AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













在文献综述、开题报告甚至系统性回顾中,很多人发现同一个研究问题,不同的人筛出来的文献完全不同。更糟的是,这种差异往往不是因为理解不同,而是因为筛选过程本身没有稳定的逻辑。有的人依赖关键词,有的人依赖摘要判断,还有的人甚至是“读着感觉相关就留下”。一开始,这种方式似乎没有问题,但随着文献数量不断增加,你会逐渐陷入一种熟悉的状态——越筛越多,越筛越乱,甚至开始怀疑自己的研究问题是否本身就不清晰。
这时候,大多数人会把问题归结为“检索策略不够好”或者“阅读不够深入”,但真正的原因是你的研究问题,并没有被转化为可执行的筛选标准。换句话说,你不是在筛选文献,而是在逐篇做判断。而判断,是无法复现的。

一、为什么筛选总是不可复现?
在没有明确筛选逻辑的情况下,文献筛选通常呈现出一种“临时决策”的状态。你打开一篇文献,看摘要,判断是否相关;再打开下一篇,又重新做一次判断。每一次决策看似合理,但实际上,它们之间并没有共享同一套规则。
这会带来三个连锁反应。
首先,筛选标准不断漂移。你在前期可能更关注“主题是否相关”,但到了后期,可能更关注“方法是否严谨”或者“变量是否完整”,这种隐性变化会让你的文献集逐渐失去一致性。
其次,文献结构开始失控。一些边缘相关的研究被不断纳入,而真正关键的文献却被稀释,最终导致整个文献体系看起来丰富,却难以支撑清晰的研究框架。
最关键的是,这种筛选方式无法复现。即使你自己重新筛一遍,也很难保证得到相同结果,更不用说让别人理解你的筛选逻辑。
问题的核心,并不是你没有筛选标准,而是你的标准并不是从研究问题中推导出来的。

二、真正的缺口:研究问题没有被“结构化”
很多人在意识到筛选混乱之后,会尝试补充一些标准,比如限定时间范围、期刊等级,或者增加关键词过滤。但这些标准往往只是表层约束,它们并没有真正触及研究问题本身。
一个可以被复现的筛选过程,必须满足一个条件:
👉 每一条筛选规则,都可以追溯到研究问题中的某个组成部分。
这就意味着,你需要先回答一个更基础的问题:你的研究问题,究竟由什么构成?
在实际操作中,这一步往往是模糊的。很多人停留在一句话描述上,却没有进一步拆解变量、关系和研究路径。结果就是,在筛选文献时,无法判断“相关”的具体含义。
这也是为什么,在真正开始筛选之前,你需要先对研究问题进行一次结构化重建。
在这个阶段,与其盲目扩展关键词,不如先通过UPDF的AI论文搜索去观察整个研究领域的分布。当你输入核心问题进行检索时,不只是得到一组文献列表,更重要的是通过其文献关联图谱,看到哪些变量反复出现,哪些研究路径构成主线,哪些方向只是边缘分支。这个过程,本质上是在帮助你把一个模糊的问题,逐渐还原成一个有结构的研究空间。
当变量和路径开始清晰时,筛选标准其实已经隐约出现了。

