看到同一篇论文。
因此,当研究者同时使用多个数据库进行文献检索时,重复文献几乎是不可避免的。关键不是完全避免重复,而是建立一套合理的识别与筛选方法。
二、第一步:在检索阶段减少重复来源
减少重复文献的第一步,其实发生在检索阶段。很多新手在使用多个数据库时,习惯把相同关键词直接复制到不同平台进行检索。这种方式虽然简单,但往往会带来大量重复结果。
一个更稳妥的方法是先确定一个核心检索入口,再扩展到其他数据库。例如,可以先通过综合学术搜索工具找到一批核心论文,然后再到其他数据库中进行补充检索。
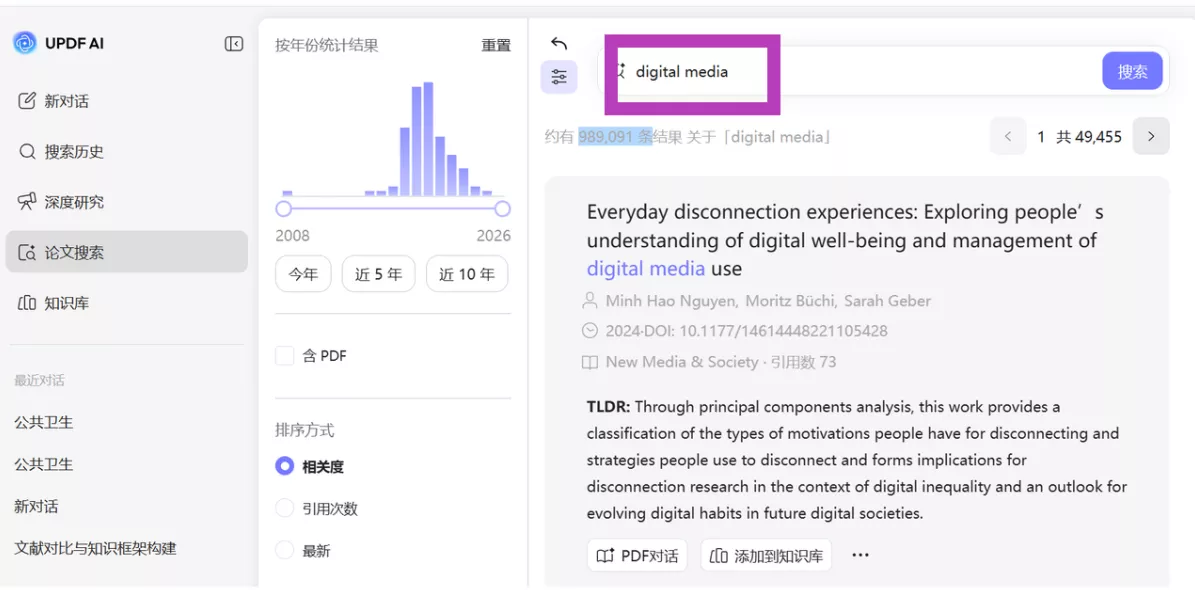
在这个阶段,UPDF AI的论文搜索功能可以作为一个很有效的入口。研究者只需要输入研究主题,系统就会返回一批相关论文,并展示论文标题、摘要和关键词。
由于 UPDF AI论文搜索聚合了多源学术数据库资源,可检索超过2.2亿篇学术论文,研究者可以在短时间内获得较完整的文献列表。这一步的作用不是替代数据库,而是帮助研究者更快建立一个基础文献集合。
当核心论文确定之后,再到其他数据库中补充检索,就更容易识别哪些论文已经出现过,从而减少重复下载。
三、第二步:快速识别重复论文
当文献开始下载时,重复论文通常会逐渐增加。因此,在下载阶段可以通过几个简单方法进行判断。
- 查看论文标题
同一篇论文在不同数据库中的标题通常完全相同。如果两篇论文标题一致,很可能是重复文献。
- 查看作者与年份
如果标题略有差异,可以查看作者列表和发表年份。如果这些信息完全相同,大概率是同一研究。
