AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
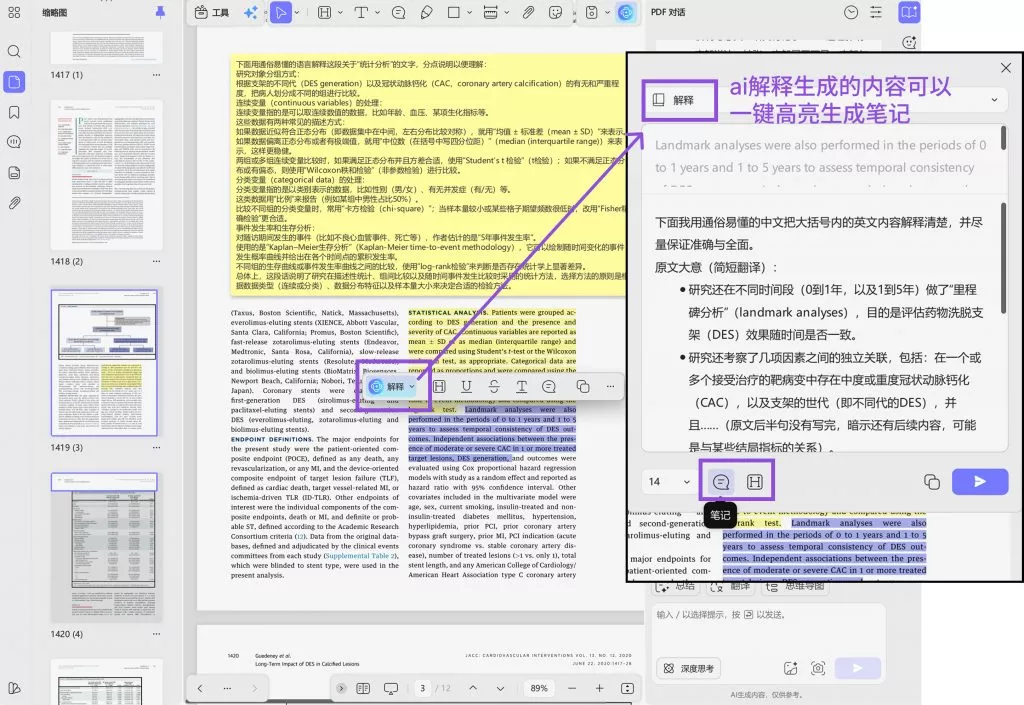
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













很多医学与心理学研究生在做文献筛选时,发现研究主题明明相同,但真正开始整理时,却发现很多论文根本无法放在一起比较。有些研究针对大学生群体,有些研究使用临床患者,还有一些研究则聚焦老年样本。虽然变量一致,但样本结构完全不同,最后导致研究结果差异非常大。
尤其是在数据库完成检索后,一个热门方向往往会快速出现大量论文。如果前期只是按照“主题相关”保存研究,后续综述很容易越来越乱,因为很多研究真正的问题,并不在理论,而在样本基础根本不一致。
因此,在医学与心理学研究里,很多成熟研究者在筛选文献时,并不会先看“结论”,而是会优先判断:
- 样本来自哪里;
- 年龄结构是否一致;
- 是否属于临床群体;
- 纳入 / 排除标准是否统一。
因为真正决定研究能否横向比较的,很多时候并不是研究主题,而是样本结构是否属于同一体系。

一、为什么样本差异会直接影响研究结果
很多研究生前期筛选时,会习惯性地只看变量、统计结果或者研究方向。但实际上,即使研究问题相同,只要样本结构不同,很多结果就可能完全不同。
例如,同样研究“焦虑与睡眠质量”,大学生群体、临床抑郁患者与老年群体之间,本身就存在明显差异。
| 样本类型 | 常见差异 |
| 大学生 | 情绪波动与压力来源不同 |
