 AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南












在文献综述写作过程中,很多研究者都会花大量时间进行文献分类。例如,有人按主题分类,有人按研究方法分类,也有人按理论视角或时间阶段建立结构。表面上看,文献已经被整理得非常清晰,但真正开始写综述时,很多人依然会遇到一种非常典型的问题:
- 不同部分之间不断重复;
- 某些论文不知道应该放在哪;
- 结构看似完整,却无法形成逻辑推进;
- 写到后面发现分类标准开始混乱。
这种情况本质上说明的,并不是“分类不够细”,而是“分类本身并不合理”。
很多研究者会误以为,只要文献被成功分进不同文件夹,分类就已经完成。但实际上,真正合理的文献分类,并不只是“把论文拆开”,而是能够帮助研究者建立研究结构。文献分类真正重要的并不是分类数量,而是它是否能够支撑综述逻辑。

一、为什么很多文献分类“看起来合理”却依然不好写
在实际整理过程中,很多研究者会先从 Connected Papers、ResearchRabbit 或 OpenAlex 中寻找核心研究,再逐步建立自己的分类体系。
但很多时候,问题并不出现在“找不到分类方式”,而是:
- 分类维度之间互相冲突;
- 不同类别无法形成逻辑关系;
- 分类只是表面拆分,没有真正对应研究问题。
例如,有些人会同时按照时间、方法、理论、研究对象 进行平级分类。结果就是,同一篇论文可能同时属于多个类别,最终整个结构越来越乱。
还有一些综述虽然已经完成分类,但每个部分之间完全独立,读者读完之后依然不知道研究到底是如何发展的。这说明真正合理的分类,不只是“能分开”,还必须“能形成逻辑”。
二、真正合理的分类,通常具备哪些特征
从实际综述写作来看,合理的分类通常会同时满足几个特点:
| 判断标准 | 合理分类的表现 |
| 分类边界清晰 | 不同类别不会大量重叠 |
| 分类逻辑统一 | 全文围绕同一结构维度展开 |
| 能形成递进关系 | 各部分之间存在逻辑推进 |
| 能支撑研究问题 | 分类能够解释研究差异 |
| 可持续扩展 | 后续新增文献不会迅速失控 |
