AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













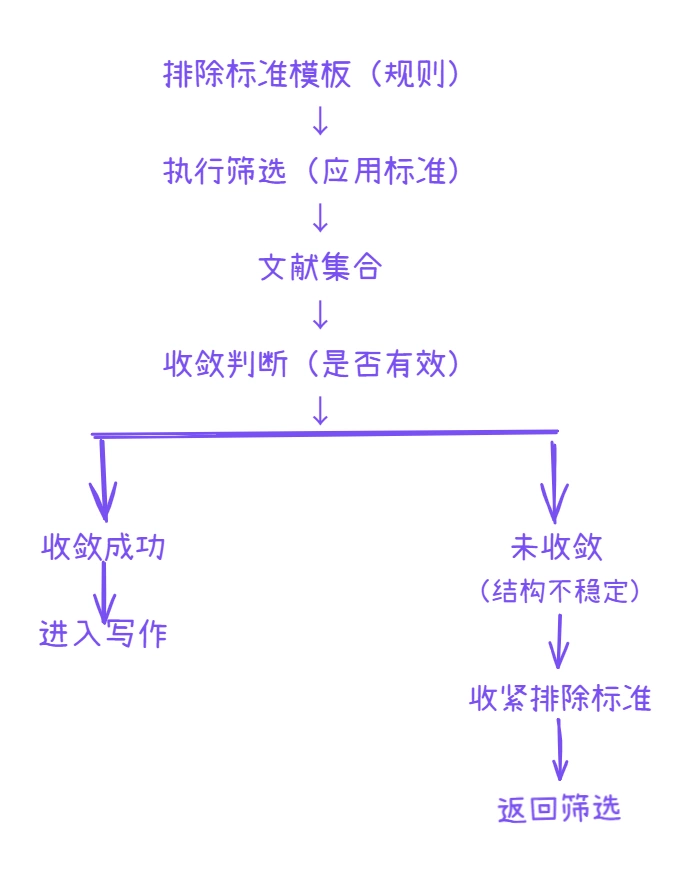
在文献综述或开题报告中,大多数研究者会较为重视“纳入标准”的表达,却往往忽视“排除标准”的系统设计。然而在实际操作中,如果缺乏清晰的排除标准,筛选过程很容易出现文献越筛越多,结构却越来越乱的问题。这并不是因为检索不精准,而是因为筛选缺乏边界约束。
从方法论角度来看,排除标准并不是纳入标准的补充,而是其对立结构。如果纳入标准解决的是“哪些文献可以进入研究框架”,那么排除标准解决的就是“哪些文献必须被明确剔除”。只有当这两个维度同时存在,筛选过程才具备真正的闭环逻辑。
在很多论文中,排除标准往往被简单处理为一句“排除与研究无关的文献”。这种表达的问题在于,它没有说明“无关如何定义”,也无法解释筛选决策的依据。因此,在严格意义上,这并不能算作方法部分,而只是结果描述。

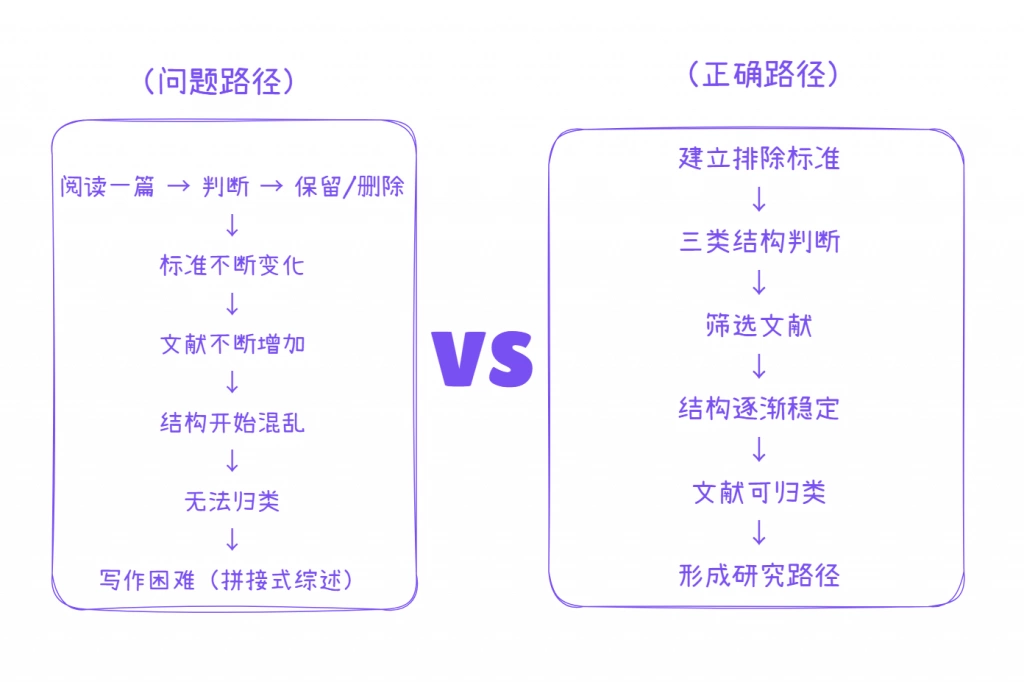
一、为什么没有排除标准,会导致“越筛越乱”
在缺乏排除标准的情况下,研究者通常依赖“阅读后判断”的方式进行筛选,即每读一篇文献,就临时决定是否保留。这种方式的本质,是将筛选决策分散到每一篇文献上,而不是基于统一规则进行判断。
这种操作方式会带来三个直接问题:
