AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













做科研最让人崩溃的瞬间,往往不是写论文卡壳,而是搜完文献之后出现一堆的论文。一个关键词能搜出800篇论文,换个数据库又冒出1200篇,手忙脚乱下载了一堆PDF文件,最后却对着满屏文件发呆,不知道从哪篇开始看。
很多新手的第一反应都是:“那我就一篇一篇慢慢读吧,总能读完的。”但半天过去,费劲巴力只看了3篇。读完才发现,这几篇和自己的研究根本不相关。大把时间,全浪费在低质量、没价值的文献上。
其实这真不是你不够努力,而是你不会做文献初筛。真正有经验的研究生、博士,很少会逐篇精读所有文献。他们在10分钟内,直接淘汰50%-70%的论文,只留下真正值得花时间精读的那一小部分。今天这篇文章,就把这套可直接照做的10分钟文献初筛法,手把手教给你,读完就能上手,彻底告别无效阅读。
一、为什么“初筛”比“精读”更重要?
很多新手都觉得只有逐篇认真读,才算是踏实做科研,才算努力。但真实的科研逻辑是文献筛选能力,它比单纯的阅读能力更重要。在你搜出来的所有文献里,真正有价值、和你研究高度相关的,可能只占20%。剩下的80%,要么是低相关,要么是重复研究,根本不值得你花时间精读。
如果不做初筛,上来就逐篇读,你大部分时间都在啃“无用信息”,忙了大半天却没一点收获。真正高效的科研人,都懂得先筛再读。先把无用的垃圾时间砍掉,再把精力放在高价值的文献上。
二、什么是文献初筛?
文献初筛就是用最少的时间,判断“这篇论文值不值得精读”。初筛不是让你读懂论文的全部内容,只是让你快速做个“取舍决策”。它的本质是“快速决策”,而不是“深度学习”。所以初筛绝对不能慢,越慢越失败,越慢越浪费时间。
三、10分钟高效初筛的5步流程
下面这套流程,是很多博士生、资深课题组常用的方法,非常实战,不管你是做综述、写毕业论文,还是开题,都能直接套用。
Step 1:只看标题(3秒法则)
第一步特别粗暴,只看论文标题,每篇只给3秒时间,看看这篇论文和你的研究方向是不是高度相关?
如果标题都明显偏题,比如你研究“医学知识图谱问答”,结果论文标题是“教育领域知识图谱应用”“社交网络分析方法”,直接淘汰,别犹豫,也别点开看正文——点开就是浪费时间。
Step 2:只读摘要(1分钟法则)
通过标题筛选的论文,下一步只读摘要,每篇控制在1分钟以内。不用逐字逐句读摘要,重点只看4件事,抓核心信息:
- 研究问题(作者要解决什么问题);
- 研究方法(用了什么方法做研究);
- 数据/场景(研究用的什么数据、针对什么场景);
- 结论贡献(作者最终得出了什么结论,有什么创新点)。
如果发现这3种情况,继续淘汰:
❌ 研究方法太老旧,不符合当前研究趋势;
❌ 研究场景和你的方向不匹配;
❌ 只是对现有方法的小修小补,没有什么创新。