很多时候,真正的问题并不是“分类太少”,而是分类维度缺乏主次关系。
例如,如果综述核心是研究演进,那么时间分类应该成为主结构;如果核心是理论冲突,那么理论分类应该优先于方法分类。而很多人最大的问题在于同时使用多个维度,却没有确定“核心结构”。
三、为什么很多分类后期会越来越混乱
很多研究者在前期分类时,会觉得结构非常清晰,但随着阅读深入,新的问题会不断出现:
- 新论文不断打破原有分类;
- 某些研究同时涉及多个方向;
- 分类标准开始不断调整;
- 原本独立的部分开始重复。
这种问题本质上并不是“文献太多”,而是因为分类没有真正围绕研究问题建立。
例如,有些研究者会因为某篇论文出现新变量,就新增一个分类;或者因为研究场景不同,就重新拆分结构。结果就是,分类越来越细,但整体逻辑越来越弱。真正合理的分类,不是不断新增类别,而是能够稳定承载研究结构。
四、如何快速判断自己的分类是否合理
相比不断手动调整文件夹,更高效的方式,是先观察不同分类之间是否真正形成研究关系。
在这一阶段,我通常会直接把当前分类中的核心论文整理进 UPDF AI 的知识库,并按当前结构建立不同研究单元。因为很多时候,分类是否合理,并不是看“文件夹数量”,而是看:
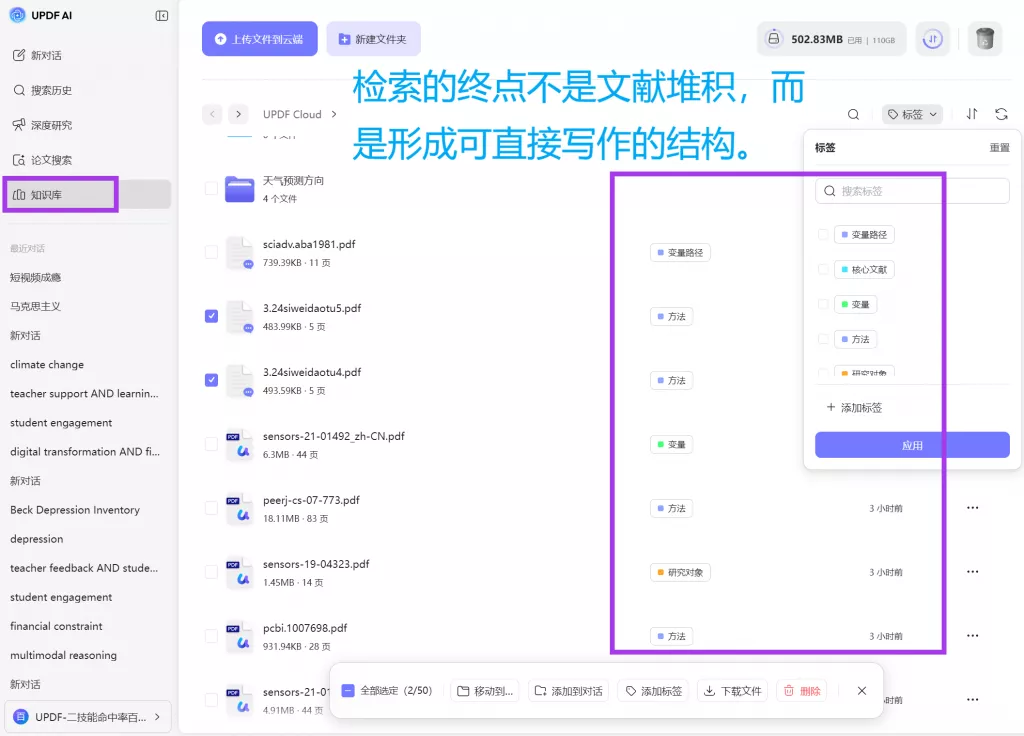
- 不同类别之间是否存在明显边界;
- 同一类别内部是否真的在讨论同一个问题;
- 某篇论文是否频繁需要重复出现。
知识库最大的优势,在于它本身就是动态结构。研究者可以不断调整分类逻辑,而不需要反复重建整个体系。
例如,如果发现大量论文频繁跨分类出现,通常意味着当前分类维度本身存在问题;而如果某一类别内部论文差异越来越大,则往往说明分类颗粒度过粗。
五、如何真正验证“分类逻辑”
很多研究者的问题在于:分类完成之后,只是“看起来合理”,却没有真正验证过结构关系。
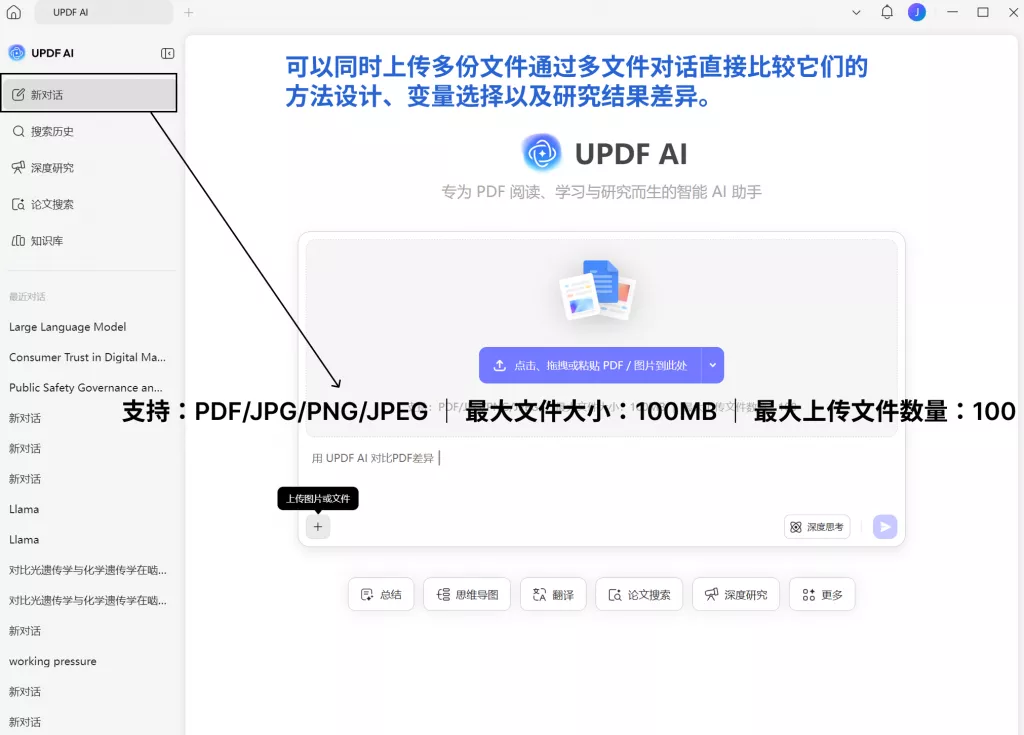
在这一阶段,我通常会进一步通过 UPDF AI 的多文件对话功能,对同一分类中的论文进行横向比较。例如:
- 它们是否真的在解决同一个问题;
