AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













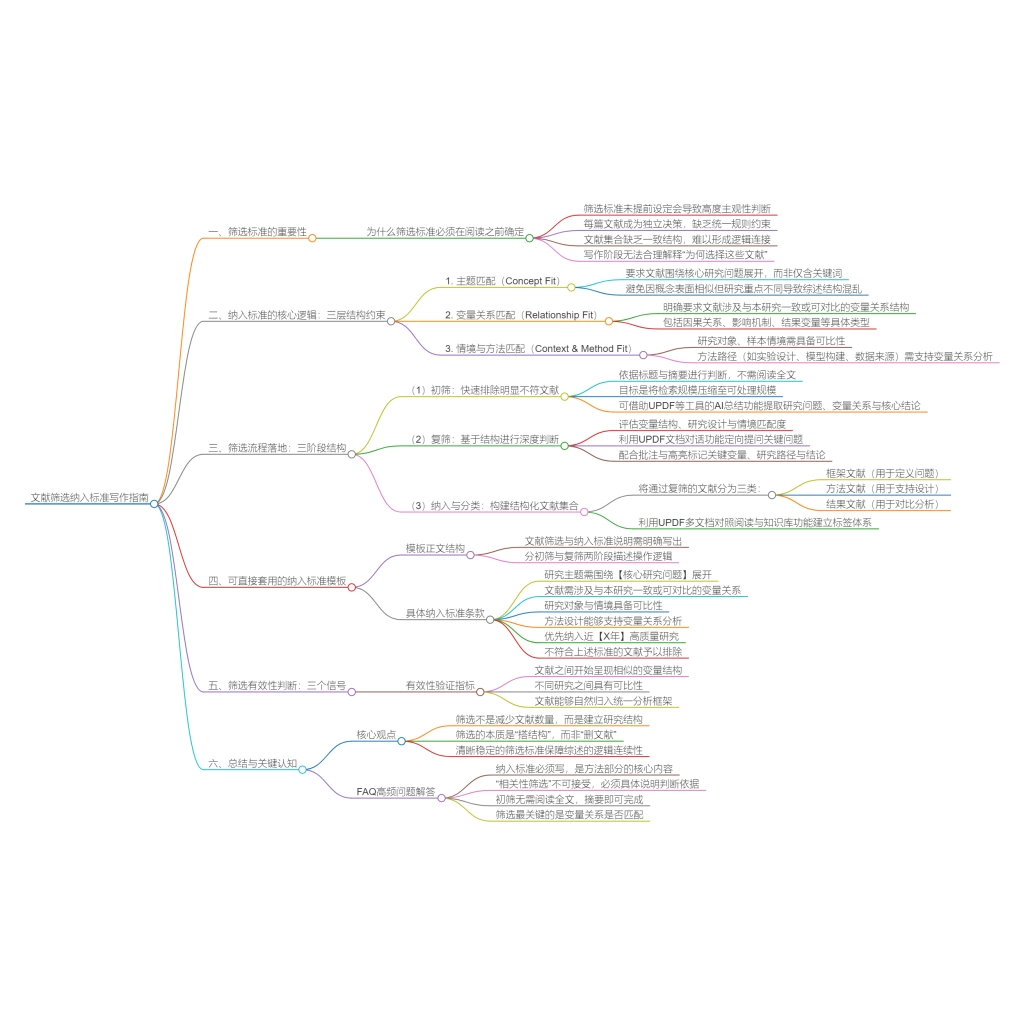
在完成标题、摘要和全文筛选之后,很多人会进入一个新的困境:文献已经筛出不少,但真正开始写作时,却发现这些文章“都相关”,却“都不好用”。
你可能已经确认了变量匹配、关系成立、方法可比,但写到具体段落时,却很难从中提取出可以支撑结构的内容。很多文献只能被用来“说明已有研究”,却很难成为你论证中的关键支点。这时候,问题往往不在筛选是否严格,而是因为你筛的是“相关文献”,而不是“可借鉴文献”。
所谓“可借鉴点”,并不是一句有启发的观点,也不是一个看起来很新的结论。这篇研究在既有路径中“改变了什么”,以及这个改变是否能被你直接使用。只有当筛选进入这一层,文献才真正开始“为写作服务”。

一、为什么很多人筛不到“可借鉴点”?
