AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南












在系统综述、Meta 分析以及正式学术研究中,PRISMA(Preferred Reporting Items for Systematic Reviews and Meta-Analyses)几乎已经成为最主流的文献筛选框架。很多人在第一次接触 PRISMA 时,会把它理解成“一张流程图”,但真正开始做系统综述之后才会发现:PRISMA 的核心并不是画图,而是让整个文献筛选过程具备透明性、可追踪性与可复现性。
尤其是在 PubMed、 Web of Science、 Scopus 等数据库中进行大规模检索时,如果没有稳定流程,研究者很容易出现以下问题:
- 文献筛到后面越来越混乱
- 不知道哪些论文已经删除
- 无法说明为什么排除某些研究
- 后期无法补全 PRISMA 流程图
很多系统综述最后最大的返工,并不是写作,而是“重新整理筛选过程”。PRISMA 真正重要的,不是最后那张流程图,而是整个筛选链路是否始终具备一致逻辑。

一、PRISMA 到底在解决什么问题?
很多研究者会误以为 PRISMA 是一种“格式要求”,但实际上,它解决的是如何让文献筛选过程可公开、可验证。因为系统综述最大的风险,并不是“找不到文献”,而是研究者主观选择文献、筛选标准前后变化和删除理由不透明,PRISMA 的核心价值,就是要求研究者把整个流程完整公开,包括文献从哪里来、如何去重、为什么排除和最终为什么留下。因此,它本质上是一种“筛选过程管理框架”。
二、PRISMA 标准流程包括哪些阶段?
一个完整的 PRISMA 流程,通常包括以下几个核心阶段:
| 阶段 | 核心任务 |
| 检索(Identification) | 从数据库获取文献 |
| 去重(Deduplication) | 删除重复研究 |
| 初筛(Screening) | 标题与摘要筛选 |
| 全文评估(Eligibility) | 判断是否符合纳入标准 |
| 最终纳入(Included) | 进入系统综述 |
很多研究者的问题,并不是“不知道这些步骤”,而是不知道每一步到底应该记录什么。
三、数据库检索怎么做才符合 PRISMA?
PRISMA 并不要求你一定使用某一个数据库,但要求:
- 检索来源必须明确
- 检索逻辑必须可复现
因此,在实际研究中,通常会组合多个数据库,例如:
| 数据库 | 更适合领域 |
| PubMed | 医学、生物 |
| Web of Science | 综合研究 |
| Scopus | 引文分析 |
| IEEE Xplore | 工程与计算机 |
| ERIC | 教育研究 |
在这一阶段,最容易被忽略的问题其实是没有保留检索逻辑。例如使用了什么关键词、使用了什么布尔逻辑、检索时间是什么,如果这些信息没有记录,后期很难复现整个筛选过程。
很多研究者在这一阶段,会直接通过 PDF 批注记录“数据库来源”与“检索时间”,而不是后期重新补充。这种做法后期整理 PRISMA 方法部分时会轻松很多。
四、PRISMA 去重阶段怎么做?
在多个数据库联合检索时,重复文献几乎不可避免。
例如:
- 同一研究出现在 Scopus 与 Web of Science
- 预印本与正式版同时出现
- 会议论文与期刊扩展版重复
如果这一阶段处理不规范,后续筛选数量会明显失真。
传统做法通常依赖EndNote、Zotero和Excel 手动比对,但真正困难的部分,其实不是“找到重复”,而是如何记录“为什么删除这个版本”。
例如,在筛选过程中,很多研究者会直接通过 PDF 高亮标记“重复发表”、“保留期刊最终版”、“删除预印本版本”。这样后期整理 PRISMA 流程图时,可以直接追溯删除原因,而不是重新回忆。
五、标题与摘要初筛怎么避免失控?
