 AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南












在进行文献综述、论文开题或研究选题时,“经典文献”几乎是绕不开的一类资源。很多人在使用 Google Scholar、Web of Science 或 Scopus 进行检索时,都会遇到一个常见困惑:引用量高的就是经典吗?发表时间久的就一定重要吗?
事实上,如果没有一套稳定的判断标准,所谓“经典文献”很容易变成一种模糊标签,导致筛选过程中要么过度依赖引用量,要么被时间维度误导,最终纳入的文献结构看似完整,却缺乏真正的支撑力。
本文将介绍如何在大量文献中,快速且稳定地识别“真正值得反复阅读”的经典文献,并进一步拆解一套可以实际执行的判断路径,让筛选过程从经验判断转向结构判断。

一、为什么“经典文献”经常被误判?
在多数检索场景中,人们对“经典”的判断往往依赖两个最直观的指标:引用次数和发表年份。例如,在 Google Scholar 中按照“被引用次数”排序,或在 Web of Science 中筛选早期高被引文献。这种方式在信息不足时确实可以提供一个初步参考,但问题在于,它忽略了一个更关键的维度——结构价值。
引用量高的文献,并不一定是因为它构建了研究路径,也可能只是因为它总结得较好,或者在某一阶段被大量引用。而发表时间较早的文献,也不一定具有持续影响力,有些研究只是历史节点,而不是结构核心。
更重要的是,当你只依赖这些外部指标时,筛选逻辑就会变得不可控。同一批文献,不同的人可能因为排序方式不同,得到完全不同的“经典集合”。这也是为什么,很多人在写综述时会感觉“文献很多,但结构不稳”。
真正的问题不在于你找不到经典文献,而在于你缺少一套可以稳定复现的判断标准。
二、什么样的文献,才值得被称为“经典”?
如果从研究结构的角度来看,一篇文献之所以成为经典,并不是因为它“被引用很多”,而是因为它在某个研究路径中起到了“不可替代”的作用。这种作用通常体现在三个层面:它是否定义了关键变量,它是否建立了核心关系,以及它是否影响了后续研究的展开方式。
这意味着,判断经典文献时,你需要关注的不是“它有多热门”,而是“它在结构中扮演什么角色”。当一篇文献可以反复被引用,不是因为它写得清晰,而是因为后续研究必须基于它展开时,它才真正具备“必读价值”。
三、3 个核心信号,帮你快速识别“必读文献”
在实际筛选过程中,你不需要逐篇阅读全文来判断是否经典。只要抓住几个关键结构信号,就可以在较短时间内完成判断。
