AI 网页版
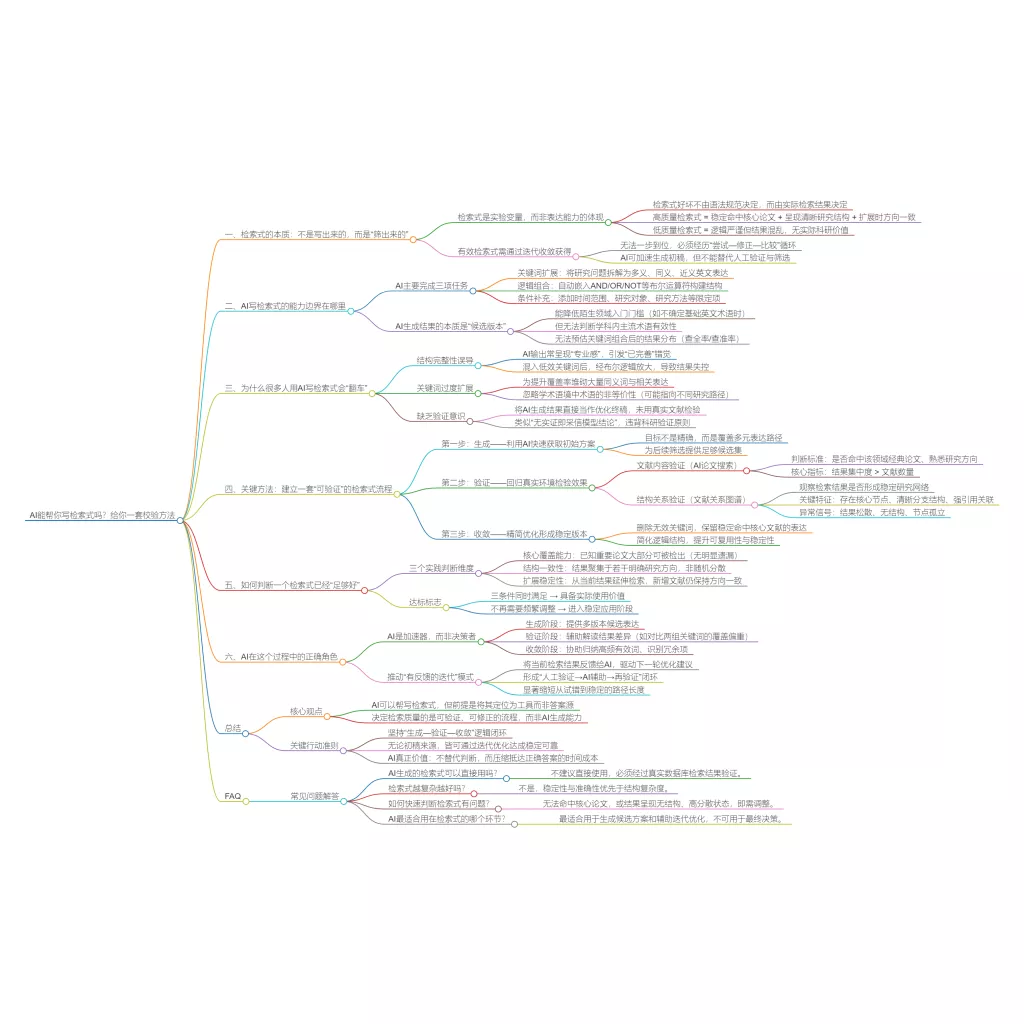
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
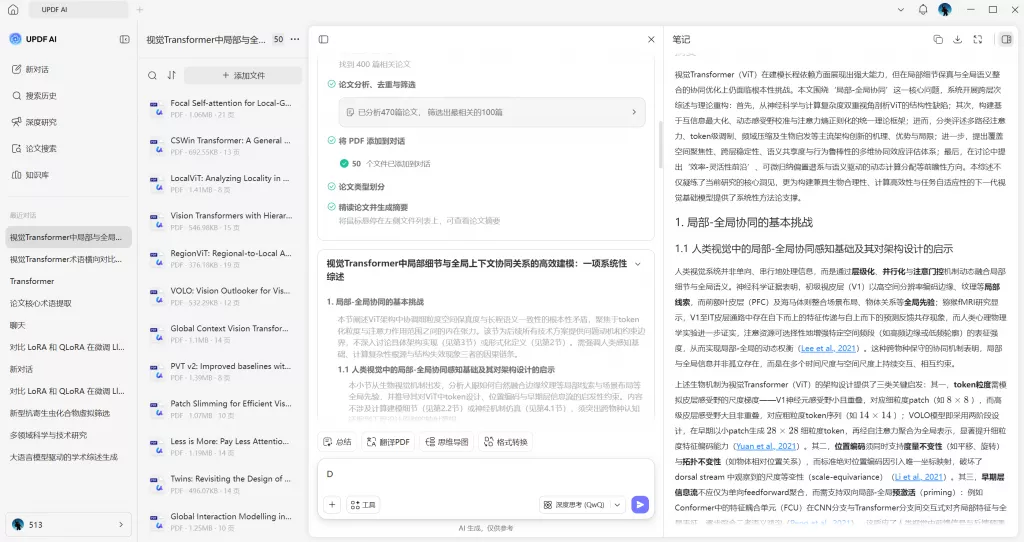
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
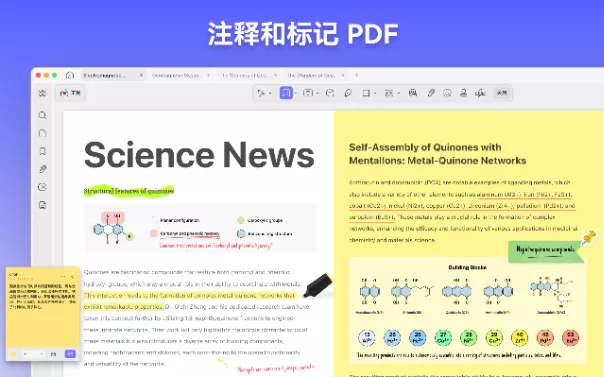
