AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
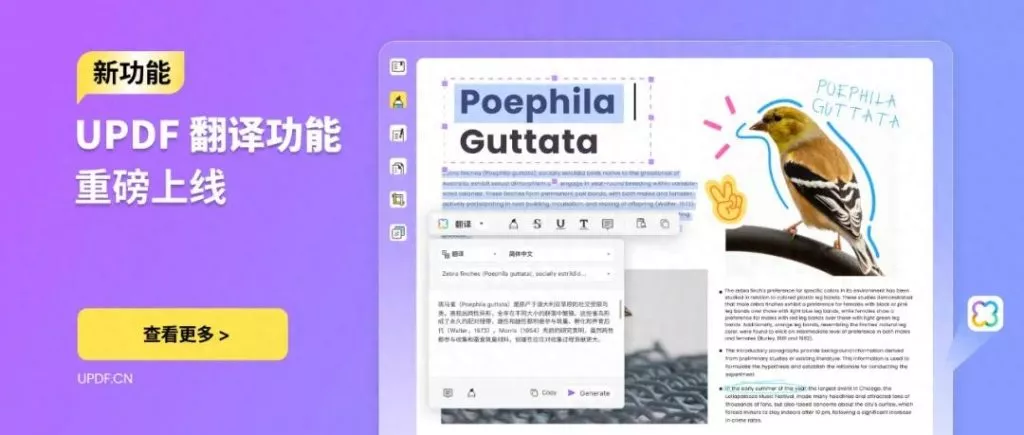
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南












对于研究生、博士生、医学生和科研工作者来说,阅读英文论文几乎是每天都会遇到的任务。问题是,很多论文都是 PDF 格式,内容又长又密,里面还有大量专业术语、图表、公式、实验方法和引用信息。如果只是把论文复制到普通翻译工具里,常常会遇到排版错乱、段落断开、图表说明丢失、术语翻译不稳定等问题。
所以,很多人真正需要的并不是简单的“把英文变成中文”,而是一个更完整的PDF论文翻译流程:既能看懂全文内容,也能保留原文结构,还能快速定位摘要、研究方法、实验结果和结论。
如果你正在找一种更适合学术阅读的 PDF 翻译方法,可以使用 UPDF 来完成论文 PDF 的翻译、OCR 识别、AI 总结、重点解释和文献问答。相比单纯复制粘贴翻译,UPDF 更适合处理整篇 PDF 论文,尤其是英文文献、扫描版论文、医学文献和长篇综述资料。
一、PDF论文翻译为什么比普通文本翻译更难?
很多用户第一次翻译英文论文时,会直接复制 PDF 里的文字,再粘贴到翻译工具里。但真正操作后就会发现,PDF 论文并不像网页文章或 Word 文档那样容易处理。
PDF 论文翻译常见难点主要有以下几类:
| 问题 | 具体表现 | 对阅读的影响 |
|---|---|---|
| 排版复杂 | 双栏排版、脚注、图表、公式混在一起 | 复制后容易断句、顺序错乱 |
| 术语密集 | 大量专业名词、缩写、方法名称 | 普通翻译容易不准确 |
| 图表说明多 | Figure、Table、Legend 信息分散 | 容易忽略关键实验结果 |
| PDF不可复制 | 扫描件或图片型PDF无法选中文字 | 需要先OCR识别 |
| 文章篇幅长 | 一篇论文十几页到几十页 | 逐段翻译效率低 |
| 重点不明确 | 摘要、方法、结果、讨论都很长 | 看完仍然抓不住核心结论 |
因此,做 PDF论文翻译 时,不能只追求“逐字翻译”,更应该考虑阅读效率。尤其是在写文献综述、准备组会汇报、做开题报告或筛选论文时,你真正需要的是:快速理解论文讲了什么、用了什么方法、得出了什么结论、和你的研究有什么关系。
二、PDF论文翻译常见方法对比
不同方法适合不同场景。如果只是偶尔翻译一小段内容,可以用普通翻译工具;但如果你要长期阅读英文 PDF 论文,建议使用专门支持 PDF 阅读和 AI 翻译的工具。
| 方法 | 适合场景 | 优点 | 局限 |
|---|---|---|---|
| 复制文字到翻译工具 | 翻译短句、单个段落 | 简单直接 | 复制后容易断行,排版混乱 |