| 临床患者 | 存在疾病与药物干扰 |
| 老年群体 | 生理结构与睡眠机制不同 |
| 社区样本 | 变量控制难度更高 |
如果这些研究同时进入综述,后续很容易出现:
- 研究结果相互冲突;
- 变量关系不稳定;
- 结论无法真正解释。
很多医学与心理学综述后期真正困难的,并不是“文献太少”,而是样本体系并不统一。
二、为什么“样本来源”比研究主题更重要
很多研究生会默认主题相同 = 可以比较。但实际上,在医学与心理学研究里,真正决定研究可比性的,很多时候是样本来源是否一致。
例如,同样研究“认知行为干预”,有些研究针对青少年群体,有些研究针对临床患者,还有一些研究则聚焦普通成年人。虽然研究主题接近,但样本差异已经足以影响最终结果。
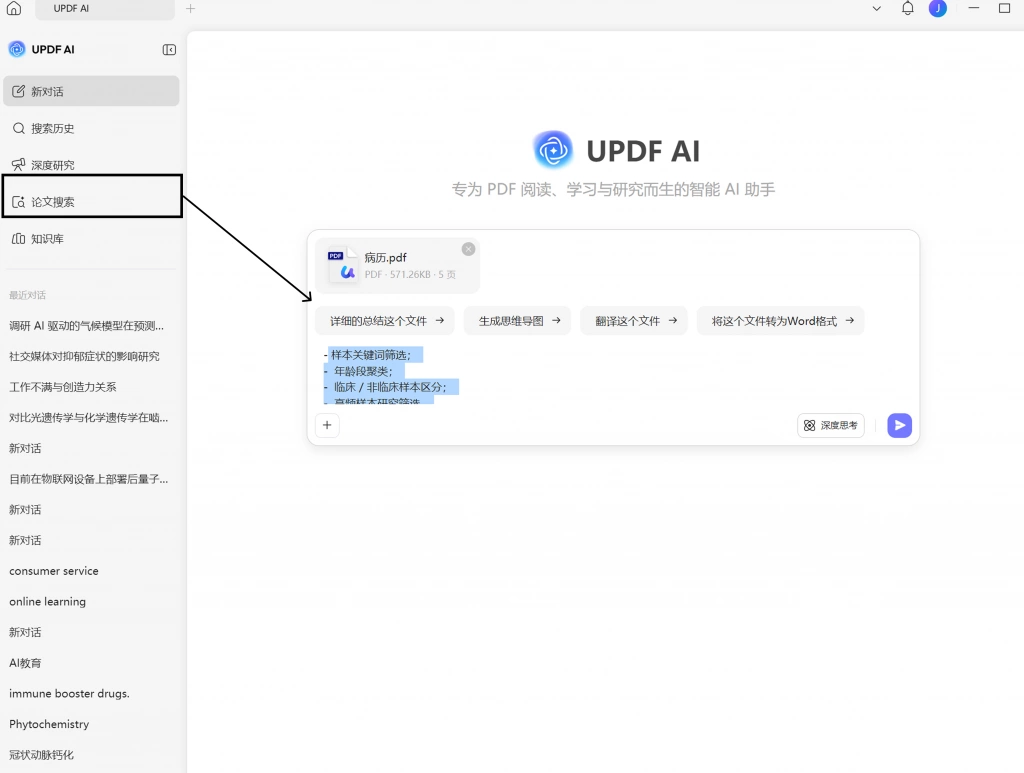
因此,很多研究者在前期筛选时,并不会立刻开始阅读全文,而是会先通过 UPDF 的 AI 论文搜索功能对研究进行:
- 样本关键词筛选;
- 年龄段聚类;
- 临床 / 非临床样本区分;
- 高频样本研究筛选。
这种方式最大的价值,在于能够更快识别哪些研究真正建立在同一人群基础上。
相比传统关键词搜索,它更容易提前建立稳定的样本主线,而不是后期再重新返工。
三、为什么很多“研究冲突”其实是样本问题
很多研究生在阅读文献时,会发现同一个变量在不同论文中,经常出现完全相反的结果。但很多时候,问题并不在理论,而在样本结构不同。
例如,同样研究“社交媒体使用与焦虑”,青少年群体可能表现为焦虑增加,而成年人群体则未必出现明显关系。如果前期没有仔细筛选样本特征,后续综述很容易把大量“不可比较”的研究放在一起。