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
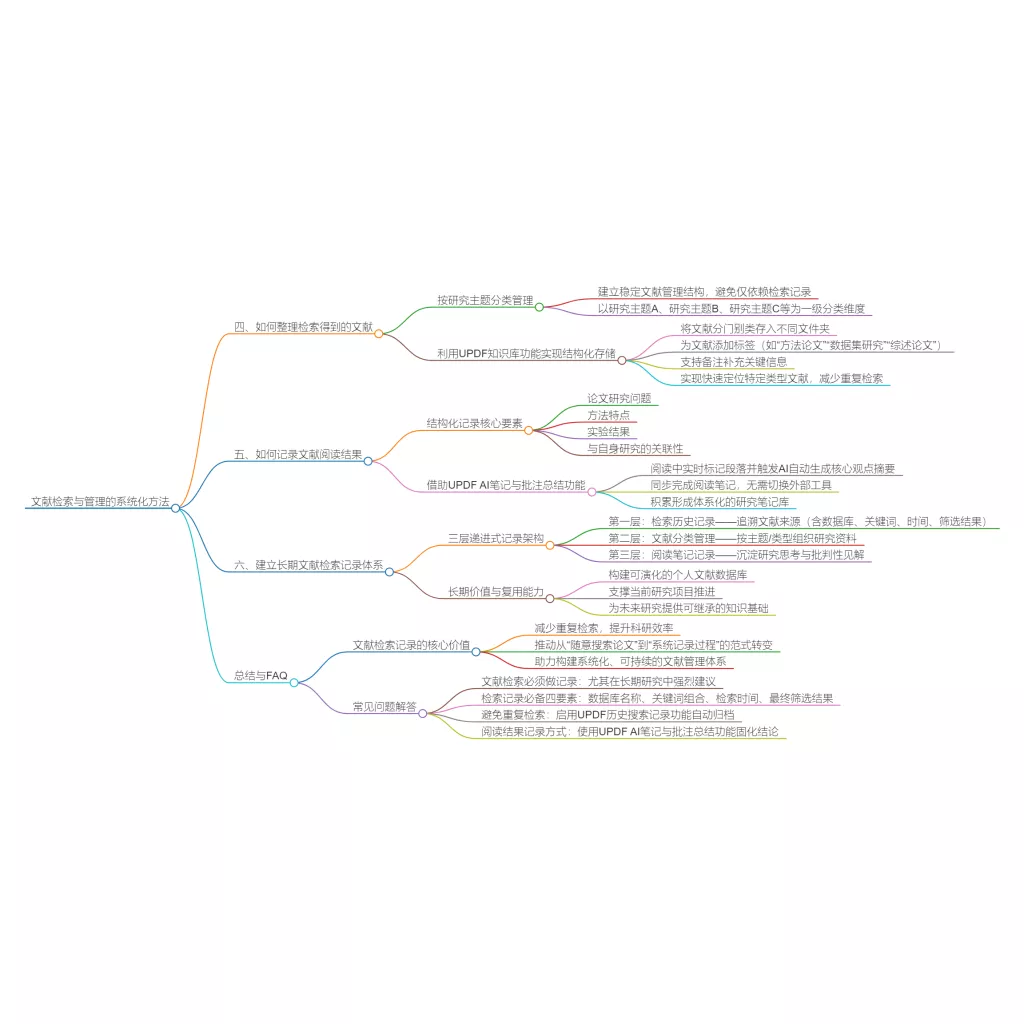
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













在文献检索阶段,很多研究生发现论文已经看了不少,关键词也换着试了很多种,但当导师突然问一句“这篇算不算这个领域的核心文献?”,你却很难给出一个有底气的答案。