- 不同研究之间是否存在共同逻辑;
- 某些论文是否更适合进入其他结构;
- 分类之间是否存在大量重复。
这种方式最大的价值,在于能够快速发现:
- 哪些分类只是表面相似;
- 哪些研究其实属于不同路径;
- 哪些结构真正能够形成逻辑推进。
因为很多时候,真正决定分类质量的,并不是“分类数量”,而是:
- 同一类别内部是否足够统一;
- 不同类别之间是否足够清晰。
真正有效的分类判断,不是看结构是否复杂,而是看逻辑是否稳定。
六、如何避免“为了分类而分类”
很多研究者后期最容易出现的问题,就是不断调整结构,却始终无法稳定下来。
例如:
- 今天按主题分类;
- 明天按理论分类;
- 后天又开始按时间分类。
结果就是,整个综述结构始终处于变化状态。
这种问题本质上是因为:分类始终停留在“形式层”,而没有真正围绕研究问题建立。
在实际处理中,我通常会优先判断:
- 当前综述最核心的问题是什么;
- 哪种分类方式最能解释研究差异;
- 哪个维度最适合作为主结构。
只有当分类开始真正服务“研究问题”时,结构才会稳定。
七、操作步骤:如何判断分类是否合理
第一步,先确定当前综述的核心研究问题;
第二步,将当前分类结构整理进知识库;
第三步,观察不同分类之间是否频繁重复;
第四步,通过多文件对话比较同类研究是否真正统一;
第五步,仅保留能够稳定支撑研究逻辑的分类结构。
八、总结
判断文献分类是否合理,真正重要的,并不是分类是否足够复杂,而是它是否能够稳定支撑综述逻辑。如果分类始终停留在“文件整理”层面,那么随着文献增加,结构往往会越来越混乱;而当分类开始围绕研究问题与研究关系建立时,综述才会真正形成逻辑结构。在实际写作中,通过 UPDF AI 的知识库与多文件对话能力,可以更高效地验证分类边界与研究关系,从而让文献分类真正服务综述写作。
常见问题
Q1: 文献分类越细越好吗?
回答:不一定,过细反而容易导致结构割裂。
Q2: 为什么分类后写作依然很乱?
回答:因为分类没有真正围绕研究问题建立。
Q3: 如何快速验证分类是否合理?
回答:用 UPDF AI 的知识库与多文件对话检查研究关系。




