AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南












在系统综述、Meta 分析或正式学术综述中,“纳入/排除标准”几乎是决定研究质量的核心部分。很多研究者在使用数据库完成文献检索后,会发现文献数量虽然已经缩小,但真正进入系统综述时,筛选逻辑却越来越混乱。
例如:
- 为什么这篇研究被保留?
- 为什么另一篇被删除?
- 两篇主题相似的论文,为什么处理结果不同?
- 后期写方法部分时,为什么已经说不清筛选依据?
这些问题,本质上都指向同一个核心:筛选过程缺少“结构化记录”。
很多人会把纳入/排除表理解成“最后补写的一张表格”,但实际上,它应该贯穿整个筛选流程。真正专业的系统综述,并不是最后留下多少篇文献,而是整个筛选过程是否具备透明性、可追踪性与可复现性。纳入/排除表真正重要的,并不是“形式完整”,而是让所有筛选判断都有明确依据。

一、什么是纳入/排除表?为什么系统综述一定要写?
在普通综述中,即使筛选逻辑不够明确,通常也不会立刻暴露问题;但在系统综述中,如果没有明确的纳入/排除标准,整个研究会失去可信度。
因为系统综述最核心的特点,并不是“文献多”,而是筛选过程公开、判断逻辑一致和结果能够复现。因此,研究者必须明确说明什么文献被纳入、什么文献被排除、为什么这样判断。
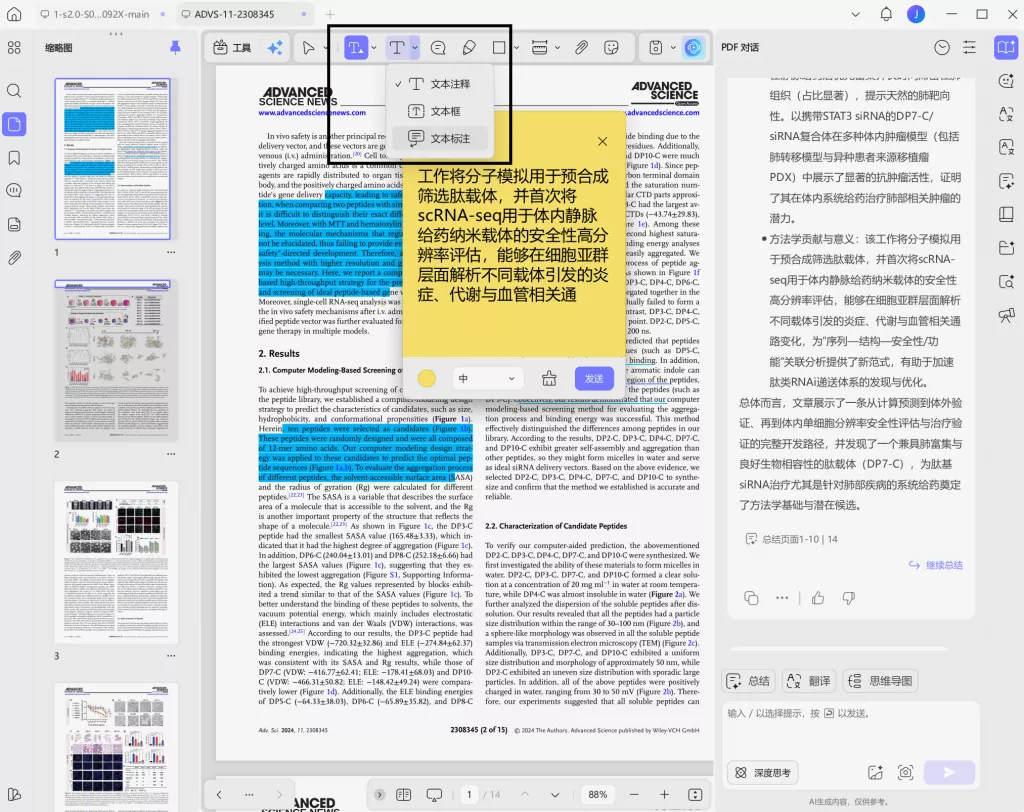
例如,在实际筛选中,很多研究者会直接在 PDF 中通过批注记录“变量不匹配”或“方法不可比”等原因,而不是后期再凭记忆补写。像 UPDF 这种支持批注与高亮的工具,在初筛阶段就能直接保留筛选依据,后续整理纳入/排除表时会轻松很多。
二、纳入标准与排除标准有什么区别?