信号一:是否被反复作为“起点引用”
在 Google Scholar 或 Scopus 中查看引用情况时,你会发现有些文献虽然引用量很高,但更多是被作为“背景引用”,而不是研究起点。而真正的经典文献,往往在后续研究中被反复作为理论基础或方法来源。
判断方法并不复杂,你可以进入引用列表,观察引用它的文献是否在方法或理论部分提及它。如果一篇文献频繁出现在“we build on…”或“based on…”这样的语境中,说明它不仅被引用,而且被用作研究起点。
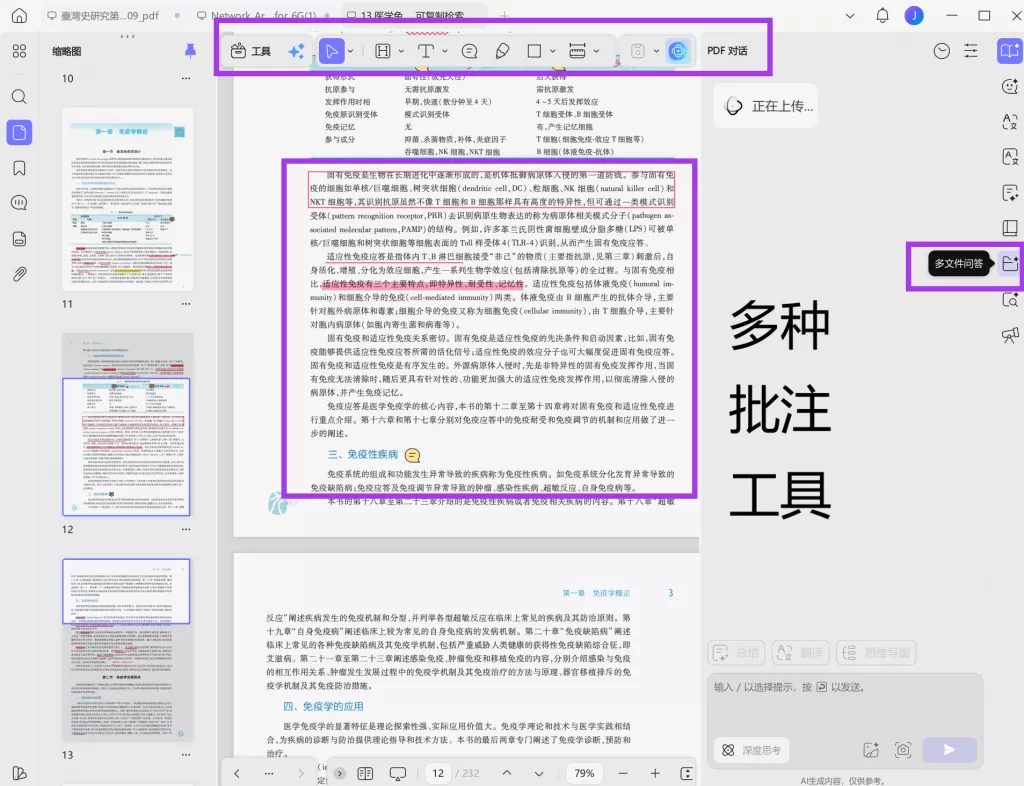
在这个阶段,如果借助 UPDF 的跨文献阅读与批注功能,将多篇引用同一文献的论文放在一起对比,并标记其引用位置,你会更容易识别哪些文献是真正的“结构节点”,而不是单纯的高被引文章。
信号二:是否定义了变量或研究框架
经典文献的第二个特征,是它在研究中承担了“定义角色”。很多后续研究之所以引用它,是因为它提供了一个被广泛接受的变量定义、测量方式或分析框架。
在 Web of Science 或 PubMed 中检索时,如果你发现某个变量的表达方式在多篇文献中高度一致,而这些表达都可以追溯到同一篇文献,那么这篇文献通常具有较强的经典属性。
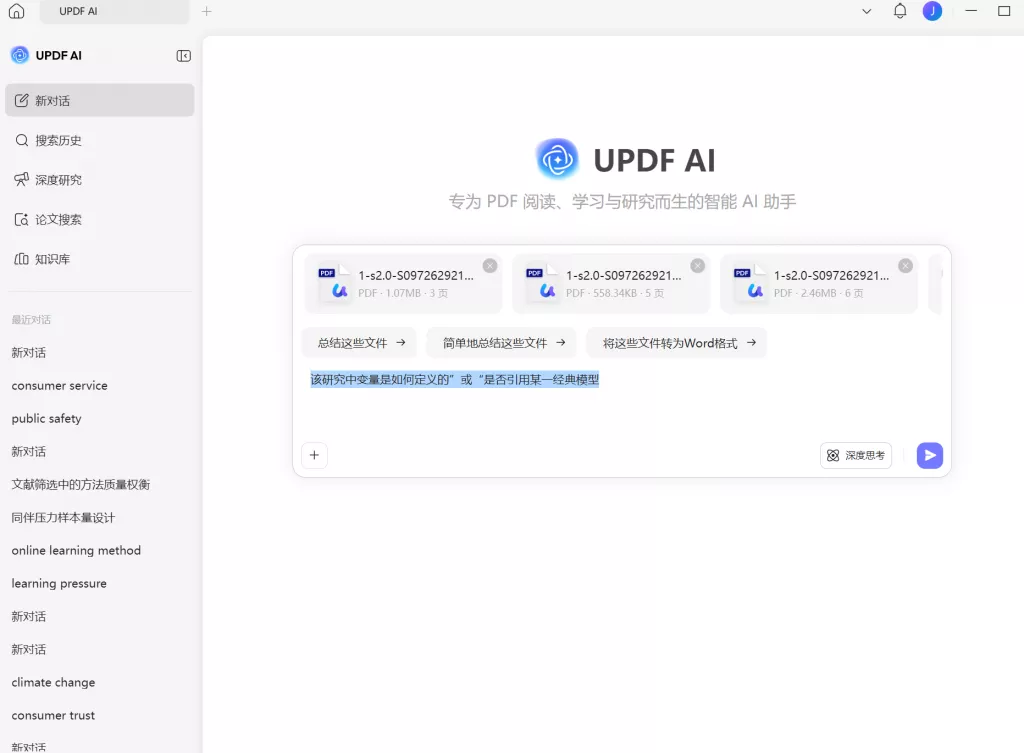
在实际操作中,你可以将几篇相关文献导入 UPDF,通过AI对话功能直接提问,例如“该研究中变量是如何定义的”或“是否引用某一经典模型”,系统可以快速定位相关内容。这种方式可以大幅减少你在全文中反复查找定义的时间,同时让变量来源更加清晰。
信号三:是否影响了研究路径的分支发展
真正的经典文献,往往不仅影响一篇研究,而是会引出多个研究分支。在 Scopus 或 Web of Science 的引用网络中,你可以观察到某些文献被不同方向的研究同时引用,这说明它在结构中具有较强的扩展能力。
相比之下,一些文献虽然引用量不低,但引用集中在单一方向,这类文献更接近“阶段性成果”,而不是“路径节点”。
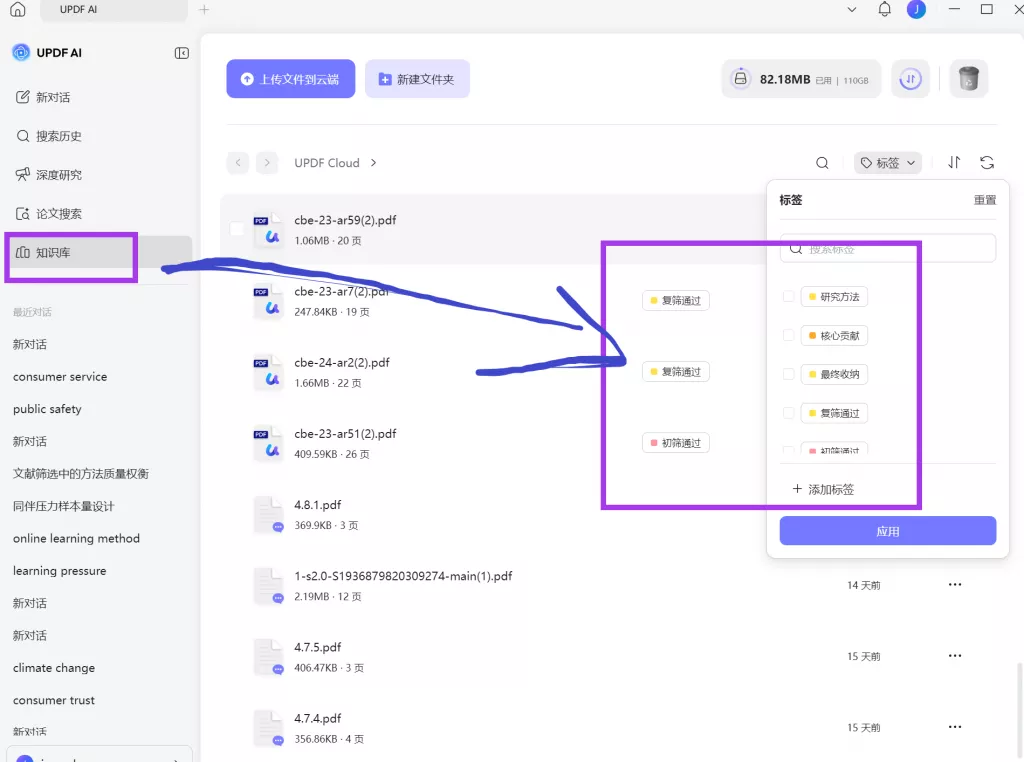
在这一阶段,可以结合 UPDF 的知识库功能,将引用同一文献的研究按主题进行分类,从而直观地看到它是否支撑了多个研究方向。当一篇文献能够连接多个路径时,它的“必读价值”会显著提升。
四、快速判断经典文献的对比方法
为了让判断更加直观,可以将“伪经典文献”与“真正经典文献”进行对比:
