AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

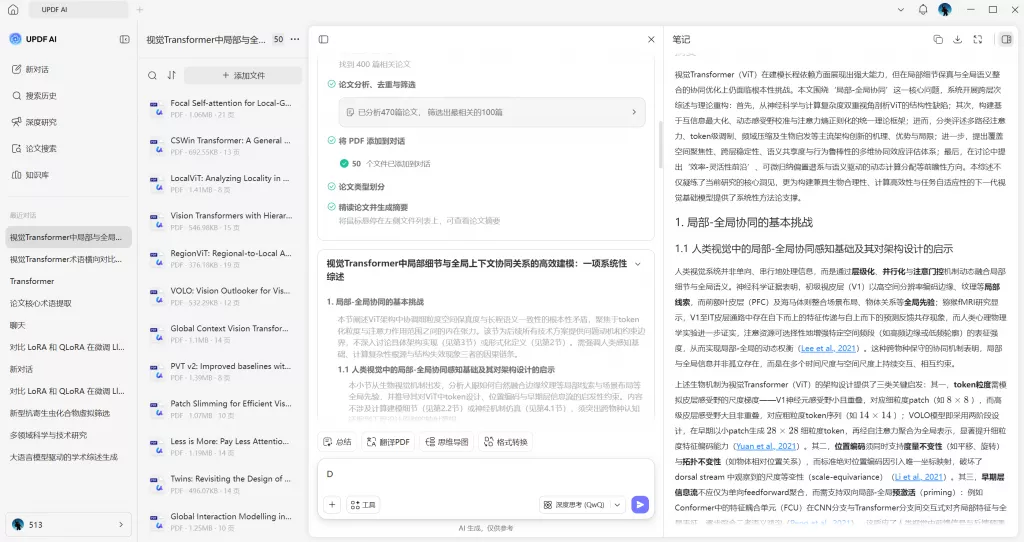
 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
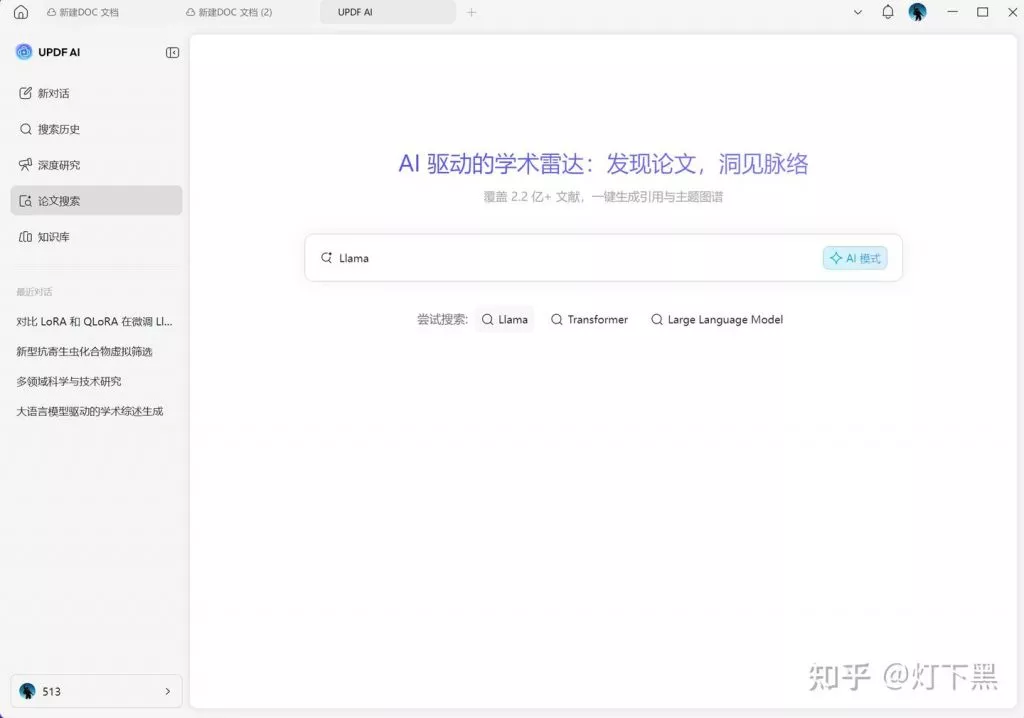
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南












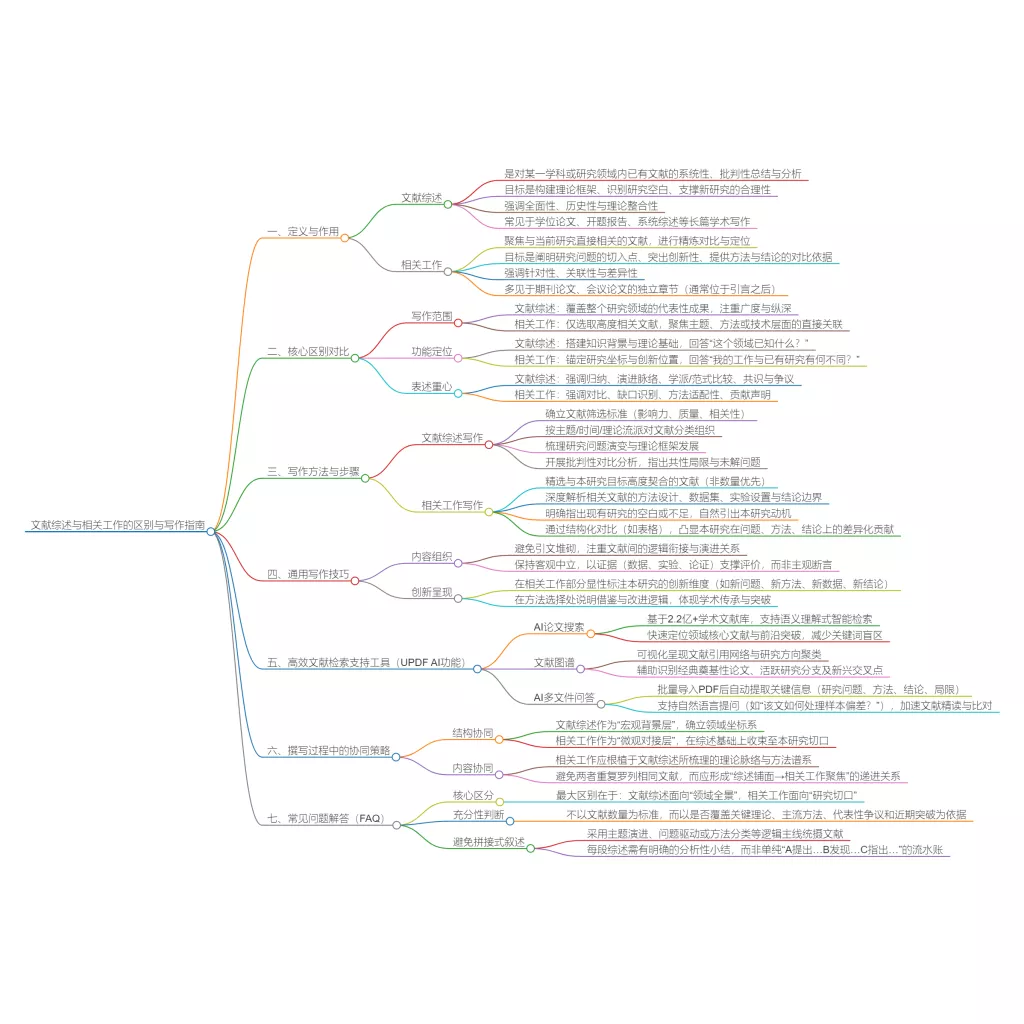
在文献综述写作过程中,很多研究者都会遇到一种非常典型的问题:某些研究虽然“看起来相关”,但真正深入阅读之后,却会发现样本量很小、方法不够稳定、变量定义模糊或者研究结论缺乏重复验证。
这类研究并不一定“错误”,但它们往往属于典型的“弱证据”。很多研究者第一次写综述时,容易出现两个极端。要么把所有文献全部纳入,要么直接删除“质量不高”的研究。
但实际上,真正成熟的文献综述,并不会简单“保留”或“删除”弱证据,而是会进一步分析:
- 这些研究为什么会形成弱证据;
- 它们是否仍然具有参考价值;
- 哪些结论目前仍然缺乏稳定支撑。
因为学术研究真正重要的,并不是“所有结论都一致”,而是:
- 哪些观点已经形成强证据;
- 哪些研究仍然停留在探索阶段;
- 当前领域真正的不确定性在哪里。
高质量的文献综述,并不是只展示“强研究”,而是能够合理处理研究中的弱证据与不稳定结论。

一、为什么很多综述会“错误使用弱证据”
在实际阅读过程中,很多研究者会先从 Scopus、OpenAlex 或 Semantic Scholar 中找到相关研究,然后逐篇阅读与整理。
