AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南












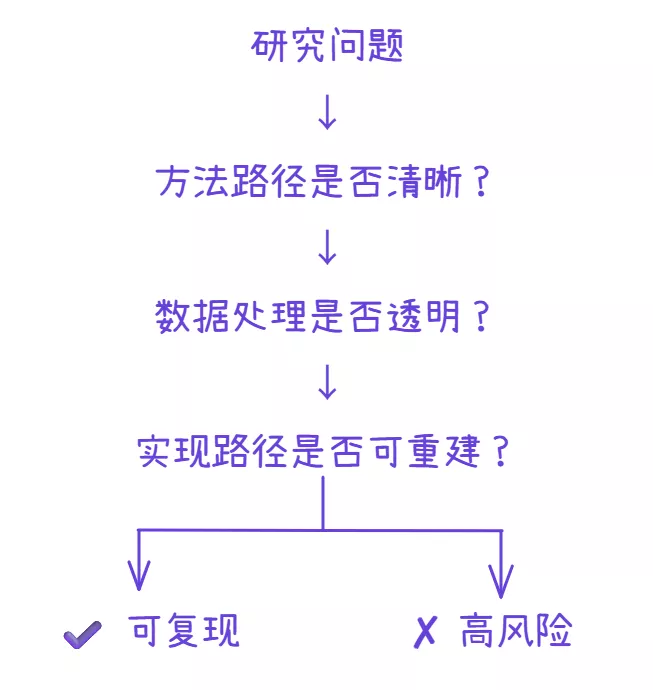
在文献筛选过程中,“偏倚风险”常常被提及,但却很少被真正理解。许多研究者在接触这一概念时,会把它简单等同于“研究质量不好”或“方法不够严谨”,从而在筛选中采取一种直接的处理方式:只要存在偏倚风险,就倾向于排除。这种处理看似谨慎,实际上却容易导致另一个问题——在试图降低风险的同时,也削弱了文献体系的完整性与解释能力。
偏倚风险的复杂之处在于,它并不是一个可以通过单一标准判断的属性,也不是一个非有即无的状态。大多数研究都不可避免地存在某种程度的偏倚,只是类型和程度不同。如果将其作为简单的筛选门槛,就会在不知不觉中把大量“有用但不完美”的研究排除在外,从而使文献结构趋于单一,甚至失去对真实研究情况的反映能力。
因此,在筛选过程中,真正需要解决的问题不是“有没有偏倚”,而是如何判断偏倚对研究结论的影响,以及这类影响是否会改变该文献在整体结构中的使用方式。

一、为什么偏倚风险容易被误用为筛选标准?
偏倚风险之所以容易被误用,首先是因为它听起来像一个明确且客观的评价指标。相比变量匹配或关系判断,偏倚似乎更接近一种“质量标签”,让人感觉可以据此做出清晰的筛选决策。但在实际操作中,这种清晰感往往是误导性的。
在 PubMed 或 Web of Science 的检索结果中,可以看到大量研究在不同程度上存在选择偏倚、测量偏倚或发表偏倚,但这些研究依然构成了该领域的主要证据来源。如果将“存在偏倚”作为排除条件,就会导致文献集合与实际研究生态之间产生明显偏离。