第一,筛选标准不一致。不同时间阅读的文献,可能基于不同判断标准被纳入或排除,从而导致文献集合内部缺乏统一逻辑。 第二,文献结构无法收敛。由于没有明确边界,许多“边缘相关”的文献会被保留下来,使得综述结构不断扩张。 第三,写作阶段难以组织。当文献之间缺乏共同变量结构或研究路径时,综述很容易呈现为拼接式叙述,而非逻辑递进。
排除标准的作用,不是减少文献数量,而是阻止研究结构失控扩张。换句话说,排除标准是一个“收敛机制”,用于确保筛选始终围绕同一研究路径展开。
二、排除标准的核心逻辑:不是删文献,而是划边界
要写好排除标准,首先需要理解一个关键问题:排除并不是针对“质量低的文献”,而是针对“结构不匹配的文献”。很多研究者在筛选时,会优先排除“方法不严谨”或“发表较早”的文献,但这些并不是核心逻辑。
真正需要优先排除的,是那些虽然看似相关,但在结构上无法进入研究框架的文献。通常可以从以下三个维度进行界定:
- 主题偏移
即文献虽然包含某个关键词,但研究重点与核心问题并不一致。例如,研究对象或问题导向不同,即使使用相同概念,也不应纳入。
- 变量关系不匹配
即文献中不存在与你研究一致或可对比的变量结构。例如,你关注因果关系,而该文献仅为描述性分析。
- 情境或方法不可比
即研究对象、样本或方法路径差异过大,导致其结论无法进入同一分析框架。
这三个维度的意义在于,将“排除”从一种模糊判断,转化为一个具有结构依据的决策过程,从而避免筛选过程中不断出现“看起来也可以留”的情况。
三、排除标准如何落地?