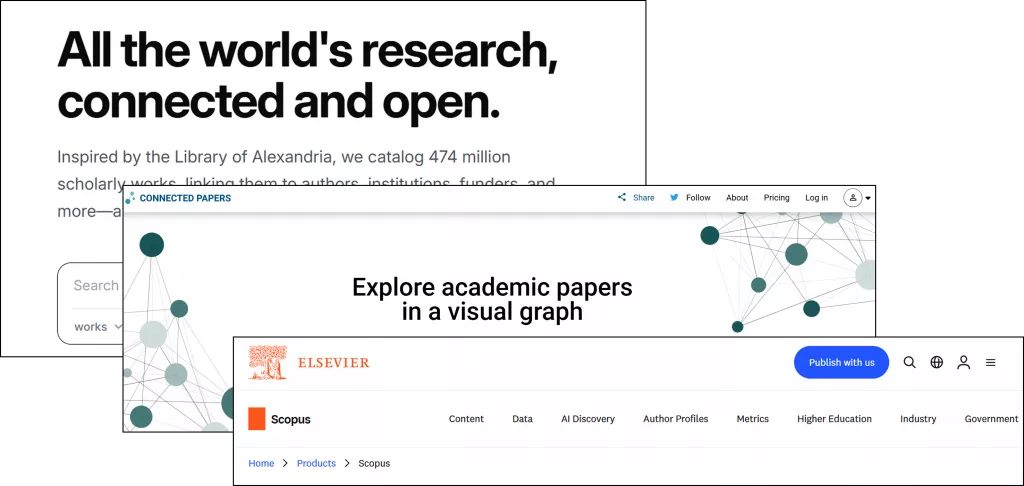
这种方式本身没有问题,但很多人后续会自然进入一种“只看结果”的状态,结果就是弱证据被直接当成稳定结论。
例如,同样研究用户持续使用行为:
- 有些研究基于几百份样本;
- 有些研究只使用十几位访谈对象;
- 有些研究甚至没有稳定变量控制。
如果这些研究被全部放在同一层级讨论,那么综述本身就会失去研究可信度。
二、弱证据真正“弱”在哪里
很多研究者第一次接触“弱证据”时,会误以为它只是“研究质量差”。但实际上,弱证据真正的问题,通常在于:
- 证据稳定性不足;
- 研究缺乏重复验证;
- 研究边界不清晰。
例如:
| 强证据研究 | 弱证据研究 |
| 样本量较稳定 | 样本规模过小 |
| 方法路径清晰 | 方法过程模糊 |
| 变量定义明确 | 变量边界不稳定 |
| 多研究重复验证 | 结论缺乏后续支持 |
因此,真正成熟的综述,并不会简单把弱证据“删掉”,而是会进一步分析:
- 当前研究为什么仍然缺乏稳定支持;
- 哪些结论仍然属于探索阶段;
- 哪些研究未来需要继续验证。
三、为什么很多人“看得到论文,看不到证据强弱”
很多研究者的问题在于:虽然已经阅读了大量论文,但脑子里依然只有“研究结论”。
例如:
- 知道每篇论文支持什么观点;
- 却不知道哪些研究可信度更高;
- 不知道哪些结论只是初步发现;
- 不知道哪些变量仍然缺乏稳定验证。
这种问题本质上并不是阅读不够,而是没有建立“证据层级”。
例如,有些研究虽然结论新颖,但方法路径不稳定;有些研究虽然结果不突出,但经过大量重复验证,因此反而更可靠。如果始终停留在“结论层”,那么综述一定会越来越像“观点拼接”。