| 浏览器翻译插件 | 翻译网页论文页面 | 操作方便 | 对PDF文件支持有限 |
| 在线PDF翻译工具 | 临时翻译小文件 | 不用安装软件 | 文件需要上传,隐私和格式稳定性需注意 |
| Word转换后翻译 | 需要大段修改内容 | 可编辑性强 | 转换后可能排版错乱 |
| UPDF PDF翻译 | 长期读论文、处理PDF文献 | 支持PDF阅读、翻译、OCR、AI总结和问答 | 更适合有持续论文阅读需求的用户 |
如果你的论文涉及未发表研究、课题资料、实验数据、临床内容或导师项目文件,不建议随意上传到不熟悉的网页工具中。使用 UPDF 这类本地 PDF 工具,可以先在软件中打开文档,再结合 AI 功能完成翻译和理解,更适合正式学术场景。
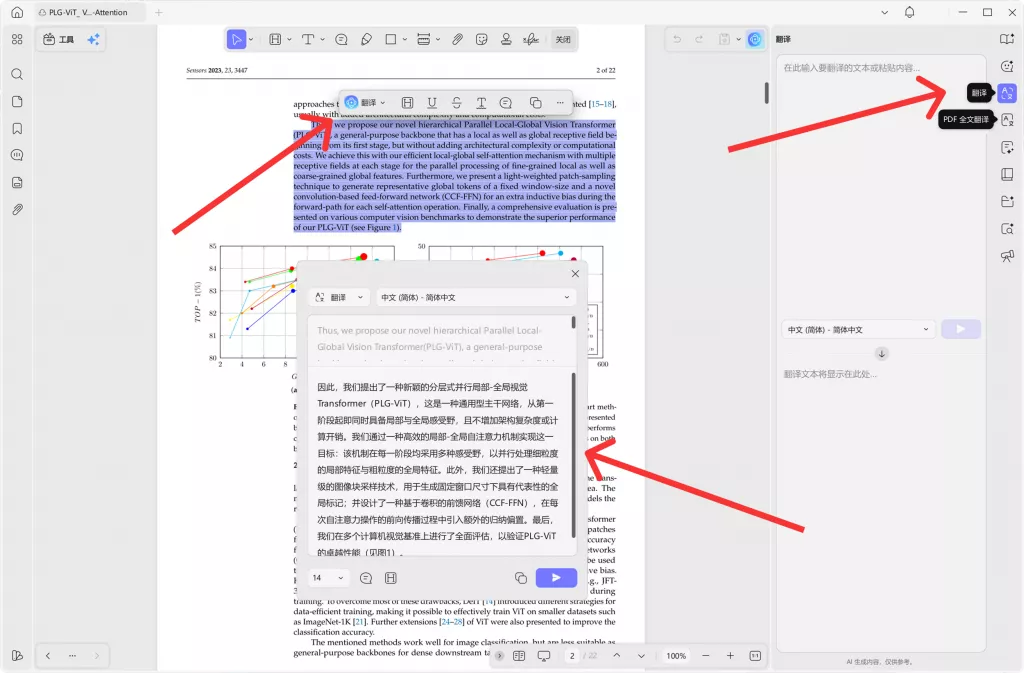
三、用UPDF做PDF论文翻译的基本流程
下面以 UPDF 为例,介绍一套更适合学术用户的 PDF 论文翻译流程。这个流程不只是“翻译文字”,而是把阅读、理解、标注和整理结合起来。
步骤1:打开PDF论文,先判断文件类型
打开 UPDF 后,导入需要翻译的 PDF 论文。此时可以先判断论文属于哪种文件:
| 文件类型 | 特点 | 推荐处理方式 |
|---|---|---|
| 普通文字PDF | 文字可以选中、复制、搜索 | 可直接翻译、划词解释、AI问答 |
| 扫描版PDF | 页面像图片,文字无法选中 | 先使用OCR识别 |
| 图片型PDF | 由图片合成,内容不可编辑 | 先OCR,再翻译 |
| 加密或受限PDF | 无法复制或编辑 | 需要确认权限后再处理 |
如果论文文字可以直接选中,可以进入翻译和阅读流程。如果文字不能选中,说明它可能是扫描件或图片型 PDF,需要先使用 UPDF 的 OCR 功能进行识别。
步骤2:扫描版论文先做OCR识别
很多旧论文、医学文献、图书章节、教材扫描件,虽然保存成 PDF 格式,但本质上仍然是图片。你不能直接选中文字,也无法搜索关键词,更不能准确翻译段落。
这时可以使用 UPDF 的 OCR 功能,把扫描版 PDF 转换成可识别、可搜索的文本型 PDF。OCR 完成后,你就可以继续进行划词翻译、全文阅读、关键词搜索和 AI 问答。
OCR 对 PDF 论文翻译非常重要,尤其适合这些情况:
- 下载的论文是扫描版;
- PDF 文字无法复制;
- 文档里全是图片型页面;
- 需要搜索关键词但搜索不到;
- 想翻译旧文献、教材、报告或会议论文;
- 想把论文内容转成可编辑或可整理的文本。
如果你遇到“PDF论文不能复制文字”的问题,不要急着换工具,先判断是否需要 OCR。很多翻译失败、内容乱码、段落错乱的问题,本质上都是因为原 PDF 没有可识别文本层。
步骤3:使用AI翻译理解论文内容