PRISMA 初筛阶段最大的特点是文献数量最多,但判断最浅。因此,这一阶段真正重要的,并不是“读懂文献”,而是快速过滤、统一标准、保留筛选依据。
很多研究者的问题在于一边筛一边改标准、删除后没有记录原因、后期重新打开同一文献,这会导致整个流程越来越混乱。因此,在初筛阶段,建议直接通过批注记录变量不匹配、方法不符或者研究对象错误。这样后期即使重新查看,也能快速理解之前的判断逻辑。
六、全文评估为什么最容易返工?
全文评估阶段,是 PRISMA 中最耗时的部分。因为这一阶段不再只是判断“是否相关”,而是判断是否真正符合纳入标准、是否能够进入结构或者是否具备可比性。
很多研究者会在这一阶段重新推翻前期筛选结果。最常见的问题包括方法体系不可比、数据不完整或者变量定义不一致。如果这些理由没有被记录,后期写系统综述时,很容易出现“知道删了,但不知道为什么删”的情况。因此,全文评估阶段真正重要的,并不是“读更多”,而是“留下判断依据”。
七、结合 UPDF 的 PRISMA 全链路管理方法
在 PRISMA 场景中,UPDF 更适合承担的角色,并不是单纯的 PDF 阅读工具,而是帮助研究者把整个筛选过程真正结构化。