四、为什么“AI总结”比“手动摘录”更容易发现弱证据
很多研究者后期会不断增加阅读量,希望通过“读更多论文”提高综述质量。但实际上,如果始终停留在手动摘录层面,那么即使阅读再多论文,也很难真正识别弱证据。
因为真正成熟的证据分析,并不是只记录研究结果或者只整理研究观点,而是能够快速提炼:
- 样本规模是否稳定;
- 方法路径是否清晰;
- 变量定义是否一致;
- 研究是否被后续重复验证。
在这一阶段,我现在已经不会再单纯依赖传统笔记,而是会直接使用 UPDF AI 的 AI总结功能,对论文中的研究方法、样本来源、变量结构、局限性部分等等进行快速提炼。

例如,我通常会优先让 UPDF AI 总结:
- 当前研究的主要限制;
- 是否存在样本不足;
- 是否缺乏变量控制;
- 哪些结论仍然需要进一步验证。
这种方式最大的价值,在于能够快速从“研究结果”进入“证据质量”。
五、为什么“知识库”能帮助建立证据层级
很多研究者的问题其实并不是不会阅读,而是读完论文之后,研究质量无法长期区分。例如:
- 哪些研究属于核心证据;
- 哪些研究只是初步探索;
- 哪些变量已经形成稳定支持;
- 哪些方向仍然缺乏验证。
这种问题本质上是因为:研究关系没有被长期沉淀。
在这一阶段,我通常会进一步通过 UPDF AI 的知识库功能,把不同研究按照“证据等级”长期整理。
| 普通整理方式 | 使用知识库后 |
| 所有论文混在一起 | 研究层级更清晰 |
| 很难区分证据强弱 | 核心研究更明确 |
| 后期容易重复阅读 | 研究路径更稳定 |
| 综述结构容易混乱 | 更容易建立证据链 |
相比传统文件夹管理,知识库最大的优势,在于能够长期保留研究质量结构,而不仅仅只是保存PDF。