- 查看 DOI
DOI 是论文的唯一标识。如果 DOI 相同,就可以确认是同一篇论文。
通过这些方法,可以在下载阶段减少一部分重复文件。
不过,在文献数量较多时,仅依靠人工判断仍然会比较耗时。
四、利用跨文献对比分析减少重复阅读
即使已经初步筛选,文献列表中仍然可能存在内容高度相似的研究。如果逐篇阅读,很容易重复花费时间。这时候,我们就要跨文献对比分析。
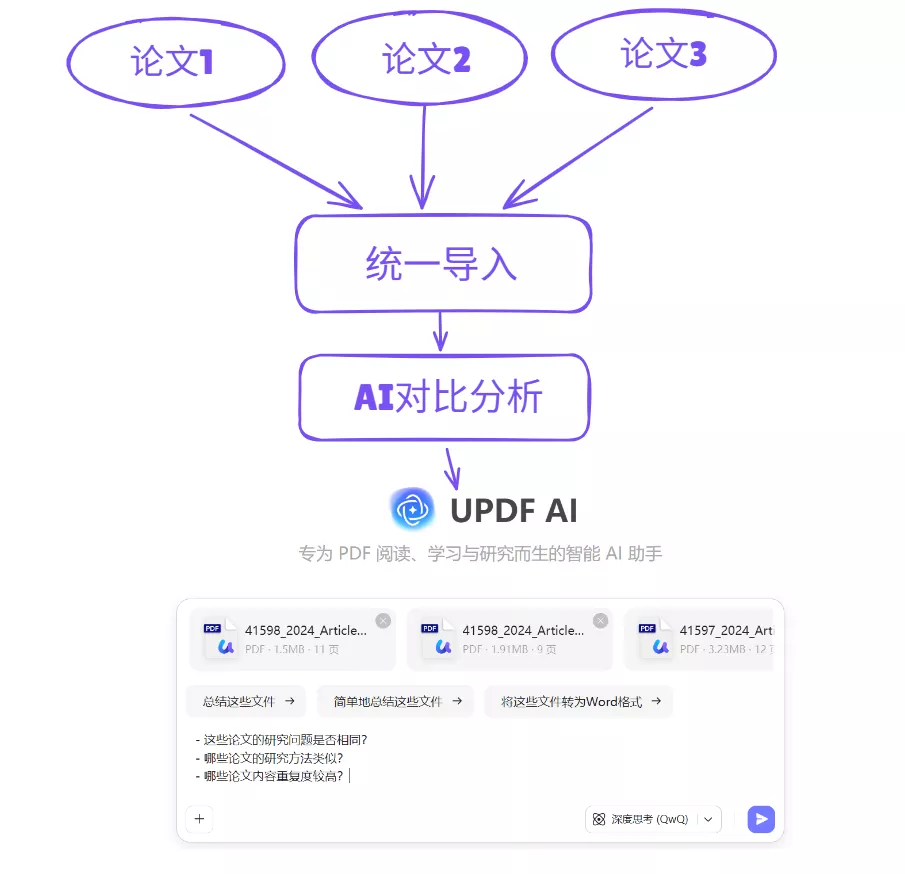
例如,当你在多个数据库中找到几十篇论文时,可以把这些论文统一导入一个阅读环境,然后进行整体比较。
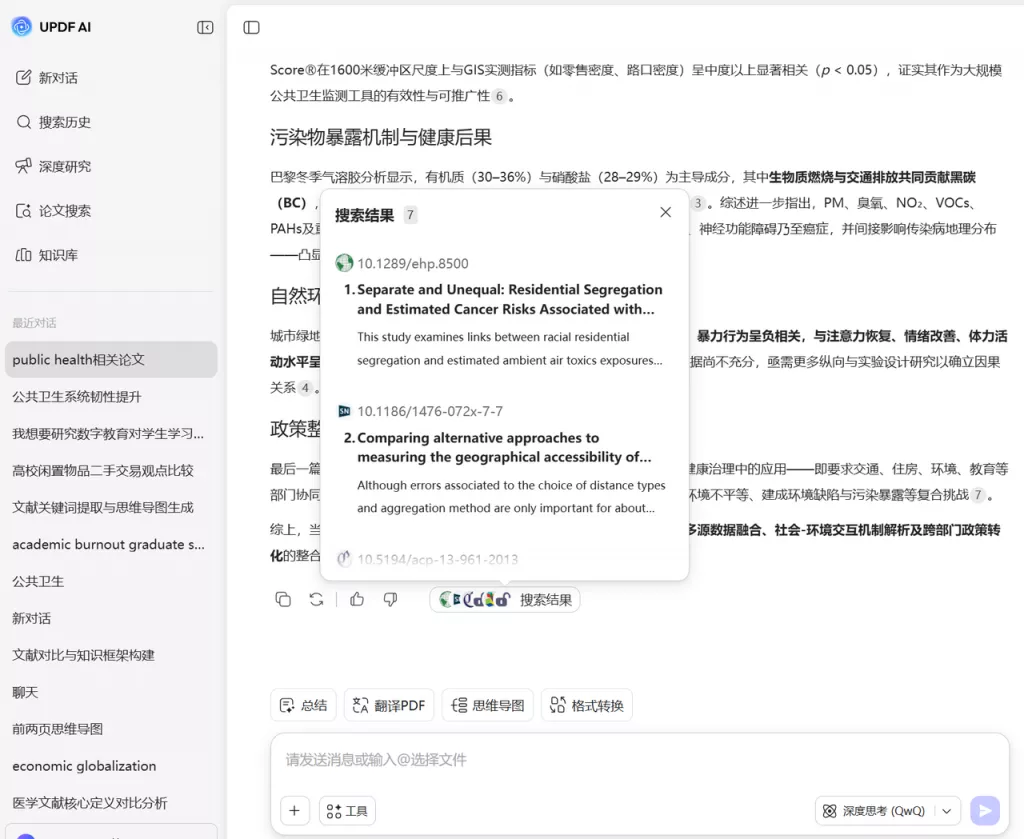
在 UPDF AI 中,可以使用多文件问答功能同时分析多篇论文。例如,当导入多篇PDF后,可以直接向AI提问这些论文的研究问题是否相同,AI会根据文档内容进行分析,并生成结构化总结。通过这种方式,研究者可以更快识别哪些论文是核心研究。对于需要阅读大量文献的人来说,这种方式可以显著减少重复阅读时间。
五、建立统一文献管理体系
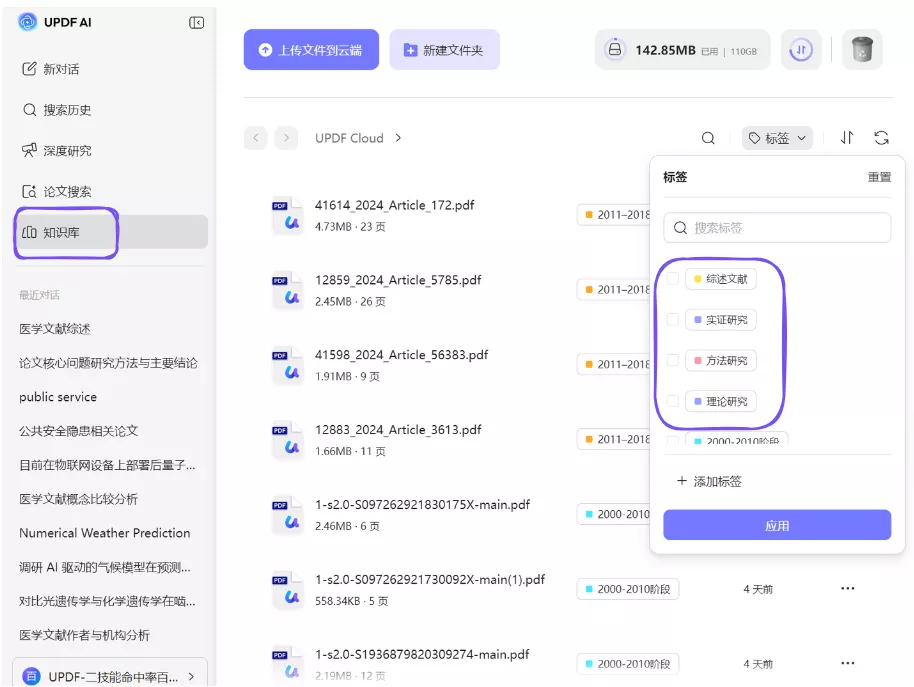
当多数据库检索完成之后,最后一个重要步骤是统一管理文献。如果论文分散在不同文件夹或不同设备中,即使前面已经筛选过,也很容易再次出现重复阅读。因此,建议在检索完成后建立一个统一文献库。