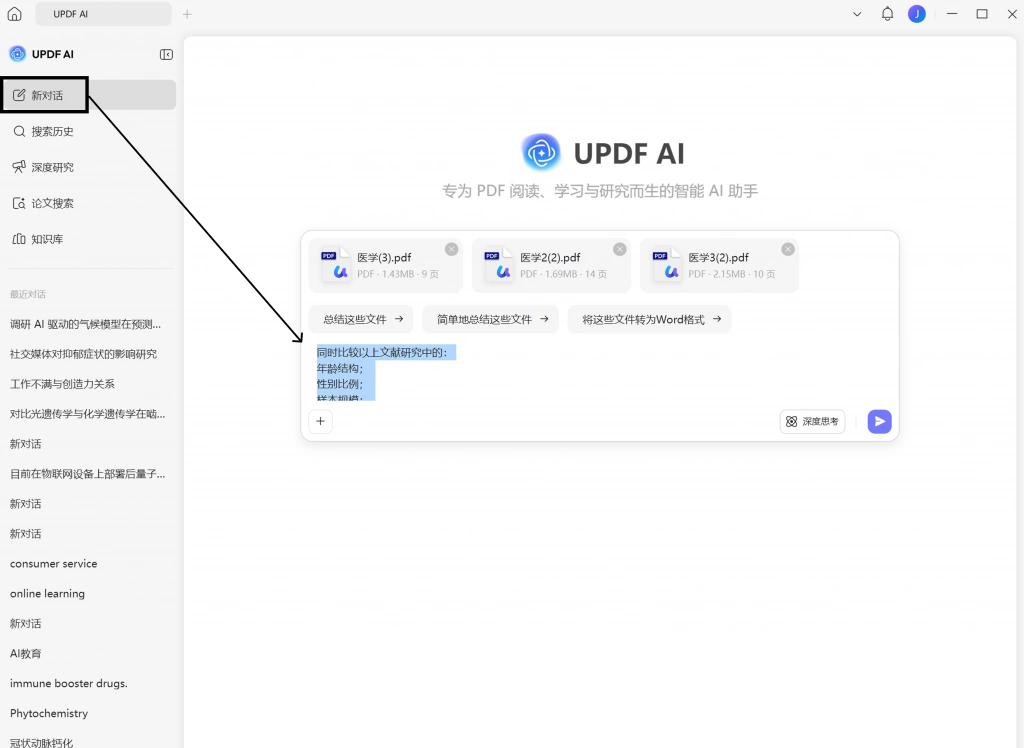
因此,很多研究者在筛选阶段,会进一步通过 UPDF 的 AI 文档对比功能同时比较不同研究。相比人工逐篇整理,这种方式更容易快速发现哪些研究真正具有可比性。
尤其是在医学研究中,很多实验结果差异巨大的原因,并不是干预方式不同,而是样本来源不同。
四、为什么关系图谱能帮助判断“主流样本”
很多研究生在筛选文献时,不知道当前领域里,哪些样本才是真正主流。例如,同样研究抑郁问题,有些研究使用大学生样本,有些研究聚焦焦虑患者,还有一些研究则分析长期临床随访数据。如果缺少整体结构,很容易把边缘样本与主流样本混在一起。
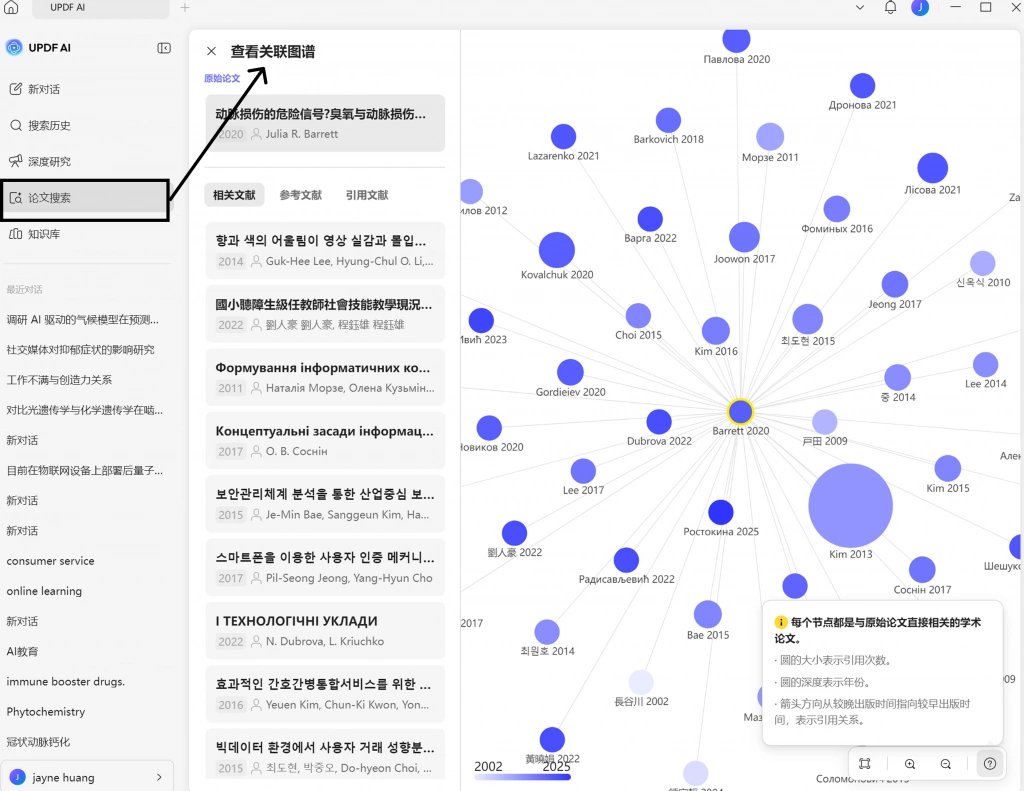
因此,很多研究者会进一步通过 UPDF 的关系图谱查看:
- 高频样本研究聚类;
- 长期被共同引用的样本路径;
- 不同群体之间的研究网络;
- 主流临床样本结构。
这种方式最大的价值,并不仅仅是“看引用关系”,而是在帮助研究者快速判断当前领域真正稳定的样本体系是什么。相比逐篇阅读,它更容易提前建立整个领域的样本结构地图。
五、为什么医学与心理学研究后期最容易“样本失控”
很多研究后期真正困难的,并不是“没有文献”,而是什么样本都想纳入。例如,一开始只是研究大学生焦虑,后续又不断扩展中学生、老年群体、临床患者等等。最后样本越来越复杂,综述结构也越来越混乱。
因此,样本筛选真正重要的,并不是样本越多越好,而是保持核心样本结构稳定。很多成熟研究者在正式筛选时,会优先确定筛选问题。