首先,在数据库检索完成后,可以将候选文献统一导入 UPDF,并在初始阶段通过批注与高亮功能直接记录数据库来源、关键词匹配情况以及初步筛选意见。这样做的关键价值在于:筛选依据会直接沉淀在文献内部,而不是分散在外部表格中。

其次,在去重阶段,可以直接在不同版本文献中标记“重复研究”、“保留正式版”或者“删除会议摘要”,后续整理 PRISMA 流程时,可以快速追溯删除逻辑。
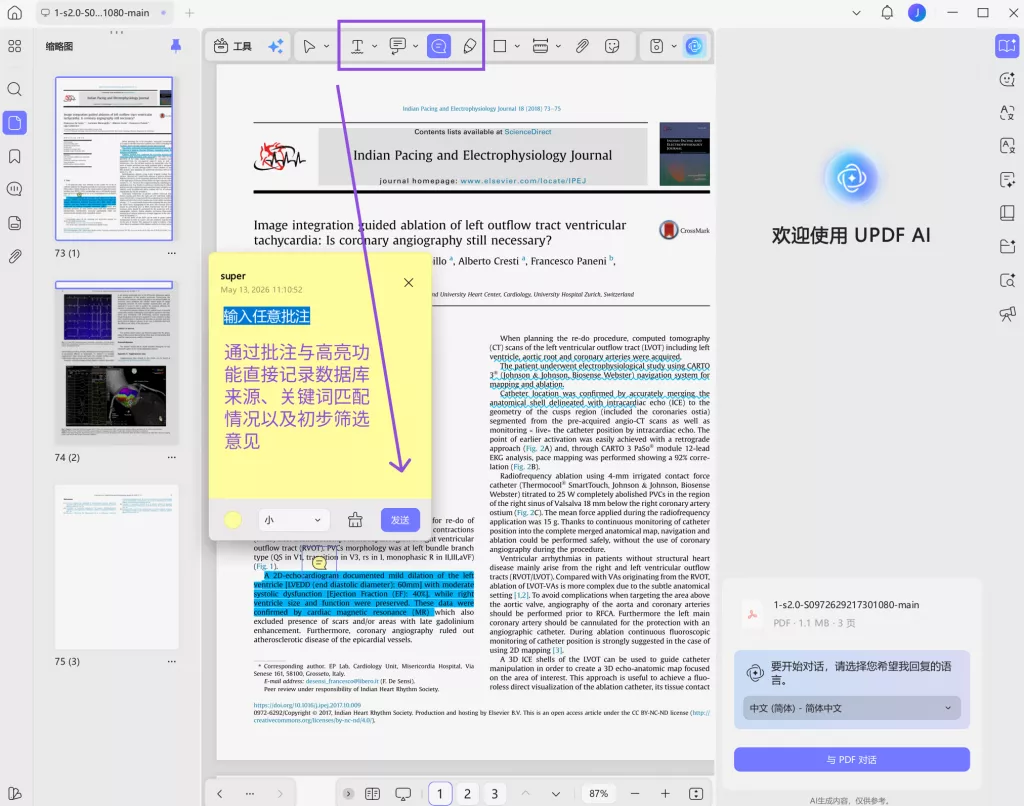
进入标题与摘要筛选后,研究者可以进一步通过批注记录变量不匹配、方法不符合或者研究对象错误,这样在后续全文评估时,不需要重新从头筛选。
在全文评估阶段,UPDF 的AI生成批注总结 / 结构化笔记功能,会更适合把分散的筛选依据自动整理为结构化内容。这些内容后续可以直接整理进 PRISMA 方法部分。
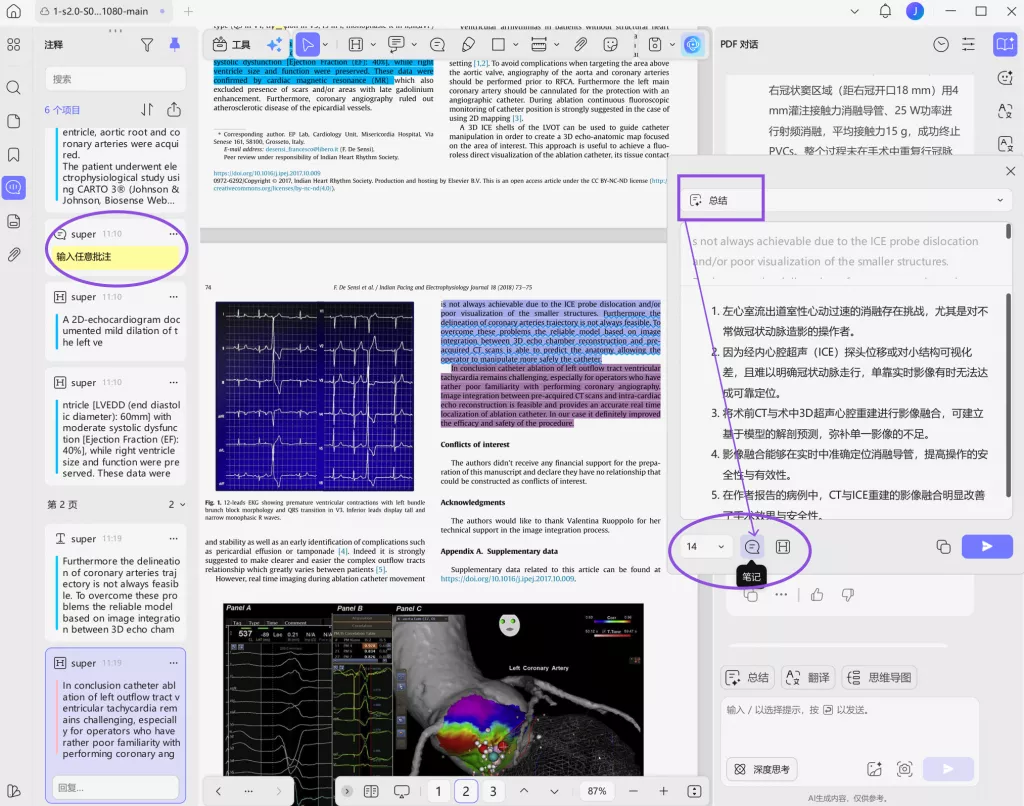
对于最终纳入研究,还可以通过笔记导出与分享,直接输出筛选记录与结构化批注,用于团队协作或系统综述写作。相比传统方式,这种方法最大的优势在于:PRISMA 不再只是“最后补流程图”,而是整个筛选过程持续被记录。
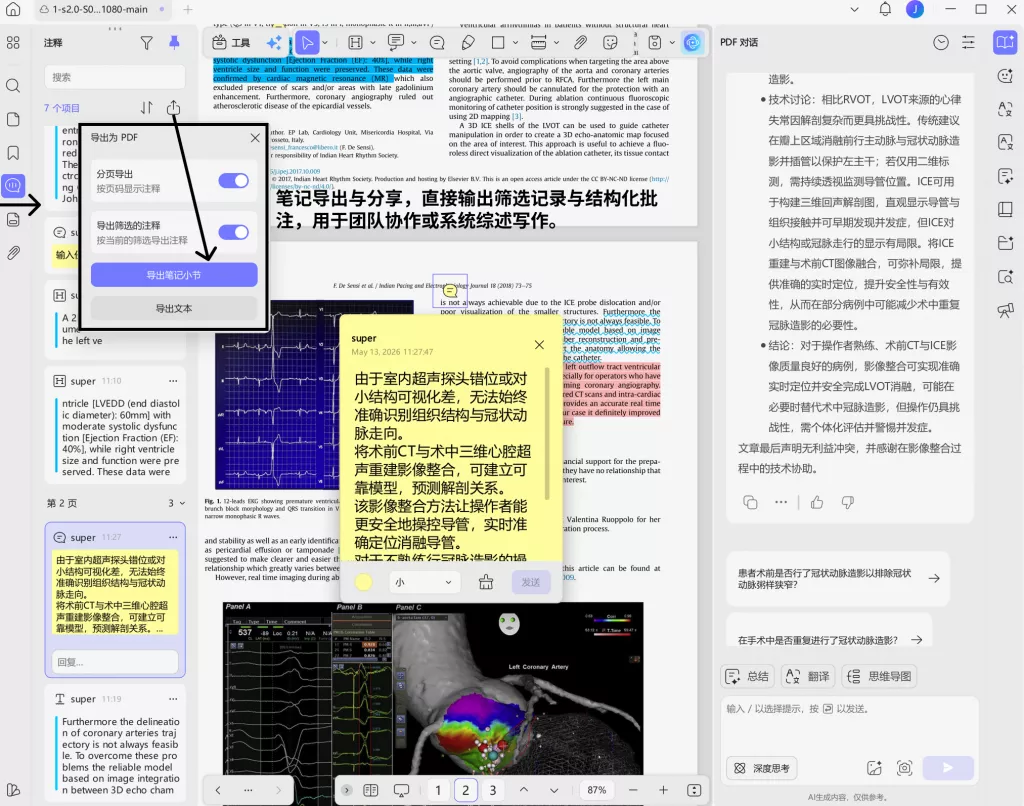