在实际操作中,排除标准应当在筛选流程中被前置,而不是在阅读之后才被使用。可以按照以下三步执行:
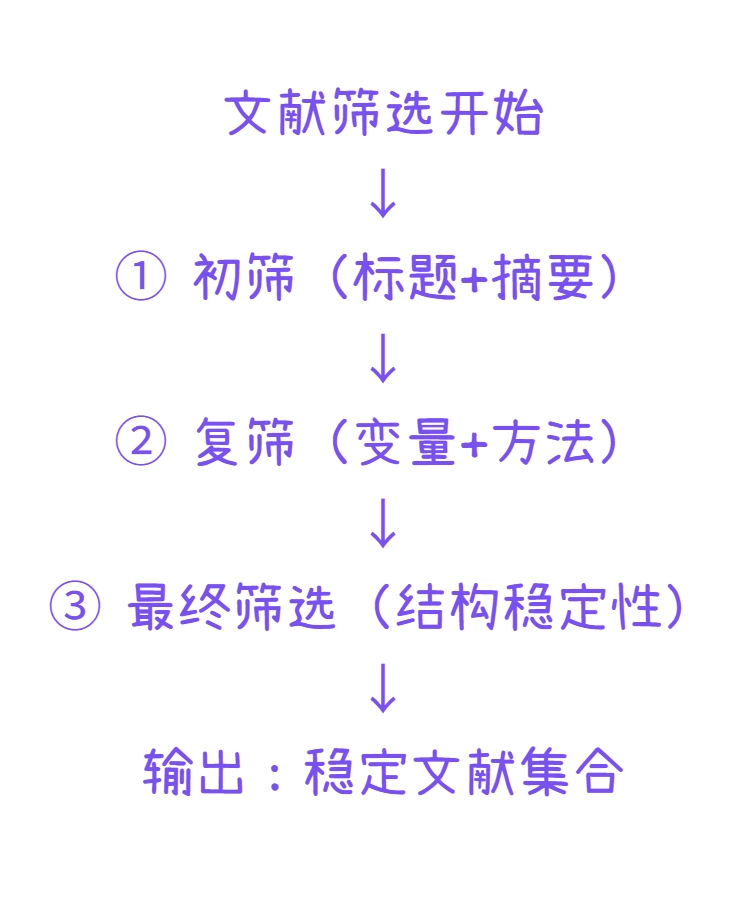
(1)初筛阶段:快速排除明显不匹配文献
在这一阶段,应基于标题与摘要进行判断,重点排除那些明显偏离主题或变量路径的研究。
在操作层面,可以通过批量导入文献并使用UPDF的AI总结功能,快速提取每篇文献的核心研究问题与变量关系,从而在不阅读全文的情况下判断其是否属于“主题偏移”或“变量不匹配”。这一步的关键,是用结构信息替代阅读判断,从而提高筛选效率。
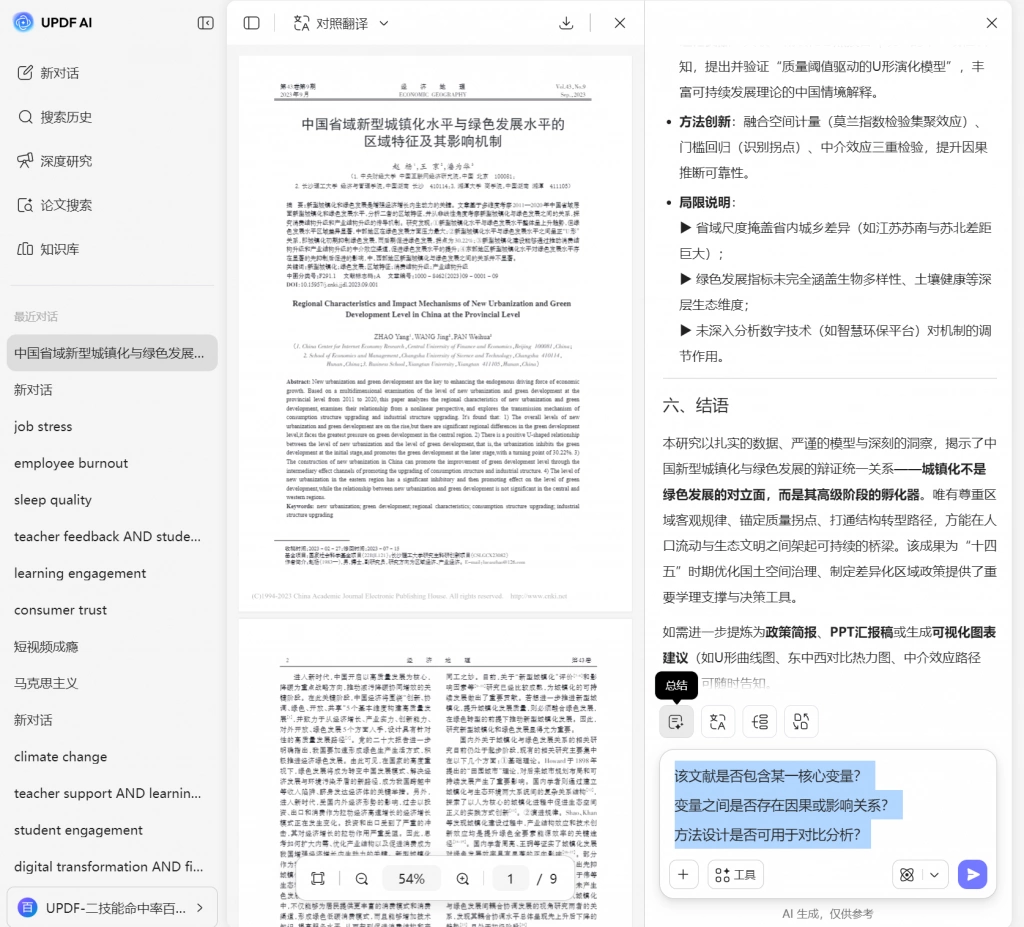
(2)复筛阶段:基于变量与方法进行排除
进入复筛阶段后,需要进一步判断文献是否在变量结构与方法路径上具备可比性。
此时可以借助UPDF的文档对话功能,针对具体问题进行定向提问,例如:
- 是否包含某一核心变量?
- 变量之间是否存在因果或影响关系?
- 方法设计是否可用于对比分析?
同时,通过注释功能可以标记出变量、方法与结论位置,从而避免在多篇文献之间重复查找。这一阶段的目标,是通过结构信息进行排除,而不是通过阅读感受进行判断。
(3)最终筛选:防止“边缘文献”进入结构
在完成复筛之后,仍需要进行一次整体检查,重点识别那些“看似相关但结构不稳定”的文献。这类文献往往是导致综述结构松散的主要来源。
在这一阶段,可以利用UPDF的多文档对照阅读与知识库功能,将文献按变量结构进行分类,如果某一文献无法明确归入任何一类,则应优先考虑排除。这种方式可以从整体结构出发,而不是单篇判断。