完成文件识别后,可以使用 UPDF 的 AI 翻译功能来理解论文内容。对于英文论文,不建议一开始就从 Introduction 逐字读到 Conclusion。更高效的方法是先翻译关键部分,再决定是否深入阅读全文。
建议优先翻译这些部分:
| 论文部分 | 翻译目的 |
|---|---|
| Title 标题 | 判断研究主题是否相关 |
| Abstract 摘要 | 快速了解研究目的、方法、结果和结论 |
| Introduction 引言 | 理解研究背景和问题来源 |
| Methods 方法 | 判断研究设计、样本、实验流程和分析方法 |
| Results 结果 | 查看主要数据和发现 |
| Discussion 讨论 | 理解作者如何解释结果 |
| Conclusion 结论 | 提炼最终观点和研究价值 |
使用 UPDF 时,你可以先选中重点段落进行翻译,也可以结合 AI 功能让它解释某个概念、总结某一页内容或回答和论文相关的问题。这样做比单纯整篇机翻更适合学术阅读,因为论文阅读的核心不是“每个词都翻译出来”,而是快速判断这篇文献是否值得精读。
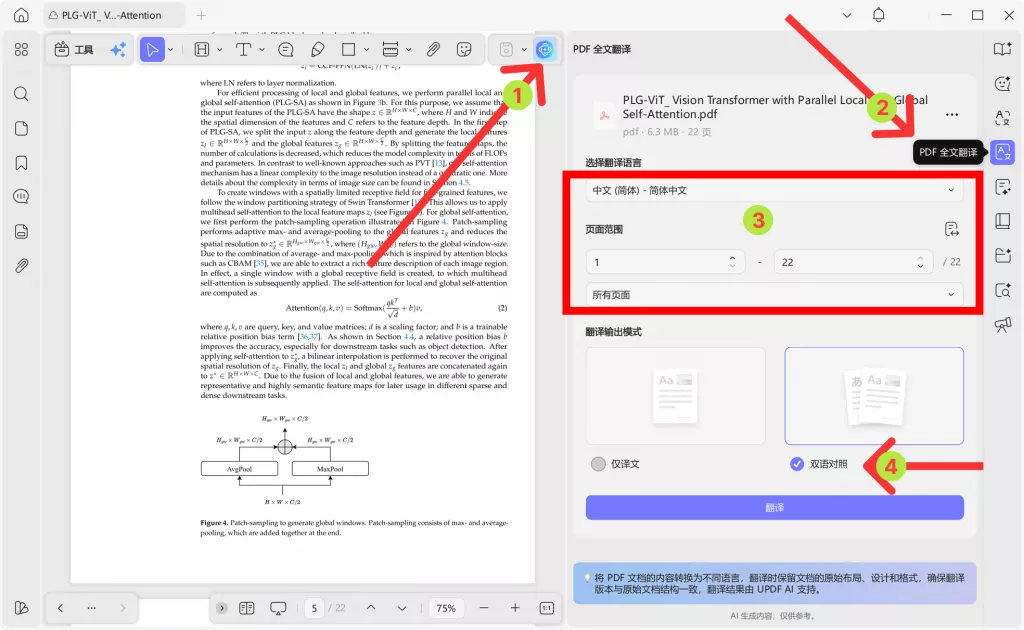
步骤4:划词翻译专业术语,不要只看整段翻译
英文论文里最容易卡住的,往往不是普通句子,而是专业术语和固定表达。例如医学论文里的 randomized controlled trial、confidence interval、hazard ratio,社会科学论文里的 mediating effect、theoretical framework,工程论文里的 finite element analysis、signal-to-noise ratio 等。
这类词如果翻译不稳定,整段内容就容易理解错。
在 UPDF 中阅读 PDF 论文时,可以对不理解的词或短语进行划词翻译,也可以让 AI 解释这个术语在当前论文中的含义。相比把整段文字直接翻译成中文,划词翻译更适合处理专业词汇、方法名称、模型名称和统计指标。
建议你在读论文时建立一个术语记录习惯:
| 原文术语 | 中文解释 | 所在页面 | 备注 |
|---|---|---|---|
| confidence interval | 置信区间 | p.3 | 注意和标准误区别 |
| cohort study | 队列研究 | p.5 | 医学研究常见设计 |
| mediation effect | 中介效应 | p.7 | 需要结合模型理解 |
如果后续要写文献综述、论文笔记或组会汇报,这些术语记录会非常有用。
步骤5:用AI总结论文,而不是逐句硬翻
很多人做 PDF论文翻译 时,会陷入一个误区:认为只有把整篇论文全部翻译完,才算读懂了论文。实际上,科研阅读更重视筛选和理解,不是每篇文献都值得逐字精读。
对于刚找到的一批英文文献,可以先用 UPDF AI 总结论文,快速获得这些信息:
