 AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













如果想从PDF文件中提取特定的文本内容,简单的复制粘贴是无法获得理想效果的,尤其是当PDF文件是扫描件或图像格式时。这时,就需要借助UPDF这种专业的PDF编辑工具,它可以通过OCR技术(光学字符识别)从PDF文件中提取文本,并且能够保障内容的完整性。
什么是OCR技术?
OCR技术可以识别PDF文件中的图片和扫描文本,将其转换为可编辑的文字内容。这对于包含大量扫描件或图像的PDF文件尤为实用。UPDF中的OCR功能实现了一键操作,让用户能够快速将PDF中的文本转换为可复制、可搜索、可编辑的内容,从而提高工作效率。
如何使用UPDF提取PDF文本内容?
接下来我们将介绍通过UPDF提取PDF文本内容的具体步骤。
1.打开PDF文件
首先,下载并安装UPDF,打开软件并点击主界面上的“打开文件”按钮,选择你需要提取文本的PDF文档。
2.使用OCR功能识别文本
在UPDF的右侧菜单栏中,找到“使用OCR识别文本”的选项,点击该按钮。OCR功能将帮助你将PDF中的图像或扫描文字转换为可编辑的文本格式。
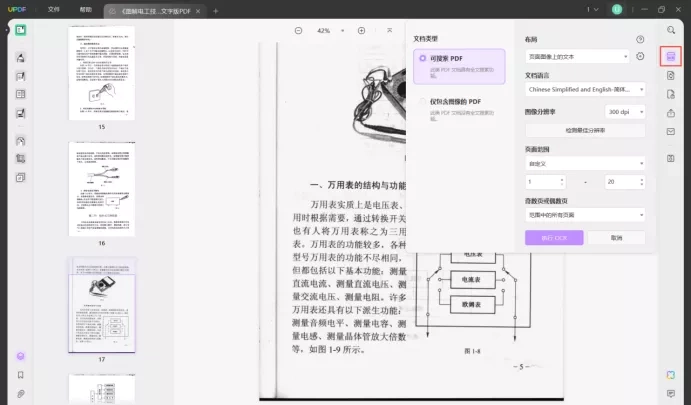
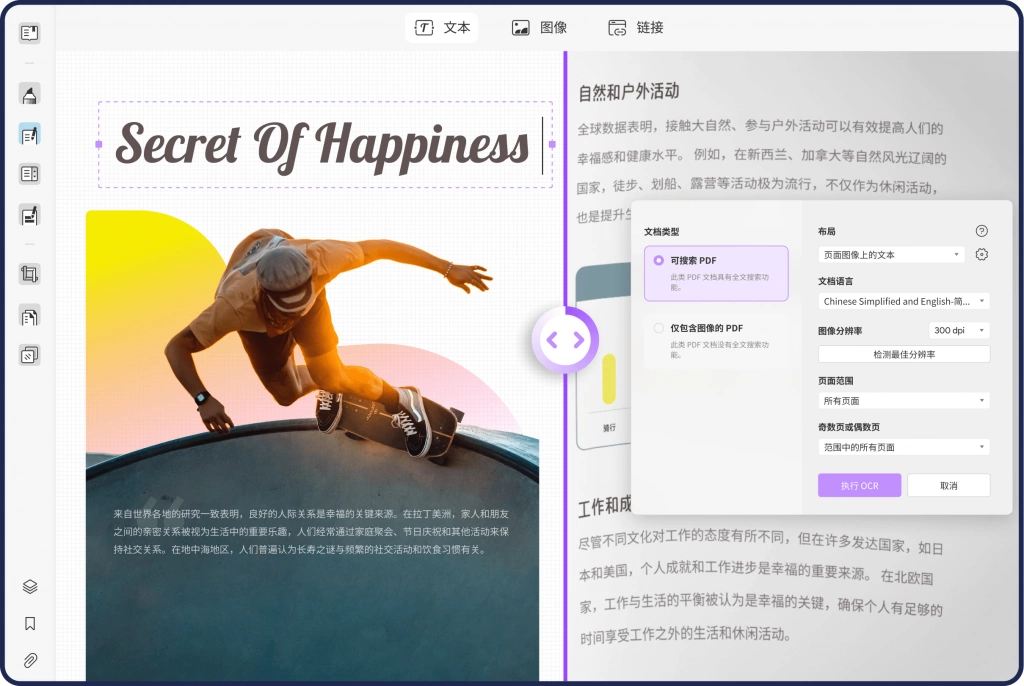
3.选择OCR识别设置
根据PDF文件的类型,UPDF提供了两种OCR模式:
- 可搜索PDF:适用于需要保持PDF格式完整性的文档,OCR会在原始页面上生成可搜索和可选取的文本层。
- 仅包含图像的PDF:适用于扫描件或图片内容较多的PDF文件。
你还可以根据需求调整其他OCR设置,如:
- 布局:选择保留原始文档的布局或者简单文本提取。
- 文档语言:选择文件所用的语言,以提高OCR识别的准确度。
- 图片分辨率:根据PDF文档的清晰度选择合适的图片分辨率。