初筛阶段最忌讳“读都读了,再多看看吧”的想法,这种想法会严重拖慢你的节奏,果断取舍才是关键。
Step 3:看图表和结论(快速辨价值)
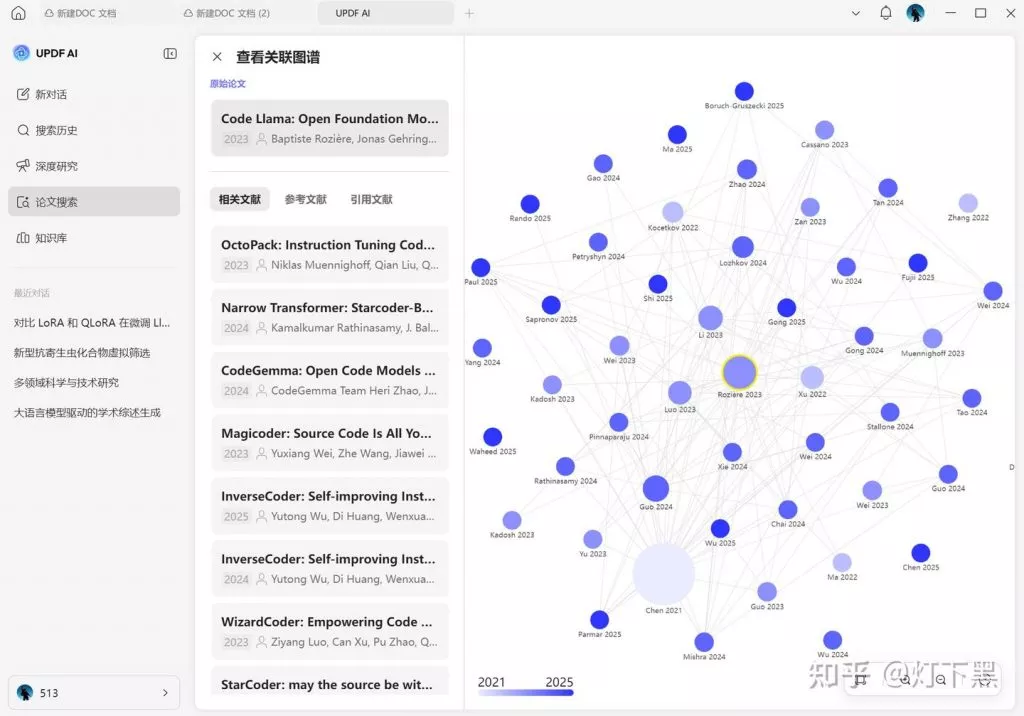
有经验的科研人,初筛时几乎不先读正文,而是直接翻到论文的“图表”和“结论”部分。图表是论文的核心结果,一看就能知道作者做了什么、得出了什么数据。结论是作者的核心贡献,一看就能判断这篇论文有没有料。如果没什么创新,只是重复别人的工作,这样的论文继续淘汰。
Step 4:快速标记分类(避免混乱)
经过前3步,留下的论文已经不多了,这时候一定要立刻分类,别堆在一起不管——不然过一会儿,你又会陷入“不知道从哪开始读”的困境。
简单分3类就够,清晰又好记:
1. 核心必读(和你的研究高度相关,创新点突出,必须精读);
2. 方法参考(研究方法值得借鉴,不用精读,但要留存);
3. 背景补充(只用来补充研究背景,粗略读一遍就行)。
结构化管理文献,是初筛高效的关键,别偷懒。
Step 5:批量对比,而非单篇判断
真正高效的初筛,不是单篇论文单独判断,而是多篇横向对比。把留下的论文放在一起对比,你会很容易发现哪些是重复的工作,哪些是同一个研究路线,哪些论文的质量明显更强。留下质量强的,删掉重复、薄弱的,比单篇判断更准确,也更节省时间。
这里给大家一个小技巧:现在很多同学都会把论文批量导入UPDF,利用它的文献搜索、AI摘要总结功能,还能快速切换多份文件、给论文打标签批注,不用反复打开关闭PDF文件,初筛效率直接翻倍。尤其是UPDF AI的自动总结摘要功能,几秒钟就能知道一篇论文的核心,判断要不要读更省事。
四、新手初筛最容易犯的3个错误
最后再提醒大家3个常见误区,很多新手都栽在这上面,避开就能少走很多弯路:
❌ 错误1:初筛就逐字精读。初筛阶段读正文,就是最大的时间黑洞!初筛的目的是“判断值不值得读”,不是“读懂”,没必要浪费时间在正文细节上。
❌ 错误2:舍不得删文献。总抱着“万一以后有用呢?”的想法,结果就是PDF越堆越多,永远读不完。要记住80%的文献本来就不值得读,删掉是常态,不是损失。
❌ 错误3:筛完不整理。筛完之后,论文还是一堆杂乱的PDF文件,没有分类、没有标记,后期需要用时还是找不到,等于白筛。初筛必须配合分类、标签或批注,整理好才有用。
总结
最后用一句话,把核心要点总结给大家,记牢就能少踩坑:标题筛掉30%,摘要筛掉30%,图表筛掉20%,最后真正需要精读的,只剩20%——这才是成熟科研人的阅读节奏。
先淘汰一半无用文献,再开始认真精读,比埋头苦读、盲目追赶效率,要高效得多。当你掌握这套5步流程,再配合支持快速搜索、批量阅读和AI总结的工具(比如UPDF),文献筛选这件事,真的可以压缩到10分钟完成。不用再为文献太多而焦虑,科研也会变得轻松很多。