AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













很多人做科研时都有一个错觉:“我已经搜了很多关键词,但就是找不到真正有用的论文。”于是不断换词、翻页、碰运气式点击。结果搜了两小时,收藏了一堆 PDF 文件,却依旧不知道领域核心在哪。
问题往往不在于「不够努力」,而在于:你只是在“搜索”,但没有理解文献检索的底层逻辑。真正高效的文献检索,本质不是多搜,而是
更有策略地筛选信息。
一、文献检索的本质:不是找得多,而是找得准
先想一个问题:为什么有的导师 10 分钟就能定位核心论文,而新手却要翻半天?差别在于思维方式不同。
新手习惯:关键词 → 搜索 → 从头读到尾
老手习惯:研究问题 → 锁定核心论文 → 顺着引用网络扩展
也就是说:检索的目标不是“覆盖全部”,而是“快速定位关键节点”。科研领域的论文从来不是散落的,它们之间存在明显的引用关系、方法演进关系、学派/路线分支。抓住其中几篇“枢纽论文”,就等于抓住了整个领域。
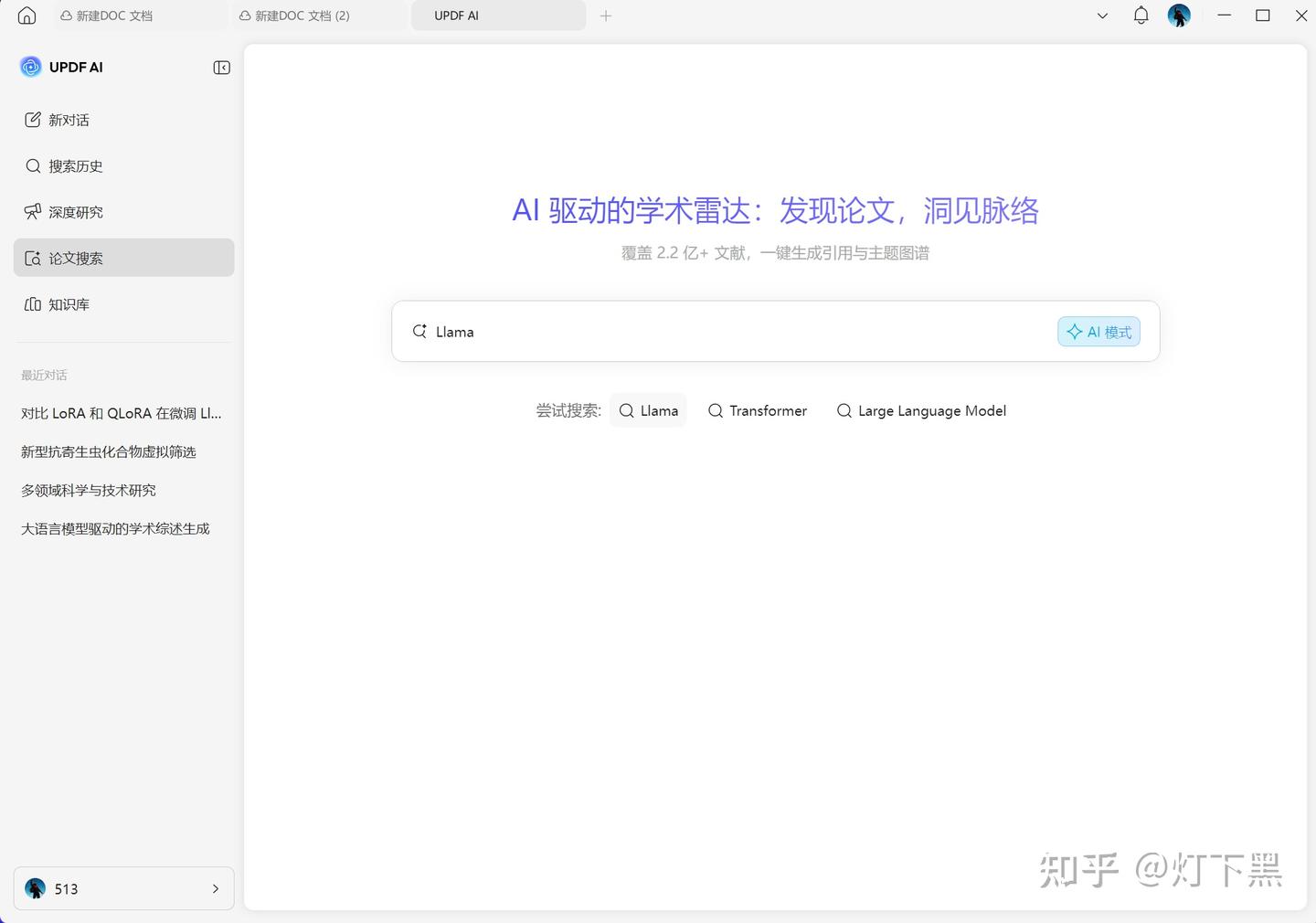
二、为什么“精准关键词”比“多关键词”更重要?
很多人误以为:词越多,结果越全。其实恰恰相反。当你搜索:深度学习 医学 图像 AI,系统会返回大量泛内容。但如果换成:Transformer medical image segmentation review,结果会瞬间精准。
原因很简单:搜索引擎本质是匹配模型,而不是理解语义。越具体的术语,信号越强。所以更有效的做法是:
- 用专业术语,而不是大白话
- 多用方法名/模型名/任务名
- 优先搜 review / survey
三、为什么要先“筛选”,而不是“精读”?