三、从问题到标准:筛选的本质是划定边界
当研究问题被拆解之后,你会发现,筛选标准并不是额外添加的条件,而是问题本身的延伸。
最直接的一层,是变量边界。也就是说,只有包含核心变量的文献,才有被纳入的必要。如果一篇研究虽然使用了相似的关键词,但核心变量不同,那么它在结构上已经偏离。
进一步,是关系边界。变量的存在并不意味着研究是可用的,你还需要关注变量之间的关系形式。如果你的研究关注因果路径,而某些文献仅停留在描述层面,那么它们并不能为你的研究提供支持。
最后,是方法与情境的边界。当研究方法不可比,或者研究对象与情境差异过大,即使变量和关系一致,这类文献也会破坏整体结构的统一性。
当这三层边界被明确之后,筛选就不再是“选择”,而变成了一种过滤机制。你不再需要反复权衡,而是根据规则快速判断。
四、从“读完再判断”到“先过滤再验证”
真正让筛选变得可复现的关键,在于顺序的改变。
大多数人习惯先读文献,再决定是否纳入,但这其实是效率最低、也最不稳定的方式。因为在阅读之前,你已经隐含地做了判断。
更有效的方式,是先根据规则进行过滤,再进行必要的验证。
在初筛阶段,你并不需要完整阅读文献,而是需要快速判断它是否符合变量和关系边界。这时候,如果依赖人工阅读,速度会非常慢,也容易遗漏关键信息。相反,通过UPDF的AI总结功能,可以直接提取文献中的研究问题、变量关系以及方法路径,让你在极短时间内完成结构判断,而不是陷入“读完再说”的循环。
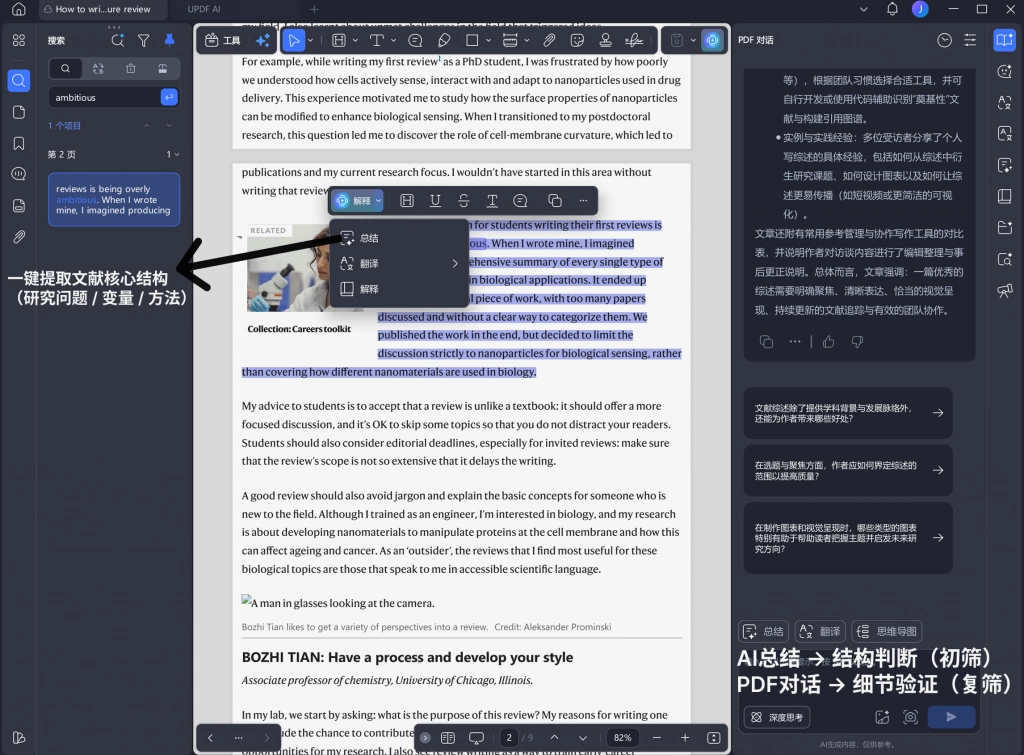
当文献通过初步过滤后,进入更细致的筛选阶段,你可能需要确认一些关键细节,比如变量是否真实存在,关系是否被实证验证,或者方法是否符合你的研究设计。这类问题,如果通过手动查找,往往需要反复翻阅全文。
在这种情况下,通过与PDF直接对话,反而更高效。你可以针对具体问题进行提问,让系统直接定位相关内容并给出答案,从而快速完成验证。这种方式,不仅减少了阅读负担,也让每一次筛选决策都有明确依据。
在这个过程中,一个明显的变化会逐渐显现:你不再是在阅读文献,而是在执行筛选规则;不再依赖感觉,而是在验证结构。
五、为什么这种筛选方式可以被复现?
当筛选标准来源于研究问题,并且在整个过程中始终以规则形式执行时,筛选过程自然具备了可复现性。
因为此时,每一篇文献的去留,都可以被解释为是否符合某一条边界,而不是“看起来合适”。这意味着,不同的人在相同标准下,会得到高度一致的筛选结果。
更重要的是,这种结构化筛选方式,会直接影响后续写作。当文献在筛选阶段就已经具备统一的变量逻辑和研究路径时,综述的结构不再需要事后拼接,而是可以自然展开。
换句话说,筛选不再只是前期准备,而是整个研究结构的起点。
FAQ
1️⃣ 为什么同一个研究问题,不同人筛出来的文献差异很大?
因为筛选标准没有从研究问题中拆解出来,而是依赖个人判断,导致标准不一致。
2️⃣ 如何判断筛选标准是否合理?
如果每一条标准都可以追溯到研究问题中的变量、关系或方法,那么这个标准就是结构化且有效的。
3️⃣ 如何提升筛选效率同时保证准确性?
通过结构化提取和验证,而不是依赖全文阅读。例如利用AI总结快速判断结构,用文档对话验证关键细节,可以显著提升效率。
总结
很多人把文献筛选理解为一个“缩减数量”的过程,但真正有效的筛选,从来不是减少,而是约束。当研究问题没有被拆解,筛选就只能依赖直觉;当筛选依赖直觉,结果就无法复现。只有当问题被转化为变量、关系和方法的边界,并进一步形成稳定的筛选规则时,文献筛选才会从“混乱扩张”走向“结构收敛”。
在这个过程中,工具并不是替代思考,而是放大结构。当你能够借助AI论文搜索快速识别研究路径,通过总结功能提取结构信息,再通过文档对话完成精确验证时,筛选本身就不再是一项负担,而是一个清晰、可控、可重复的过程。