- 这篇论文研究了什么问题;
- 作者为什么做这个研究;
- 使用了什么研究方法;
- 样本、数据或实验对象是什么;
- 主要结果是什么;
- 结论是否支持研究假设;
- 这篇论文的局限是什么;
- 是否值得加入你的文献综述。
你可以这样向 AI 提问:
请用中文总结这篇论文的研究背景、研究方法、主要结果和结论。
请提取这篇论文中和研究方法相关的内容,并用中文解释。
请总结这篇论文的创新点、局限性,以及它适合放在文献综述的哪个部分。
这种方法特别适合研究生筛文献。你不需要把每篇论文都完整翻译一遍,而是先通过 AI 总结判断价值,再决定哪些论文需要重点阅读。
四、PDF论文翻译时如何尽量保持排版?
很多用户搜索 PDF 论文翻译时,都会关心一个问题:翻译后会不会排版乱?这个问题要分情况看。
如果你想保留原 PDF 的版式,建议不要随意把整篇论文复制到其他工具中重新生成文档。论文 PDF 通常包含双栏、图表、脚注、公式和参考文献,复制粘贴很容易破坏结构。
更稳妥的方法是:
- 在 UPDF 中打开原 PDF;
- 直接在 PDF 阅读环境里进行翻译和解释;
- 对重点段落做批注或高亮;
- 需要整理时,再将翻译结果复制到笔记或文献表格中;
- 如果需要编辑扫描件,先 OCR,再处理内容。
对于学术阅读来说,很多时候没有必要生成一份完全替换原文的中文 PDF。更推荐保留英文原文,同时在旁边记录中文理解。这样既能避免引用时脱离原文,也能减少机器翻译带来的误解。
如果你确实需要对 PDF 内容进行编辑,比如修改文字、添加说明、插入链接或加入中文注释,可以使用 UPDF 的 PDF 编辑功能。它支持像 Word 一样调整文字内容,包括字体大小、颜色、行间距等,也可以添加批注、文本框和注释说明。
五、PDF论文翻译后,如何整理成可用的文献笔记?
翻译只是第一步,真正有价值的是把论文内容整理成后续能复用的材料。尤其是写文献综述、开题报告、论文引言时,如果只是翻译完就关掉文件,后面还是会忘记。
建议用下面这个结构整理每篇论文:
| 项目 | 记录内容 |
|---|---|
| 论文标题 | 原标题和中文理解 |
| 研究主题 | 这篇论文属于哪个研究方向 |
| 研究问题 | 作者想解决什么问题 |
| 研究方法 | 使用了什么实验、模型或数据 |
| 主要结果 | 得出了什么关键发现 |
| 创新点 | 和已有研究相比有什么不同 |
| 局限性 | 样本、方法、数据或结论的不足 |
| 可引用位置 | 适合放在综述、引言、方法还是讨论部分 |
在 UPDF 中,你可以边翻译边高亮重要句子,用批注记录自己的理解,也可以让 AI 帮你把论文内容整理成结构化摘要。这样后续写综述时,就不用重新打开每篇 PDF 从头找信息。
对于大量文献阅读,建议不要只做全文翻译,而是建立一个“翻译 + 总结 + 批注 + 分类”的工作流。
六、哪些论文最适合用UPDF翻译?