另一个常见误区是:一搜到就开始读,但现实是一篇论文 30 分钟起步,50 篇就是 25 小时。
高手的做法是分层处理:
- 第一层:标题筛选(10 秒)
- 第二层:摘要+结论(2 分钟)
- 第三层:核心论文才精读
本质逻辑是:阅读是一种高成本行为,必须留给高价值文献。把「阅读顺序」做对,比阅读速度更重要。
四、为什么要做批注和结构化整理?
很多人读完论文,最大的感受是:“好像看过,但写的时候想不起来。”这不是记忆力问题,而是信息没有被加工。大脑只会记住:你主动思考过的、你重新整理过的、你输出过的内容,所以单纯“看 PDF”几乎等于无效输入。
更有效的方式是:边读边标注重点、写下自己的理解、提炼创新点、做表格或思维导图对比。把线性阅读,变成结构化知识。
现在很多人会直接在阅读工具里完成这些步骤,比如:批注高亮、AI 总结核心观点、多文件对比问答、自动生成思维导图。把“读 → 想 → 整理”放在同一个界面完成,效率会高很多,也更容易沉淀知识。
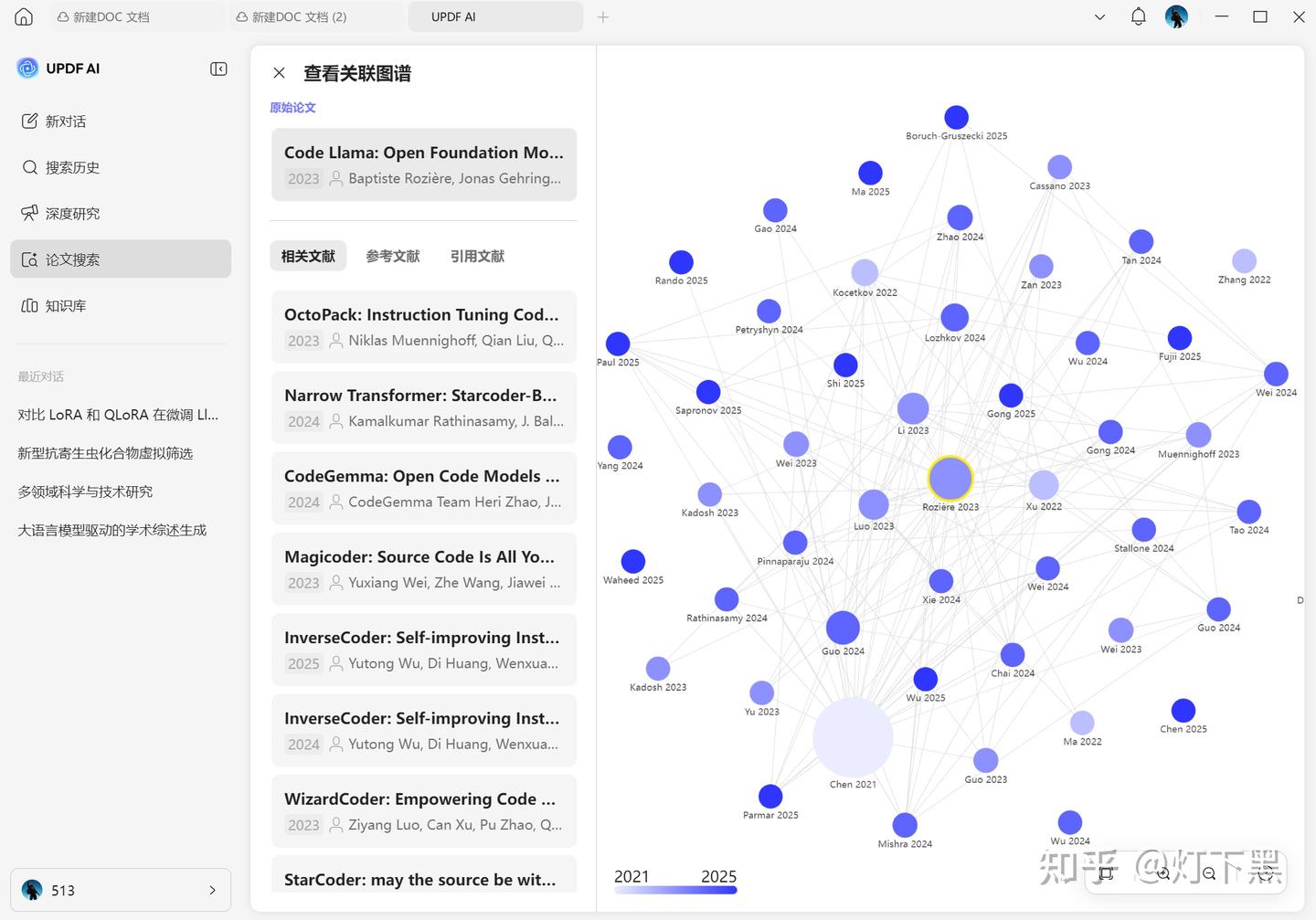
五、高手真正依赖的,是“引用网络思维”
最后一个关键逻辑,也是最容易被忽略的:重要论文一定被大量引用。所以比起反复换关键词,更高效的方法是:找到 1 篇高引用综述,看它引用了谁(向后追溯),看谁引用了它(向前拓展)。顺着引用链条走,你看到的几乎都是核心成果,这比盲目翻搜索结果靠谱得多。
总结
回到最开始的问题:为什么有的人搜得快、找得准?因为他们遵循的是这套底层逻辑:用精准词,而不是堆词;先筛选,再精读;阅读必须伴随批注整理;顺着引用网络找核心论文。
说到底:文献检索不是体力活,而是策略活。当你掌握了论文索引的技巧,你就可以花更少时间,也能更快建立领域认知。这,才是真正高效科研的开始。点击下方按钮,下载并体验 UPDF AI 的高效的文献检索效率。