 AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南












在文献筛选逐渐深入之后,很多人发现一些论文在变量、关系和方法层面看起来完全符合研究需求,甚至在结果表达上也相当完整,但当你试图真正理解其分析路径,或者希望在自己的研究中进行复用时,却发现关键步骤无法被还原,数据处理逻辑不够透明,甚至连基本的实现路径都难以确认,这种“看起来合理但无法落地”的文献,一旦进入你的研究体系,就会在后续阶段不断放大不确定性。
这种问题的根源,并不在于论文质量本身,而在于筛选标准停留在“结构是否匹配”,却没有进一步进入“结构是否可被复现”的层面,而一旦这一维度缺失,你所构建的文献基础就更像是一个由结果拼接而成的集合,而不是一条可以被验证和复用的研究路径。当筛选标准从“是否相关”进一步推进到“是否可复现”时,你才真正开始筛掉那些无法被使用的研究。
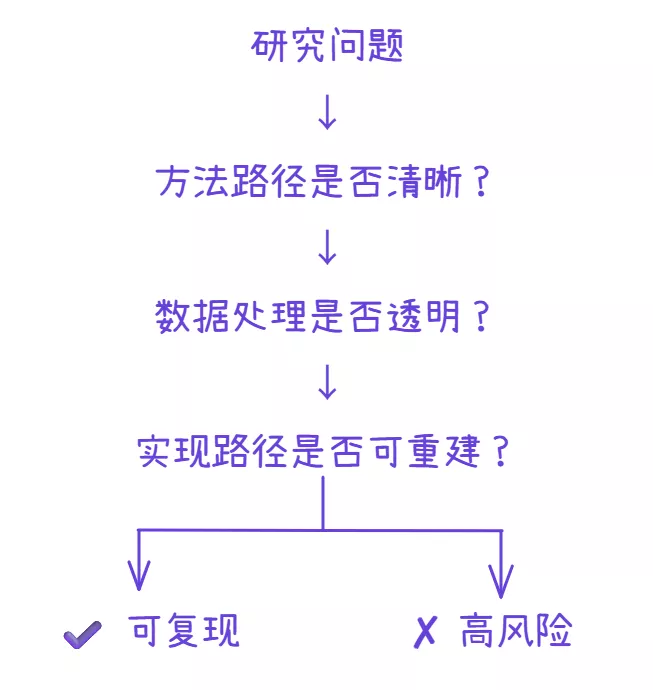
一、为什么可复现性很少进入筛选逻辑?
在常规的文献筛选流程中,大多数判断集中在研究问题、变量关系和方法类型这些较为直观的信息上,因为这些内容在标题、摘要甚至引言部分就可以被快速识别,也更容易形成统一标准,而可复现性则通常被视为更偏后期的问题,只有在真正进行实证或复现时才会被关注。
这种处理方式在早期阶段并不会产生明显问题,但随着文献数量增加,你会逐渐发现,仅仅依赖结构匹配所建立的文献体系,往往缺乏稳定性,因为不同研究在方法透明度、数据开放程度以及实现路径上的差异,会直接影响你对这些研究的理解深度和使用方式。
在实际操作中,很多人会借助 Google Scholar 或 Scopus 来构建文献池,通过关键词组合与引用关系不断扩展研究范围,这种方式在覆盖面上是高效的,但其本质仍然停留在“发现相关文献”,而无法帮助你判断这些文献是否具备可复现的研究路径,也就是说,你可以很快找到大量“看起来可用”的论文,却很难在筛选阶段区分哪些研究是可以真正被验证的。

这种差异在阅读过程中往往不会立刻显现,而是在后续写作或模型构建阶段才逐渐暴露出来,因为当你试图整合不同研究时,会发现有些论文无法提供足够的细节来支撑你的分析,这时再回头筛选,成本已经明显上升。
二、方法维度:路径是否清晰,决定你能否真正“跟着做一遍”
在判断可复现性时,方法是最基础的一层,因为它直接描述了研究从问题到结果的实现路径,而这一路径是否清晰,决定了你能否在不依赖作者额外说明的情况下重建分析过程。