很多人处理不好弱证据,并不是因为不会写,而是因为研究层级没有被真正建立。
六、如何避免“过度否定弱证据”
很多研究者在学会区分强弱证据之后,还会出现另一个问题:开始过度排斥弱证据。
例如:
- 直接删除探索性研究;
- 只保留成熟结论;
- 忽略新方向中的早期研究。
结果就是,综述虽然“很稳定”,但研究前沿反而消失了。
因此,在处理弱证据时,真正重要的并不是“全部删除”,而是:
- 哪些研究虽然不稳定,但具有探索价值;
- 哪些结论仍然值得继续验证;
- 哪些方向可能正在形成新路径。
真正成熟的综述,通常会同时保留强证据结构、弱证据结构和前沿探索结构。
七、操作步骤:如何处理弱证据
第一步,先按研究问题整理核心文献;
第二步,通过 UPDF AI 的 AI总结提炼研究局限性;
第三步,比较样本、变量与方法稳定性;
第四步,将不同研究按证据等级整理进 UPDF AI 的知识库;
第五步,再围绕“证据强弱”而不是“单篇论文”展开综述写作。
八、总结
很多文献综述之所以缺乏研究深度,真正的问题并不在于论文数量,而在于没有建立证据层级。如果综述始终停留在“观点整理”层面,那么即使阅读再多论文,内容依然会越来越混乱;而当研究者开始从“证据强弱”而不是“单篇结论”观察文献时,综述才会真正形成研究层次。在实际写作中,通过 UPDF AI 的 AI总结与知识库能力,可以更高效地识别弱证据,从而帮助研究者建立更稳定的研究结构。
常见问题
Q1: 弱证据是不是一定不能引用?
回答:不是,关键是说明其研究边界。
Q2: 为什么很多综述缺乏证据层级?
回答:因为只关注研究结果,没有分析研究质量。
Q3: 如何快速识别弱证据?
回答:用 UPDF AI 的 AI总结与知识库分析研究结构。