很多人在写系统综述时,会把“纳入标准”和“排除标准”混在一起,导致规则越来越模糊。
实际上,两者承担的是不同角色:
| 类型 | 核心作用 | 重点问题 |
| 纳入标准 | 建立研究边界 | 什么可以进入研究 |
| 排除标准 | 减少结构噪音 | 什么必须被删除 |
简单来说:
- 纳入标准负责“确定范围”
- 排除标准负责“控制质量”
如果只有纳入标准,文献数量通常会不断膨胀;如果只有排除标准,则容易导致研究边界不清。
三、系统综述最常见的纳入标准
在正式写法中,纳入标准通常围绕以下几个维度展开:
| 维度 | 常见写法 |
| 研究对象 | 纳入成年人群研究 |
| 研究主题 | 纳入 AI 教育相关研究 |
| 研究类型 | 纳入实证研究 |
| 时间范围 | 纳入近10年研究 |
| 数据完整性 | 纳入提供完整方法与结果的研究 |
| 文献语言 | 纳入中文与英文研究 |
例如:
本研究纳入标准包括:研究对象为高校学生;研究主题涉及 AI 辅助学习;研究类型为实证研究;研究发表于2015—2025年之间;全文可获取并包含完整研究方法。
这种写法的重点不是“复杂”,而是任何研究者都能按同一规则执行。
四、排除标准应该怎么写才专业?
相比纳入标准,很多人的排除标准更容易出现问题。例如质量较低、不够相关,这些表达看似合理,但实际上完全不可执行,因为不同人会有不同理解。
更规范的写法通常会直接对应结构问题:
| 问题类型 | 更专业写法 |
| 变量不符 | 排除未涉及核心变量的研究 |
| 方法不符 | 排除非实证研究 |
| 数据不足 | 排除缺少完整结果数据的研究 |
| 重复文献 | 排除重复发表研究 |
| 研究对象不符 | 排除非目标群体研究 |
例如:
排除标准包括:未形成变量关系的研究;缺少完整方法描述的研究;会议摘要或无全文研究;重复发表文献。
在实际筛选中,如果研究者已经提前通过 PDF 批注记录“排除原因”,后续整理这些内容时会明显更高效,而不需要重新翻阅全部文献。
五、为什么很多纳入/排除表“看起来专业”,但实际上无法执行?
很多系统综述的问题,并不是没有标准,而是标准无法真正落地,例如保留高质量研究和删除低相关文献。
这些说法的问题在于没有明确判断依据。真正有效的纳入/排除标准,即使换一个研究者重新筛选,也能得到相近结果。
因此,真正重要的并不是“写得学术”,而是是否可判断、是否可执行以及是否可复现。
六、纳入/排除表应该什么时候建立?
很多研究者会等筛选完成之后,再回头整理纳入/排除标准,但这种方式很容易出现“倒推逻辑”。
正确顺序应该是:
- 明确研究问题
- 建立纳入/排除标准
- 正式开始筛选
- 持续记录筛选依据
因为只有规则先固定,后续筛选才会稳定。
在实际操作中,很多人会在筛选过程中不断修改标准,但如果这些变化没有被记录,后期就很难解释为什么前后标准不同。因此,在筛选阶段直接保留结构化记录,会明显减少后期返工。
七、如何让纳入/排除标准真正“可复盘”?
系统综述最大的难点之一,并不是筛选,而是后期复盘。
例如:
- 为什么某篇高引用文献被删除?
- 为什么某类方法体系没有纳入?
- 为什么研究边界后来发生变化?