在 UPDF 的知识库功能中,可以按照研究主题对文献进行分类。当新的论文导入时,可以直接存入对应分类。这样不仅可以减少重复文件,还可以帮助研究者更清晰地管理文献。随着研究不断推进,这个知识库会逐渐形成一个稳定的学术资料体系。
六、一个完整的多数据库去重流程
如果把前面几个步骤整合起来,可以形成一个比较清晰的多数据库去重流程。
第一步:建立核心文献列表
通过学术搜索工具找到第一批重要论文。
第二步:跨数据库扩展检索
在不同数据库中补充相关研究。
第三步:下载阶段初步去重
通过标题、作者和 DOI 判断重复论文。
第四步:跨文献分析
通过 AI 工具对多篇论文进行比较。
第五步:统一文献管理
将文献分类存入知识库。
通过这样的流程,即使文献数量达到上百篇,也可以保持清晰结构。
常见问题
问题1:多数据库检索为什么容易出现重复文献?
回答:因为很多论文被多个数据库同时收录。
问题2:如何快速判断两篇论文是否重复?
回答:可以查看标题、作者和 DOI。
问题3:如何避免重复阅读相似研究?
回答:可以通过 UPDF 多文件问答进行跨文献分析。
总结
在科研过程中,多数据库检索可以有效减少文献遗漏,但同时也会带来大量重复文献。如果没有合理的去重策略,研究者很容易在重复阅读中浪费时间。在这一过程中,像 UPDF 这样的 AI 学术工具可以在多个环节提供帮助,例如:
- AI论文搜索帮助快速建立基础文献列表
- 多文件问答帮助识别重复研究和相似论文
- 知识库帮助统一管理来自不同数据库的文献
当检索、阅读和整理形成完整流程时,多数据库检索就会变得更加高效,也更容易帮助研究者找到真正重要的研究成果。