更重要的是,偏倚风险本身并不会直接告诉你一篇研究“是否可用”,它只能提示该研究在某些方面可能存在系统性误差。如果在筛选阶段将其直接转化为“纳入或排除”的判断依据,就会把原本需要在使用阶段处理的问题,提前转移到筛选阶段,从而改变筛选逻辑。
当偏倚被当作“质量开关”使用时,筛选就不再基于研究结构,而转向一种过度简化的风险回避机制。
二、偏倚风险真正影响的,是“结论可信范围”
要让偏倚风险在筛选中发挥正确作用,需要重新理解它的本质。偏倚并不是研究“错误”的标志,而是研究在特定条件下产生系统性偏差的可能性。这种偏差可能影响结果的方向、大小或稳定性,但并不一定使研究完全失效。
换句话说,偏倚风险改变的,并不是一篇文献“能不能用”,而是它的结论在多大程度上可以被信任,以及在什么范围内可以被使用。这一点在循证医学研究中尤为明显,例如在 Cochrane 的系统评价中,不同研究会根据偏倚风险被赋予不同的证据等级,而不是被简单排除。
因此,在筛选过程中,更重要的问题是:这类偏倚是否会改变你对变量关系的基本判断。如果偏倚只影响结果的精确程度,那么该文献仍然可以作为参考;如果偏倚可能改变关系方向或结论成立条件,则需要更加谨慎地处理。
三、哪些偏倚最容易影响筛选判断?
尽管偏倚类型多样,但在文献筛选中,真正影响判断的通常集中在几个关键层面。
首先是选择偏倚,即样本是否具有代表性。如果研究对象本身存在系统性偏差,那么即使方法设计合理,其结论也可能难以推广。其次是测量偏倚,即变量是否被准确记录或评估,这直接关系到变量关系是否真实存在。此外,还有混杂偏倚,即是否存在未被控制的变量干扰研究结果。
在 Scopus 等数据库中,可以观察到同一主题下,不同研究在这些方面的处理差异,这些差异往往正是导致结论不一致的原因。如果在筛选中忽略这些偏倚来源,就很难理解为什么研究结果会出现分化。
在实际操作中,这些判断不需要逐项精读全文才能完成。可以通过快速结构提取来识别关键风险。例如,利用 UPDF 的 AI 总结功能,可以迅速提取研究对象、变量设定及方法路径,从而判断是否存在明显的选择或测量问题。这种方式可以在不增加阅读负担的情况下,提高筛选判断的准确性。
四、什么时候偏倚风险需要特别谨慎?
并不是所有偏倚都会对筛选产生同样影响。在某些情况下,偏倚的存在会显著改变文献的结构意义。
当偏倚可能直接影响变量关系方向时,例如关键混杂变量未被控制,这类研究的结论就需要谨慎使用。此外,当偏倚程度在不同研究之间差异较大时,也可能导致结果难以比较,从而影响文献整合。
在这些情况下,更稳妥的做法并不是立即排除,而是将其标记为“高风险证据”,并在后续筛选或写作阶段进行区别处理。例如,在阅读全文时,可以通过 UPDF 的批注功能,对可能存在偏倚的部分进行标记,从而在整合阶段避免将其与低风险研究混用。
五、为什么不能简单排除所有高偏倚研究?
一个常见误区是认为,只要偏倚风险高,就应该排除。但在实际研究中,这种做法往往会带来新的问题。
首先,一些研究问题本身就难以完全避免偏倚,例如社会科学或行为研究中,很难获得完全随机且无干扰的样本。如果将高偏倚研究全部排除,可能会导致文献数量不足,甚至无法形成完整的分析框架。
其次,高偏倚研究在某些情况下仍然具有重要参考价值。例如,它们可能揭示某种趋势,或为后续研究提供初步证据。在一些前沿领域,通过 arXiv 或其他开放平台可以看到,早期研究往往偏倚较高,但仍然对研究方向产生重要影响。
如果筛选只保留“低偏倚研究”,得到的往往不是更真实的结论,而是一个被过度理想化的研究图景。
六、从“风险判断”到“结构分层”
偏倚风险之所以容易被误用,是因为判断停留在“有没有问题”这一层面。当筛选围绕风险本身展开时,很容易陷入过度排除或过度保留的两种极端。
更稳定的方式,是将偏倚纳入结构分层之中。不同偏倚水平的文献,可以在结构中承担不同角色:低偏倚研究用于支撑核心关系,中等偏倚研究用于补充证据,高偏倚研究则用于提示潜在趋势或解释差异。
这种处理方式的关键在于,你不再试图通过筛选消除偏倚,而是通过结构安排来控制其影响。在实际操作中,可以借助工具对文献进行分类整理,例如在 UPDF 知识库中根据偏倚风险进行标签标记,从而在后续使用中快速区分不同层级的证据。
筛选的目标,不是找到“没有偏倚”的文献,而是构建一个能够识别并管理偏倚的研究结构。
FAQ
问题1.有偏倚的论文一定要排除吗?
回答:不一定,关键看是否影响结论方向。
问题2.偏倚风险主要影响什么?
回答:影响结论的可信范围。
问题3.如何快速判断偏倚是否严重?
回答:看是否改变变量关系判断。