你可能会这样回答导师:
- 这篇论文被引用的次数很多
- 这篇论文发表的期刊很不错
- 这篇论文看起来挺有代表性的
但其实你自己心里也没底,不确定自己说的对不对。这个时候,问题往往不是你“看得不够多”,而是你一直在用“孤立看单篇论文”的思路,而不是“从整体关系”的角度,去判断一篇文献的重要性。而能帮你跨过这个难关、分清核心文献的关键,那就是引文网络。
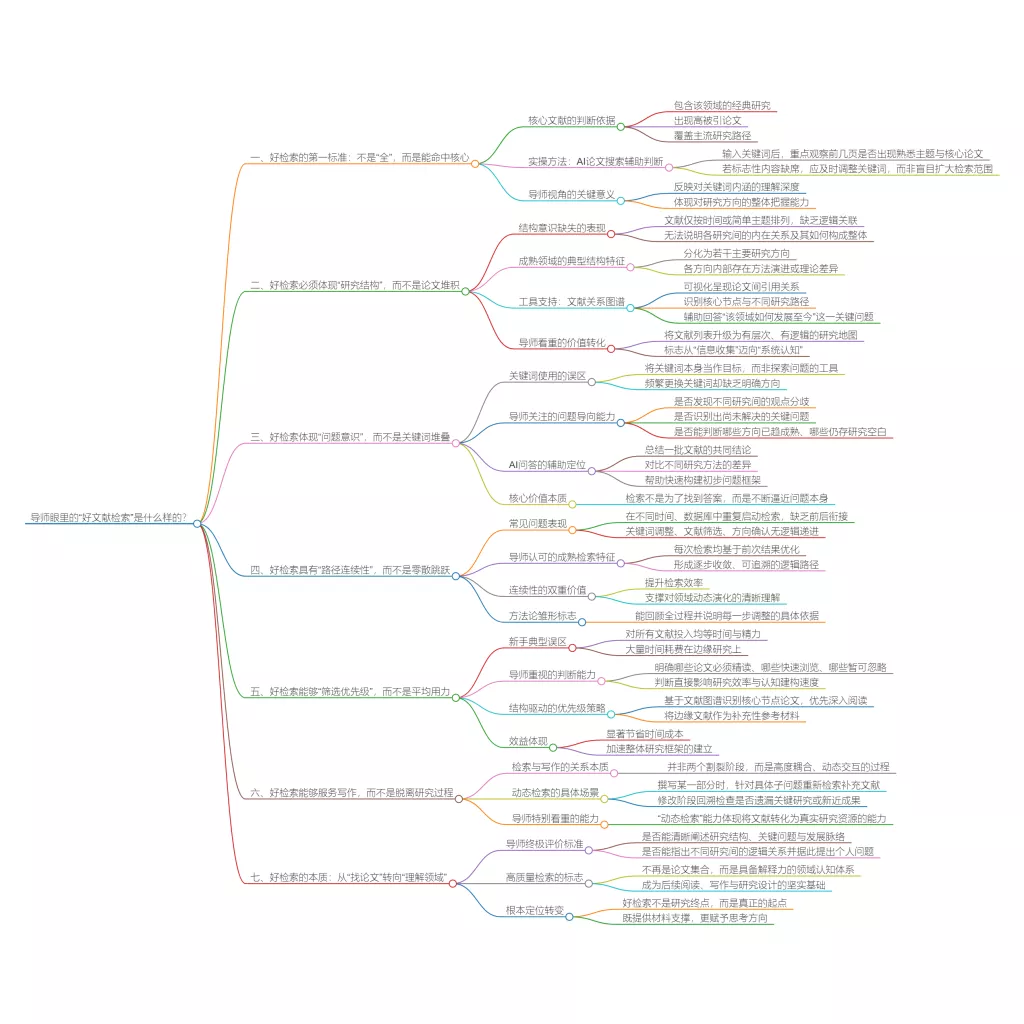
一、什么是引文网络?为什么它比“被引次数”靠谱多了?