在阅读文献时,大多数人的注意力会自然落在两个地方:研究问题有没有新意,结论有没有启发。这种阅读方式本身没有问题,但如果直接用于筛选,就很容易产生偏差。
原因在于,这两类信息都属于“表达层”,而不是“结构层”。一篇文章可以用很新的角度提出问题,也可以用很有说服力的语言解释结果,但这些内容,并不一定能被你直接嵌入到自己的研究框架中。
真正决定一篇文献是否“可用”的,从来不是它讲了什么,而是它在原有研究路径中“改变了什么”。当你忽略这一点时,筛选就会出现两个典型问题:
- 一类文献“看起来很新”,但写作时无法整合。你可能会觉得它很有启发,但真正落笔时,却发现它和你的变量关系、方法路径并不匹配,只能被当作边缘引用。
- 另一类文献“看起来很普通”,却在结构上非常关键。它可能只是增加了一个变量,或者调整了一种关系,但这种变化恰好可以嵌入你的研究框架,成为你论证的一部分。
问题在于,如果你只是顺着作者的表达去理解内容,很容易把第一类文献误判为“核心”,而忽略第二类真正有价值的研究。因此,在筛选阶段,你需要从“理解内容”转向“判断结构”。 创新点,不是一个观点,而是一个结构位置。
二、创新点真正该怎么看?不是“新不新”,而是“改了哪里”
当你开始用结构视角来看文献时,创新点就不再是模糊的“新意”,而是可以被稳定识别的“变化”。
绝大多数研究的创新,其实都发生在几个固定的位置上,而不是无限扩散的。换句话说,创新并不神秘,它只是对已有路径的局部调整。
你可以把一篇研究简化为一个基本结构:变量A → 变量B → 结果
那么,创新通常就体现在对这条路径的改变上。例如:
- 在原有路径中插入新的变量
- 改变变量之间的作用方式
- 用新的方法重新验证关系
- 把同一结构放入不同情境
当你用这种方式去看文献时,判断会变得非常直接: 它有没有改变路径?改变在哪里?这个改变我能不能用?
在实际操作中,这一步如果完全依赖人工阅读,很容易被表达干扰。很多文章会用复杂的语言包装自己的创新点,让你一时难以判断它到底改变了什么。
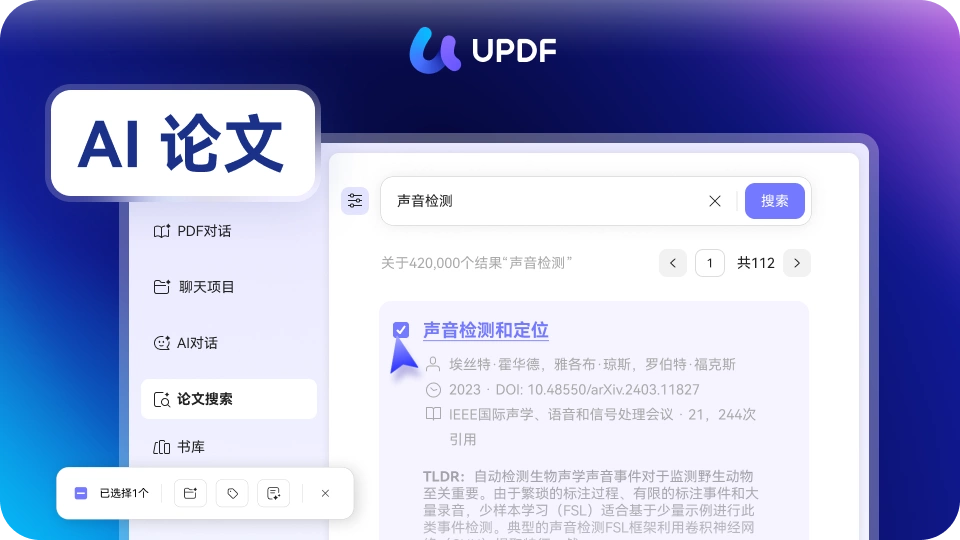
这时候,可以先借助 UPDF 的 AI 论文搜索,从关键词出发,快速观察一个研究主题下的多篇文献。当不同论文围绕同一问题展开时,你会更容易看到:哪些只是重复已有路径,哪些在变量或关系上发生了变化。当对比关系出现时,创新点才会真正“显形”。
三、如何一眼识别“可借鉴点”?从“亮点”转向“结构偏移”
很多人在找创新点时,会习惯性地去寻找“亮点”:有没有新的理论,有没有新的结论,有没有新的解释。但真正有价值的创新,往往并不以“亮点”的形式出现,而是隐藏在结构中。更有效的方式,是直接判断这篇文献是否发生了“结构偏移”。
你可以按照下面的路径来快速判断:

在这个过程中,你会逐渐建立一种新的判断习惯: 不再问“这篇文章好不好”,而是问“它改变了什么”。
当你把注意力从“亮点”转移到“结构变化”时,筛选会变得明显稳定。你不再被表达吸引,也不再被结论干扰,而是始终围绕一个问题:这篇研究,能不能进入我的框架。
四、如何快速验证这个创新点是否“真的成立”?