很多论文在方法部分会提供整体框架,例如说明采用某种模型或分析技术,但关键问题往往出现在细节层面,例如变量如何处理、参数如何设定、步骤如何衔接,这些内容如果缺失,就会导致方法看似完整,却无法真正执行。
在筛选阶段,你不需要完全理解方法的所有技术细节,而是需要判断这条路径是否具备基本的可操作性,也就是说,当你按照论文描述进行推导时,是否能够形成一条连续的步骤链,而不会在关键环节出现断裂。
在实际操作中,如果完全依赖逐段阅读,很容易被技术细节分散注意力,因此更高效的方式,是先提取方法结构,例如在阅读PDF时,通过 UPDF AI总结功能,让系统先梳理出研究方法的核心流程与关键步骤,从而快速判断其路径是否完整,而不是在文本中自行拼接零散信息。
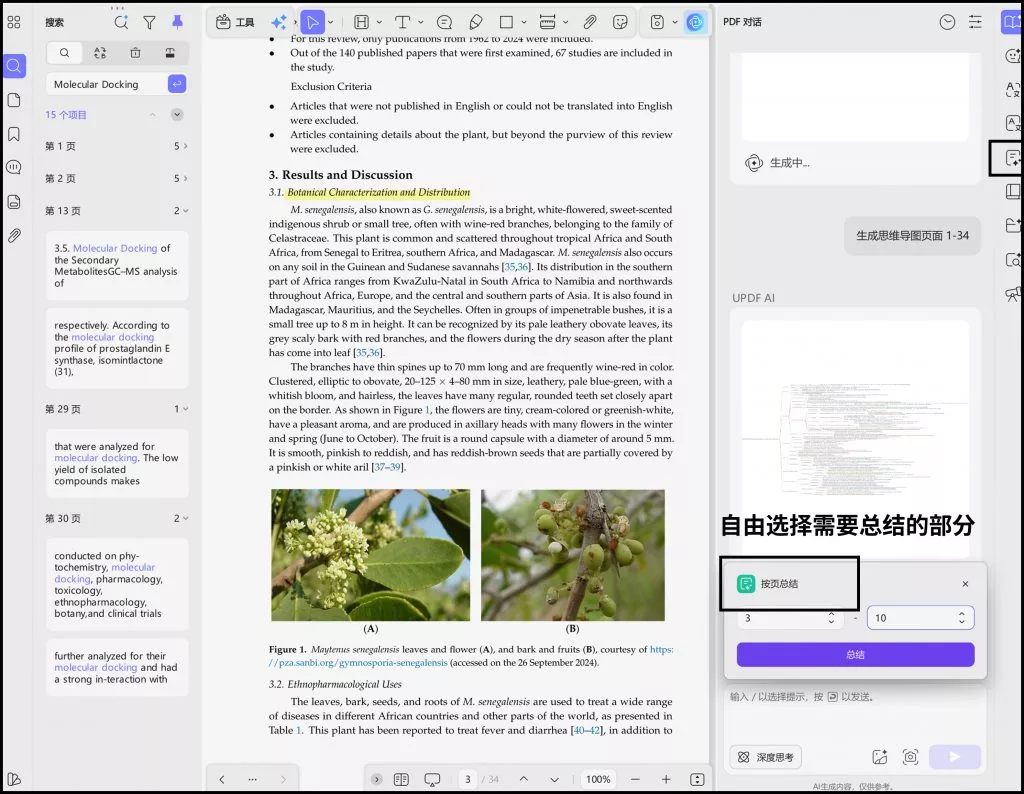
这种方式的关键,并不是减少理解,而是先建立结构,再决定是否需要深入细节。
三、数据维度:透明程度决定结果是否可以被验证
当方法路径具备基本清晰度之后,数据成为第二个关键判断维度,因为即使方法完全明确,如果数据来源或处理方式不透明,研究结果同样无法被验证。
数据问题之所以复杂,是因为它往往不会集中呈现,而是分散在不同部分之中,例如数据来源在方法中简要提及,样本筛选在附录中说明,变量构建在结果部分间接体现,这种分散表达,会让判断成本显著提高。
更重要的是,即使使用相同的数据来源,不同研究在数据清洗、筛选标准或变量构建上的差异,也可能导致结果出现明显变化,而如果这些过程没有被清晰表达,你即使获取了同一数据,也无法得到相同结论。
数据是否可复现,并不取决于是否公开,而取决于处理过程是否被充分表达并且可以被追溯。
在筛选过程中,可以通过关键词定位快速锁定数据相关内容,例如检索“dataset” “sample” “data collection”等表达,并结合工具进行结构提取,例如通过 UPDF 的跨页搜索快速聚合相关段落,再利用总结功能梳理数据处理路径,从而在较短时间内完成判断,而不是在全文中反复查找。
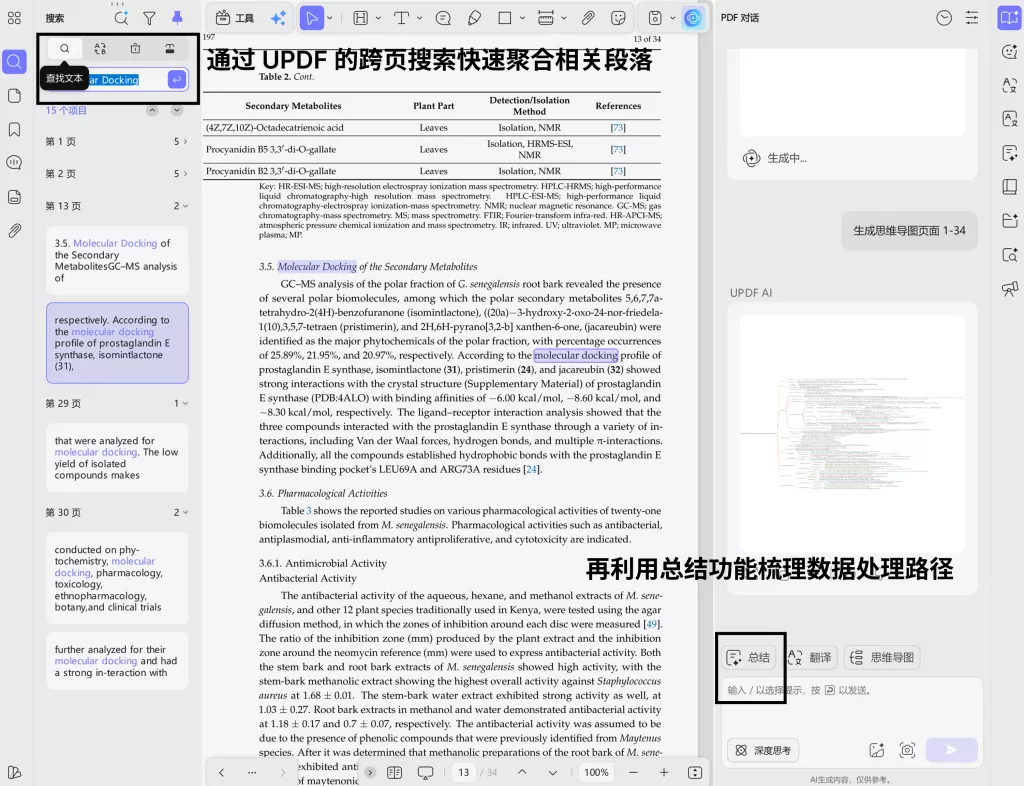
四、代码维度:实现路径是否可重建,决定复现成本
相比方法和数据,代码往往是最容易被忽视的一环,但在很多研究中,它实际上承担着将方法转化为结果的关键角色,因为即使方法逻辑清晰、数据来源明确,如果实现过程依赖特定代码,而这些代码不可获取或不可推导,那么复现成本就会显著上升。