八、UPDF vs 传统 PRISMA 管理方式对比
| 方法 | 筛选记录方式 | 可追踪性 | 后期返工 |
| Excel补记录 | 后期整理 | 低 | 高 |
| 文献管理软件 | 仅状态管理 | 中 | 中 |
| UPDF结构化记录 | 文档内沉淀 | 高 | 低 |
可以看到,当筛选依据直接保留在文献结构中时,整个 PRISMA 流程会稳定很多。
九、结论
很多研究者会把 PRISMA 理解成一种论文格式,但实际上,它真正要求所有筛选都有依据、所有删除都有原因以及所有阶段都能回溯。
真正成熟的系统综述,并不是最后“画出一张 PRISMA 图”,而是整个筛选过程从检索开始,就始终保持透明、稳定与可复现。当筛选依据能够持续被记录与复盘时,PRISMA 才真正从“形式要求”,变成“结构化研究流程”。
FAQ
Q1:PRISMA 一定只能用于系统综述吗?
回答:不是,普通文献综述也可以参考其流程。
Q2:PRISMA 最容易出问题的是哪一步?
回答:通常是全文评估与排除理由记录。
Q3:如何高效管理 PRISMA 筛选流程?
回答:可结合 UPDF 的批注、结构化笔记与笔记导出功能进行记录。