识别出结构变化之后,还需要再做一步:验证这个变化是否由研究本身支持,而不是来自讨论部分的延伸。因为有些所谓“创新”,其实只是作者在讨论中的解释,而不是研究设计或结果的一部分。如果直接把这类内容纳入,就会在后续写作中出现结构不稳定的问题。
在这一步,你不需要从头阅读全文,而是要有针对性地验证几个关键点:变量是否在方法中被操作,关系是否在结果中被检验,结论是否与数据一致。
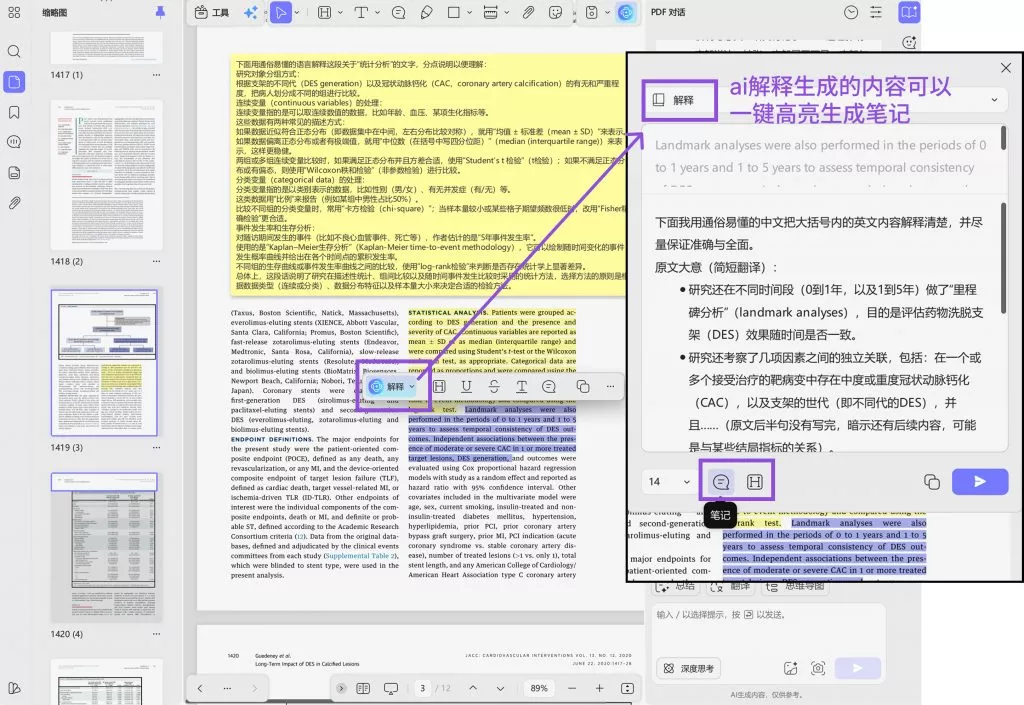
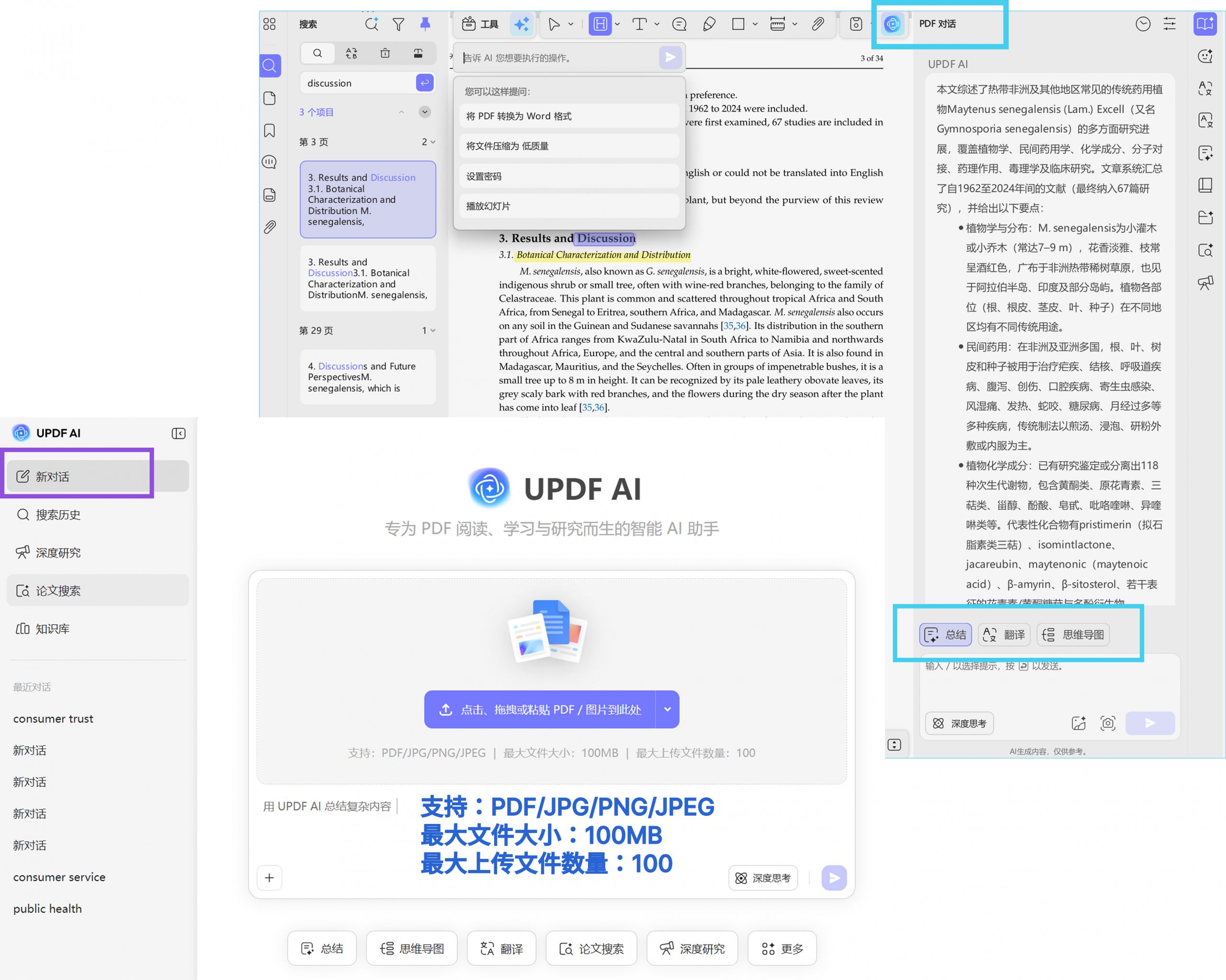
例如,在 UPDF 中,你可以直接使用 AI 总结功能,快速提取整篇论文的研究问题、变量关系和主要发现。这样,你看到的是已经结构化的信息,而不是一整段需要自己拆解的文本。
当这些关键信息被快速提取出来时,你就可以在很短时间内判断:这个创新点,是“研究结果”,还是“解释延伸”。如果仍然存在不确定,也可以通过与PDF对话的方式,直接定位某个变量关系或方法细节,而不需要逐页查找。当验证围绕问题展开,而不是围绕阅读展开时,筛选效率会明显提升。
五、什么时候“创新点”不值得纳入?