在很多人眼里,“引文”就等同于一个数字:被引次数高,就等于这篇论文很重要。但在真实的学术研究里,这种想法太片面、太粗糙了。
1. 引文网络 ≠ 被引次数排行榜
被引次数只是一个最终结果,而引文网络描述的是论文之间的关系。
引文网络不关心“某篇论文(比如A)被引用了多少次”,它真正关心的是:
- 谁在引用A这篇论文?
- A和哪些论文经常一起被其他论文引用?
- A在整个研究领域的网络里,处在什么位置?
简单来说,引文网络看的是“论文之间的连接关系”,而不是“被引次数这个单纯的数量”。
2. 为什么核心文献,在引文网络里一定能被找到?
核心文献之所以重要,是因为它通常有这几个明显特征,而这些特征,只有放在引文网络里才能看得清清楚楚:
- 会被不同的研究方向、不同的研究路径同时引用
- 在很长一段时间里,都会被后续研究反复提及、引用
- 经常被当作理论基础,或者研究方法的“中转节点”,连接不同的研究
这些特征,单看某一篇论文是绝对发现不了的,但一旦把论文放进引文网络里,核心文献就会自动“显形”。
二、什么时候需要用引文网络判断核心文献?
引文网络不是一开始就要用的,它有明确的使用时机。只要出现下面3种情况,就说明你该用引文网络了。
情况1:感觉每篇论文都重要,却分不清核心
这是最典型的信号:你看了很多论文,觉得每篇都有道理,很多论文也都被反复引用,但就是说不清楚,哪几篇才是这个领域真正的“基础款”“核心款”。这时候就需要换个角度,从“论文之间的关系”出发,重新给文献排序。
情况2:写综述时,总觉得结构不稳、逻辑混乱
很多人写不好综述,不是找的材料不够多,而是自己人为地给论文分类,显得很生硬,各个部分之间也没有逻辑关联。而引文网络能帮你发现,这些论文本来就有的“自然分组”,让综述的结构更合理。
情况3:不确定自己有没有漏掉关键论文
当你已经读了很多论文,但还是心里没底,担心自己漏了重要文献时,引文网络就能帮你反向验证。如果引文网络里反复出现的论文,你都已经读过了,那就说明你的文献检索已经比较充分了。
三、引文网络的第一种视角
被共同引用(Co-citation)是判断核心文献最经典、也最靠谱的方法之一,操作起来也不复杂。
1. 什么是“被共同引用”?
如果有两篇论文,经常一起出现在第三篇论文的参考文献列表里,就说明这两篇论文,在后续研究者眼里,在理论或者研究方法上,联系非常紧密。
2. 为什么“被共同引用”能判断核心文献?
因为“被共同引用”反映的是整个学术圈的集体判断,而不是某一个作者的个人偏好。如果一篇论文,经常和不同的论文“成对出现”被共同引用,那它大概率就处在这个研究领域的中心位置,是核心文献。
3. 实际判断时,你该看什么?
在找文献、看文献的时候,重点关注这两点就好:
- 哪些论文,在很多篇其他论文的参考文献里反复出现?
- 哪些论文,经常和不同研究方向、不同研究路径的论文一起被引用?
满足这两点的论文,通常就是跨研究路径的核心文献。
四、引文网络的第二种视角
向后追溯(Backward citation)最容易上手,但经常被大家忽略,其实实用性很强。
1. 什么是“向后追溯”?
简单说就是:先找到一篇你已经确定“很重要”的论文,然后顺着这篇论文,去系统地读它的参考文献。听起来很基础,但关键是,你不能随便看,要带着“找核心”的思路去看。
2. 向后追溯,真正要找的是什么?