- 页面范围:如果只需要对部分页面进行OCR识别,可以选择特定页面范围。
- 奇数页或偶数页:进一步精确选择需要处理的页面。
4.执行OCR识别
完成所有设置后,点击“执行OCR”按钮,UPDF会开始处理PDF文档。识别过程根据文件大小和页面数量的不同可能需要几秒到几分钟。完成后,你将能够复制、编辑并搜索PDF中的文本内容。

UPDF的其他文本提取功能
除了OCR识别,UPDF还支持直接从PDF文件中提取文本。以下是几种常见的文本提取方法:
1.手动复制文本
对于纯文本的PDF文件,可以使用UPDF中的文本选择工具,直接手动复制文档中的内容。只需选择你想提取的文本并右键点击选择“复制”,即可将其粘贴到其他文档中。
2.批量文本提取
如果你需要提取多个PDF文件中的文本内容,UPDF还支持批量处理。你可以通过选择多个文件并应用OCR功能或其他提取工具,大大提高工作效率。
UPDF提取图片功能
除了文本提取,UPDF还提供了图片提取功能,可以将PDF文档中的图片单独保存。这对于需要从PDF中提取图片用于报告或其他用途的用户来说非常有帮助。具体步骤如下:
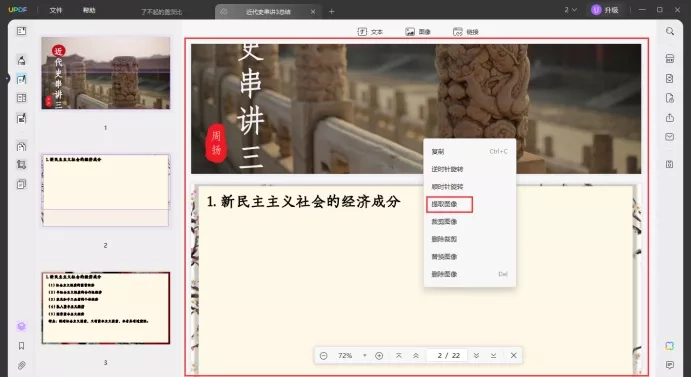
- 在UPDF主界面找到“打开文件”按钮,选择包含图片的PDF文档。
- 在左侧菜单中点击“编辑PDF”按钮。
- 右键点击需要提取的图片,并选择“提取图像”。
- 在提取图像窗口中,选择导出所有图片或自定义提取页面范围。
- 点击“提取”按钮,UPDF将自动将所有图片保存到本地。
总结
从PDF文件中提取文本内容不再是难题,特别是当你使用像UPDF这样功能强大的PDF编辑工具时。通过简单几步操作,你就可以使用OCR技术将PDF中的文本提取为可编辑的内容,并且可以进一步提取图片、批量处理文档。无论是办公还是学习,UPDF都能帮助你更高效地处理PDF文件,推荐大家免费下载并亲自体验其强大的功能。