并不是所有变化都值得保留。有些文献确实做出了变化,但这种变化对你的研究结构没有实质意义。例如,只是在同一框架下更换了一个非常具体的样本,或者在已有路径上做了轻微调整,这类变化虽然存在,但并不会帮助你构建更清晰的论证。还有一些文献,看起来做了很多扩展,但这些扩展彼此分散,无法形成稳定结构。这类研究往往难以整合,写作时容易变成零散的补充,而不是核心支撑。因此,在判断创新点时,你需要再加一层标准: 它是否能够改变你的结构,而不仅仅是丰富你的内容。
筛选的目标,从来不是“尽可能多”,而是“尽可能可用”。
真正有价值的创新点,是那些可以被你直接吸收进研究框架,并参与构建论证路径的部分。
FAQ
Q1:一篇文章没有明显创新,还值得保留吗?
可以,但要明确它的作用。这类文献通常用于支撑已有研究路径,而不是构建新结构。
Q2:创新点越多,文献越重要吗?
不一定,创新过多反而可能结构分散。筛选时应优先考虑结构清晰、变化明确的研究。
Q3:怎么避免把“讨论延伸”当成创新?
关键看是否有方法和数据支持。如果某个“创新”只出现在讨论中,而没有对应设计或结果,它通常只是解释,而不是结构变化。
Q4:创新点必须完全匹配我的研究吗?
不需要完全一致,但必须可以嵌入。如果无法放入你的变量关系或方法框架,就很难在写作中真正使用。