在一些领域,论文会提供代码仓库或补充材料,这种情况下复现路径较为明确,但在更多情况下,研究并不会公开完整代码,而是通过方法描述间接呈现实现过程,这就要求你在筛选阶段判断,这些描述是否足以支持路径重建。
判断代码维度,并不是简单地看是否提供代码,而是要评估是否存在一条可推导的实现路径,也就是说,即使没有现成代码,你是否可以根据方法和数据逻辑,合理还原分析过程,如果这一点无法实现,那么这篇论文在实际使用中就会存在较高的不确定性。
在这一阶段,可以通过全文定位实现相关内容,例如检索“implementation” “algorithm”等表达,并结合结构提取工具快速判断实现逻辑,而不需要逐段阅读全部技术细节。
五、从三个维度到一条路径:可复现性本质是“能否走通”
当方法、数据和代码三个维度被同时纳入判断之后,你会发现可复现性并不是一个分散的指标,而是一条从研究问题到最终结果的连续路径,而筛选的关键,不在于逐一评估每个维度,而在于判断这条路径是否完整、是否连贯。
有些论文方法清晰但数据不透明,有些数据充分但实现路径模糊,还有些看似完整却在关键步骤上缺乏说明,这些情况都会导致路径中断,而一旦路径无法走通,这篇文献在你的研究体系中就只能作为参考,而难以作为支撑。
可复现性并不是“有没有细节”,而是是否存在一条可以被理解、跟随并重建的完整路径。
在实际筛选中,如果你已经通过前几个阶段锁定候选文献,可以结合结构提取工具对整篇论文进行快速解析,例如通过 UPDF 提取方法流程、数据路径和实现逻辑,再整体判断其可复现程度,这种方式可以显著减少在长文本中来回切换的成本。
六、筛选的稳定性,来自路径而不是结果
当可复现性被纳入筛选逻辑之后,你会发现筛选标准本身发生了变化,因为你不再仅仅依据研究结果或表达来判断文献价值,而是开始关注这些结果是否建立在可被验证的路径之上。
这种变化,会让你的文献结构逐渐收敛,因为那些无法提供完整路径的研究,会在筛选阶段被自然过滤,而那些路径清晰的文献,则会形成一个更稳定的基础,使后续分析与写作更加顺畅。
在这一过程中,你并不需要增加阅读量,而是需要优化判断顺序,即先确认路径是否存在,再决定是否深入理解内容,这种顺序的调整,会在整个研究过程中持续降低不确定性。
FAQ
1️⃣ 可复现性是不是只针对实验类研究?
答案:不是,任何研究都涉及路径是否可被还原。
2️⃣ 没有代码的论文还能用吗?
答案:可以,前提是方法和数据足够清晰可推导。
3️⃣ 如何快速判断一篇论文是否可复现?
答案:可借助 UPDF AI 总结与结构提取功能,先还原方法与数据路径,再判断是否能走通。