四、可直接套用的排除标准模板
在论文或开题报告中,可以使用如下表达:
文献筛选排除标准说明:
在完成文献检索与初步筛选后,本研究依据明确的排除标准对文献进行进一步筛选。排除标准包括:
(1)与研究主题不直接相关的文献;
(2)未涉及本研究核心变量关系的文献;
(3)研究对象或情境与本研究差异较大的文献;
(4)方法设计无法支持变量关系分析的文献;
(5)重复发表或信息不足的文献。
通过上述标准,对文献进行系统排除,以确保纳入文献具备一致的研究结构。
这一模板的关键,在于将排除标准具体化,使筛选过程具有方法论上的可解释性,而不是停留在经验判断。
五、如何判断排除是否有效?
排除标准是否有效,可以通过以下三个信号进行判断:
- 文献集合开始呈现稳定的变量结构
- 不同文献之间具有较高可比性
- 文献可以自然归入同一研究路径
如果在筛选后仍然出现“主题一致但路径混乱”的情况,说明排除标准仍不够明确,需要进一步收紧边界。
FAQ
1️⃣ 排除标准必须写吗?
必须写,是方法部分的重要组成。
2️⃣ 排除是不是等于删掉质量差文献?
不是,核心是结构不匹配。
3️⃣ 排除标准可以很简单吗?
可以,但必须清晰具体。
4️⃣ 为什么会越筛越乱?
因为没有明确边界。
总结
从整体来看,文献筛选中的排除标准,并不是一个附加说明,而是决定研究边界的核心机制。只有当排除标准与纳入标准形成对称结构时,筛选过程才真正具备方法论意义。好的排除,不是删掉更多,而是防止结构失控。