| 筛选问题 | 核心目的 |
| 哪类样本属于主线 | 保持研究稳定性 |
| 哪些群体用于辅助比较 | 控制变量扩展 |
| 哪些研究只作背景参考 | 避免结构失控 |
只有样本边界真正稳定,后续综述才不会不断扩张。
六、操作步骤:如何按样本特征筛选文献
如果把整个过程简化,可以形成一条更清晰的路径:
| 步骤 | 核心任务 |
| 第一步 | 先确定核心样本群体 |
| 第二步 | 用 AI 论文搜索筛选同样本研究 |
| 第三步 | 用 AI 文档对比分析样本差异 |
| 第四步 | 用关系图谱查看主流样本结构 |
| 第五步 | 控制样本扩展范围 |
这一流程真正重要的,并不是“找到更多论文”,而是建立真正稳定的样本比较结构。
七、总结
很多医学与心理学综述后期越来越乱,并不是因为“研究太多”,而是样本体系并不统一。
如果没有稳定的样本主线,后续研究很容易越来越像资料堆积。而当研究者能够先建立统一的样本结构,再决定哪些研究真正值得纳入时,综述逻辑才会真正清晰。
在实际研究中,通过 UPDF 的 AI 论文搜索、AI 文档对比与关系图谱功能,可以更早识别核心样本与研究路径,从而让文献筛选从“主题相关”转向“样本结构匹配”。
FAQ
Q1:为什么同一变量在不同研究里,结果差异很大?
回答:因为很多研究使用的样本群体并不一致。
Q2:按样本特征筛选最大的作用是什么?
回答:帮助研究建立稳定的比较基础。
Q3:如何更快识别同样本研究?
回答:可结合 UPDF 的 AI 论文搜索、AI 文档对比与关系图谱功能进行管理。