不是让你把这篇论文的所有参考文献都看完,而是重点找这三类文献:
- 被这篇论文多次引用的老文献
- 这篇论文的作者,反复依赖、反复提及的理论来源类文献
- 被作者放在“理论基础”或“研究方法”部分,作为支撑的论文
这三类文献,往往就是这个领域的“奠基性核心文献”,是整个研究的基础。
3. 一个重要的判断信号
如果发现:不同的作者、不同时期发表的论文,都在引用同一批“老文献”,那不用怀疑,这些老文献几乎一定是这个领域的“地基”,是重中之重。
五、引文网络的第三种视角:
如果说向后追溯是“找源头、找基础”,那向前追踪就是“看影响、看价值”。
1. 什么是“向前追踪”?
向前追踪(Forward citation)和向后追溯相反,找到一篇重要论文后,去查看这篇论文后来被哪些研究引用了,这些后续研究,又基于这篇论文做了哪些扩展、哪些延伸。
2. 为什么向前追踪能判断核心文献?
真正的核心文献,不会只被引用几次就沉寂,它往往会有这些影响:
- 被不同研究方向的论文继承、借鉴
- 后续研究会不断地基于它,做改造、做修正,甚至做批判
- 成为后续研究绕不开的“标杆”,不管是支持还是反驳,都要提到它
如果一篇论文只是被引用得多,但后续研究没有基于它做任何扩展,那它的重要性其实很有限,算不上核心文献。
3. 一个实用的判断方法
向前追踪时,不用逐一统计被引次数,重点看两点:这篇论文有没有形成“引用簇”(很多后续论文围绕它展开);有没有出现围绕这篇论文的争论或研究分支。只要有其中一点,这篇论文大概率就是核心文献。
六、引文关系太复杂,人脑记不住怎么办?
当你同时追溯多篇论文、关注多个作者、横跨多个研究路径时,很容易出现这些问题:重复阅读同一篇论文、对核心文献的判断前后矛盾、记不清某篇论文的位置和关系。这不是你记性不好,而是人脑根本无法稳定记住复杂的引文关系。
工具介入的关键:不用硬记,用工具整理
科研中最常用也最实用的方法,分享给大家:
- 把你觉得有潜力的核心候选论文,统一导入UPDF(或其他文献管理工具);
- 阅读和批注时,使用注释功能标注这篇论文被谁引用、引用了谁、在整个研究网络中处在什么位置;
当多篇论文的引文关系,被放在同一个视野里对比时,引文网络的结构会自动显现出来,不用再靠脑子硬记,判断起来也更准确。
七、判断核心文献的信号
综合上面所有方法,只要一篇论文满足下面任意多项,几乎可以确定它就是核心文献:
- 在不同的研究路径、不同的研究方向中,被反复引用;
- 既出现在向后追溯的引文链里(是基础),也出现在向前追踪的引文链里(有影响);
- 经常被当作某类研究的“理论起点”或“方法起点”;
- 在引文网络中,处于“连接多个引用簇”的位置,是不同研究分支的连接点。
八、引文网络如何和其他检索方法形成闭环?
一个成熟、高效的文献检索体系,不用盲目找文献,遵循这个顺序就好,能帮你快速收口,不做无用功:
- 关键词检索:先通过关键词,快速进入这个研究领域;
- 近义词扩展:用关键词的近义词、同义词检索,补充漏掉的文献,补全覆盖;
- 布尔逻辑:用“与、或、非”等逻辑,控制检索范围,避免无关文献过多;
- 作者检索:关注这个领域的核心作者,看看他们的研究成果,理解领域内的研究人员分布;
- 基金号检索:通过相关基金号检索,锁定这个领域的研究主线;
- 引文网络:最后用引文网络,判断出这个领域真正的核心文献。
当你通过引文网络发现这两个信号时,就说明你的文献检索可以收口了:没有新的核心文献节点出现;新找到的文献,大多都是围绕已有的核心文献展开的,没有新的突破和方向。
总结
很多研究生在找文献时,很担心自己会漏掉最重要的那几篇核心文献。但事实上,核心文献不是“看出来的”,而是“从关系中找出来的”。而引文网络不能保证你看完这个领域所有的论文,但它能帮你确定真正重要的核心文献。
当你不再只看论文的标题和摘要,而是开始通过引文关系,理解每篇论文的位置和价值时,你的文献检索能力,就已经从“凭感觉”的经验型,升级成“有方法”的研究型了。