如果这些问题无法回答,整个系统综述的可信度就会下降。
因此,很多正式研究会要求:
- 保存筛选记录
- 保存排除原因
- 保存阶段修改过程
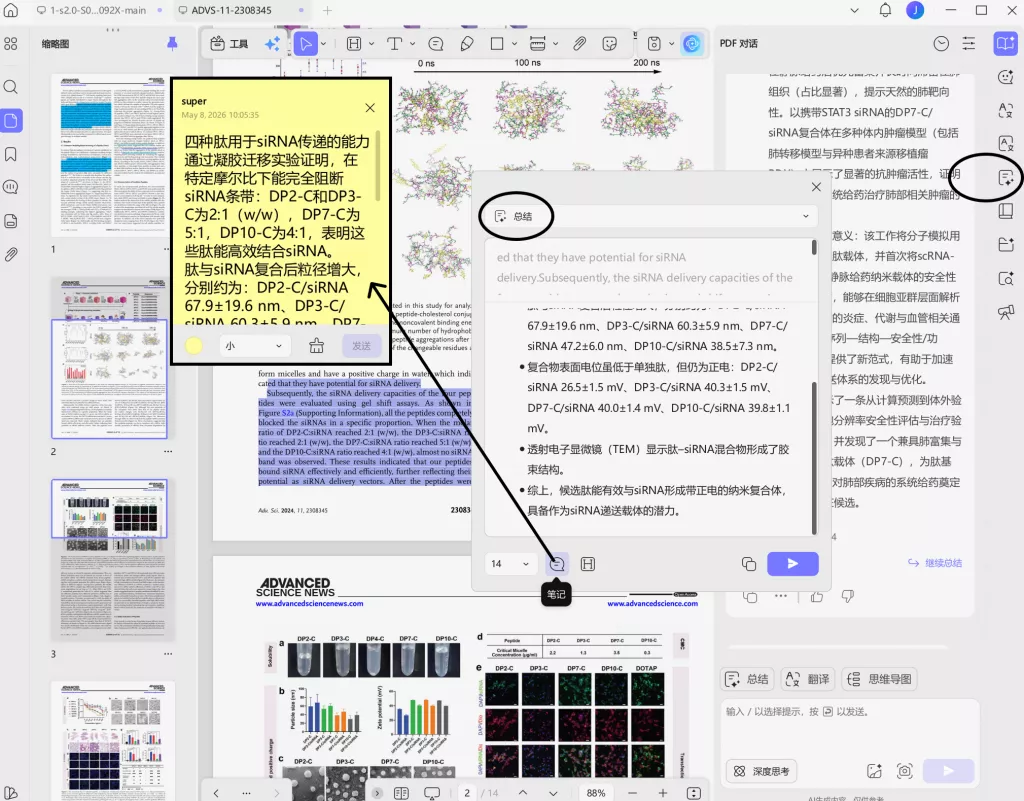
在这一点上,如果前期已经通过批注记录筛选依据,并进一步生成结构化笔记,后期整理方法部分时会轻松很多。例如,UPDF 的 AI 生成批注总结功能,就更适合把零散筛选依据自动整理成结构化内容,而不是后期手动重新归纳。
八、结合 UPDF 的纳入/排除表整理流程(核心实操)
在系统综述场景下,UPDF 更适合承担的角色,并不是 PDF 阅读器,而是帮助研究者持续沉淀筛选依据。
一个更稳定的实际流程通常是:
第一步,在数据库完成检索后,将候选文献统一导入 UPDF。
第二步,在初筛阶段,通过批注与高亮功能,直接标记变量、研究对象、方法问题或排除原因。
第三步,在中筛阶段,利用 AI 生成批注总结,将零散筛选依据自动整理为结构化内容。
第四步,将不同状态的文献分别归类,例如“已纳入” “待仲裁” “已排除”。
第五步,在系统综述写作阶段,通过笔记导出与分享,直接整理纳入/排除表与方法部分。
相比传统“后期补表格”的方式,这种方法最大的优势在于:筛选逻辑会随着研究过程自然沉淀,而不是最后重新回忆。
九、UPDF vs 传统纳入/排除整理方式对比
| 方法 | 筛选依据保存方式 | 可追踪性 | 后期整理成本 |
| Word手动整理 | 后期补写 | 低 | 高 |
| Excel记录 | 外部表格 | 中 | 中 |
| UPDF结构化记录 | 文档内沉淀 | 高 | 低 |
可以看到,当筛选依据直接保留在文献结构中时,后续系统综述写作会明显更加稳定。
十、结论
很多研究者会把纳入/排除表理解成系统综述中的“格式要求”,但实际上,它真正决定你的研究是否透明、你的筛选是否一致以及你的结论是否可信。
真正成熟的文献筛选,并不是“最后保留多少篇文献”,而是整个筛选过程始终基于稳定规则,并且能够被完整追溯。当筛选依据能够被持续记录、复盘与共享时,文献筛选才真正从“个人经验”,变成“结构化研究流程”。
FAQ
Q1:系统综述一定要写纳入/排除标准吗?
回答:是的,这是保证研究可复现的重要部分。
Q2:纳入/排除标准什么时候建立最好?
回答:建议在正式筛选前确定。
Q3:如何高效整理纳入/排除记录?
回答:可结合 UPDF 的批注、结构化笔记与笔记导出功能进行管理。