| 判断维度 | 伪经典文献 | 真正经典文献 |
| 引用方式 | 多为背景引用 | 多为理论或方法起点 |
| 变量角色 | 被引用但不统一 | 定义核心变量或框架 |
| 影响范围 | 单一路径引用 | 多路径分支引用 |
| 时间特征 | 可能集中在某阶段 | 持续被不同阶段引用 |
| 使用价值 | 可参考 | 必须理解 |
这个对比可以帮助你在筛选时快速判断:一篇文献是否只是“常见”,还是“不可替代”。
五、结合工具的实操流程
为了让判断过程更加稳定,可以按照以下步骤进行:
第一步,在 Google Scholar 或 Web of Science 中检索核心问题,并筛选出高引用文献。
第二步,进入引用网络,观察这些文献在后续研究中的使用方式,而不是只看引用数量。
第三步,将候选文献导入 UPDF,通过AI总结快速提取研究问题、变量定义和方法路径。

第四步,使用对话功能验证关键问题,例如变量来源、模型结构或引用语境。
第五步,通过批注或标签,对文献进行“结构角色标记”,区分起点文献与补充文献。
通过这一流程,你不再依赖单一指标,而是基于结构信息进行判断,从而让“经典文献”的识别变得可复现。
六、为什么 UPDF 更适合做“经典文献识别”?
在传统筛选过程中,判断一篇文献是否经典,往往需要反复在不同平台之间切换,例如在 Google Scholar 查看引用,在 PDF 中查找定义,再在其他文献中验证引用关系。这种方式不仅耗时,而且容易遗漏关键信息。
而在 UPDF 中,这些步骤可以被整合到同一环境中完成。你可以直接对PDF进行提问,快速获取变量定义与研究路径;可以通过批注标记其结构角色;也可以在多文献之间进行对比,从而判断其影响范围。

这种方式的核心优势在于,它把原本分散的判断过程,转化为一个连续的结构分析过程,使你在筛选时不再依赖直觉,而是基于清晰的证据进行判断。
七、FAQ
Q1:引用量高的文献一定是经典吗?
不一定,还需看其结构作用。
Q2:经典文献一定很早发表吗?
不一定,关键在于影响路径。
Q3:如何更快识别经典文献?
可结合 UPDF 的结构提取与多文献对比功能进行判断。
总结
在文献综述中,真正重要的并不是找到最多的文献,而是找到那些能够支撑结构的文献。经典文献之所以值得反复阅读,并不是因为它们“更有名”,而是因为它们在研究路径中承担了不可替代的角色。当你从“看引用量”转向“看结构角色”,经典文献的识别就会从模糊判断,变成一件可以稳定执行的操作。