UPDF 适合翻译和阅读多种类型的论文 PDF,尤其是下面几类:
1. 英文核心期刊论文
这类论文专业术语多、句子长,直接阅读容易卡顿。可以先用 AI 总结整体内容,再翻译摘要、方法和结果部分。
2. 医学论文和临床研究
医学论文经常涉及研究设计、统计指标、样本筛选和结果解释。使用 UPDF 翻译时,可以重点让 AI 解释研究方法、纳排标准、主要结局和局限性。
3. 文献综述类论文
综述文章通常篇幅长、引用多,适合先用 AI 提取主题结构,再按小节翻译重点内容。
4. 扫描版旧文献
旧文献经常是扫描件,无法直接复制文字。可以先用 OCR 识别,再进行翻译和整理。
5. 组会汇报材料
如果你需要快速读懂一篇英文论文并做组会汇报,可以用 UPDF 先总结论文,再提取研究背景、方法、结果和讨论,最后整理成汇报框架。
七、PDF论文翻译常见错误
错误1:整篇复制到翻译工具,不检查原文结构
论文 PDF 经常有双栏排版,复制后段落顺序可能错乱。建议在 PDF 原文环境中翻译和阅读,减少结构错误。
错误2:只看中文翻译,不回看英文原文
机器翻译可以帮助理解,但不应该完全替代原文。关键概念、数据结果和结论部分,仍然需要对照英文原文确认。
错误3:忽略图表和注释
很多论文的核心结果不在正文,而在图表、图注和表格说明里。翻译论文时要特别关注 Figure、Table 和 Supplementary Material。
错误4:扫描件不做OCR,直接尝试翻译
如果 PDF 是图片型文件,翻译工具可能无法识别内容。应先用 OCR 转换为可识别文本。
错误5:把翻译当成最终阅读结果
翻译只能解决语言障碍,不能替代学术判断。真正读论文还需要判断研究设计是否合理、数据是否支持结论、局限性是否明显。
八、总结:PDF论文翻译不只是翻译,更是学术阅读流程
如果你只是翻译一小段英文内容,普通翻译工具就能解决。但如果你需要长期阅读英文论文、整理文献综述、准备组会汇报或处理扫描版 PDF,单纯复制粘贴效率并不高。
更推荐的做法是使用 UPDF 建立完整的 PDF论文翻译 工作流:先判断 PDF 类型,扫描件先 OCR;再对标题、摘要、方法、结果和结论进行重点翻译;遇到术语时用划词翻译和 AI 解释;需要快速筛文献时,用 AI 总结论文核心内容;最后通过高亮、批注和结构化笔记,把翻译结果整理成可复用的学术材料。
这样做不仅能提升英文论文阅读效率,也能减少误读、漏读和重复整理的时间成本。
FAQ:关于PDF论文翻译的常见问题
1. PDF论文翻译用什么工具比较方便?
如果只是翻译短句,可以使用普通翻译工具;如果要处理整篇 PDF 论文,更建议使用支持 PDF 阅读、AI 翻译、OCR 和批注的工具,例如 UPDF。它可以帮助你在阅读论文时完成翻译、解释、总结和文献整理。
2. 扫描版PDF论文可以翻译吗?
可以,但需要先进行 OCR 识别。扫描版 PDF 本质上是图片,无法直接选中文字。使用 UPDF 的 OCR 功能识别后,再进行翻译、复制、搜索和编辑会更方便。
3. PDF论文翻译后能保留原排版吗?
如果只是在 PDF 阅读环境中翻译和批注,原文排版不会被破坏。如果你把全文复制到其他工具中重新生成文档,可能会出现段落错乱、表格变形或公式丢失的问题。正式阅读时建议保留原 PDF,并在 UPDF 中翻译和标注重点。
4. 英文论文PDF翻译时,哪些部分最应该先看?
建议先看标题、摘要、结论,再看方法和结果。如果这篇论文和你的研究高度相关,再继续精读引言、讨论和图表。这样可以避免在不重要的文献上浪费太多时间。
5. AI翻译论文会不会不准确?
AI 翻译可以提高阅读效率,但专业术语、统计结果和研究结论仍然需要对照原文检查。对于关键概念,建议使用 UPDF 的划词翻译、AI解释和原文对照一起判断,不要只依赖单次翻译结果。