AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













在文献检索完成之后,研究者就要对检索到的文献进行阅读。然而,从研究方法的角度来看,阅读并不是检索之后的简单延续,而是一个需要重新组织信息结构的关键环节。大量研究实践表明,即使已经获得了充分的文献资源,如果缺乏清晰的阅读顺序与优先级机制,研究者仍然会在阅读过程中不断重复、回退甚至偏离研究方向,其结果往往表现为阅读量不断增加,而理解结构却始终无法稳定。
这一问题的根本原因,在于多数研究者仍然沿用一种隐性的“线性阅读假设”,即认为文献之间在重要性上是均质的,因此可以按照检索顺序或下载顺序逐篇阅读。然而,在任何一个成熟研究领域中,文献都呈现出明显的层级结构与路径分布,不同文献在研究体系中承担着完全不同的功能。如果忽视这一点,而直接进入逐篇阅读,研究者将难以在早期阶段建立整体框架,从而导致后续理解不断碎片化。
因此,讨论“检索后如何安排阅读顺序”这一问题,本质上并不是回答“先读哪一篇”,而是在解决如何基于文献在研究体系中的位置,建立一套可执行的阅读优先级机制。
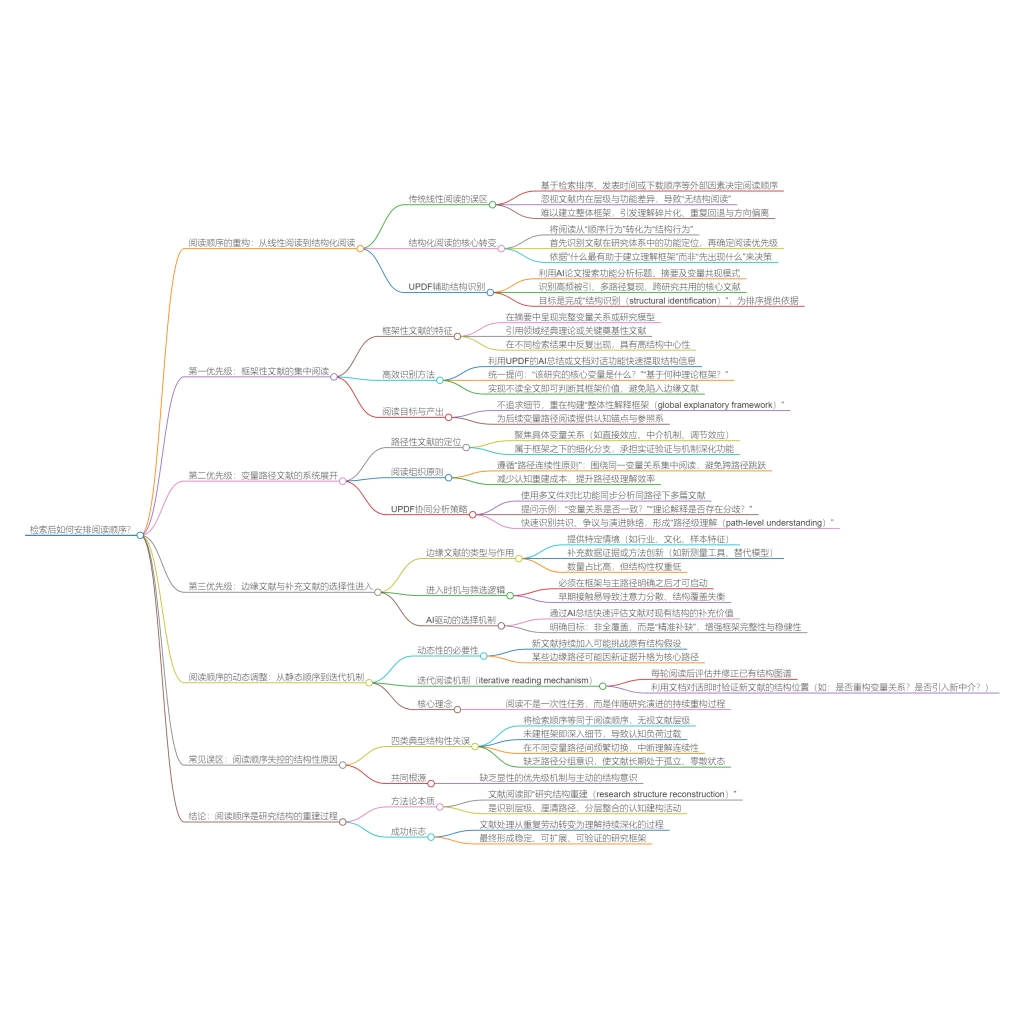
1、阅读顺序的重构:从线性阅读到结构化阅读
在传统经验中,阅读顺序往往由外部因素决定,例如检索结果的排序方式、论文发表时间或个人下载顺序。然而,这种基于外部序列的阅读方式,本质上是一种“无结构阅读”,因为它并未反映文献之间的内在关系。
在方法论层面,更合理的做法是将阅读从“顺序行为”转化为“结构行为”,即首先识别文献在研究体系中的功能,再据此安排阅读顺序。换言之,阅读顺序不应由“先出现什么”决定,而应由“什么最有助于建立理解框架”决定。
在这一阶段,可以借助UPDF的AI论文搜索功能对检索结果进行整体观察,通过分析标题、摘要以及变量共现模式,识别哪些文献在该领域中具有核心地位。例如,那些频繁出现、被多篇研究引用、并且在不同路径中反复出现的文献,通常构成该领域的基础结构。这一过程的关键,并不是立即阅读,而是完成一次结构识别,从而为后续阅读排序提供依据。
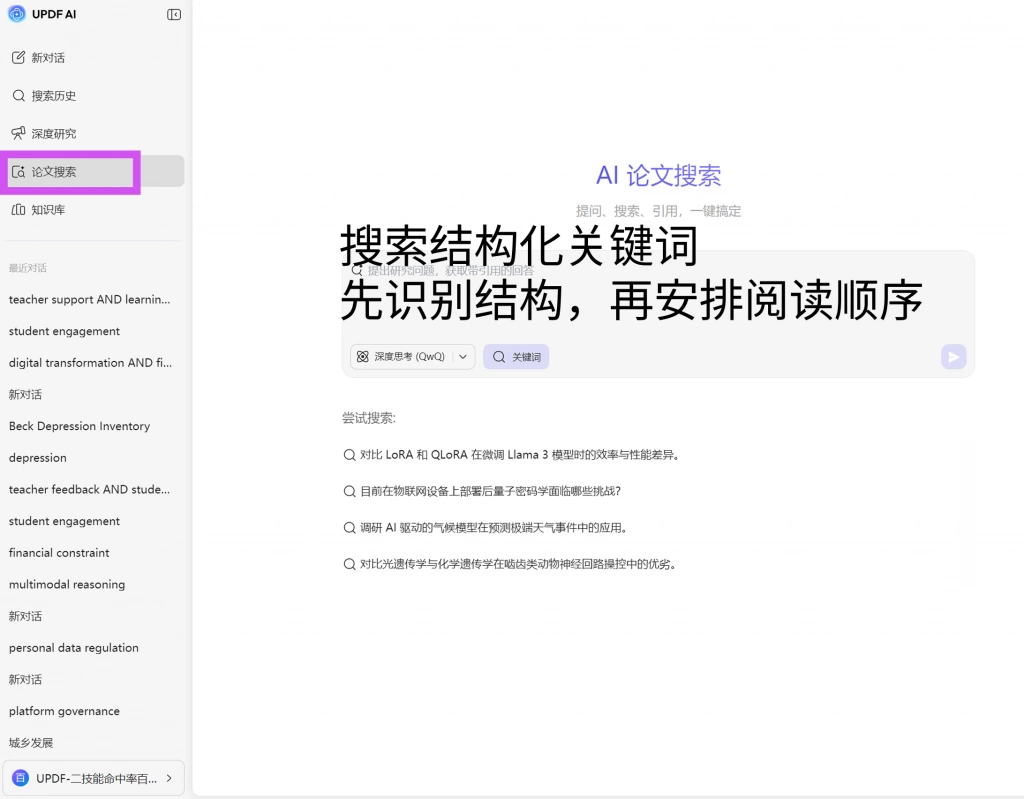
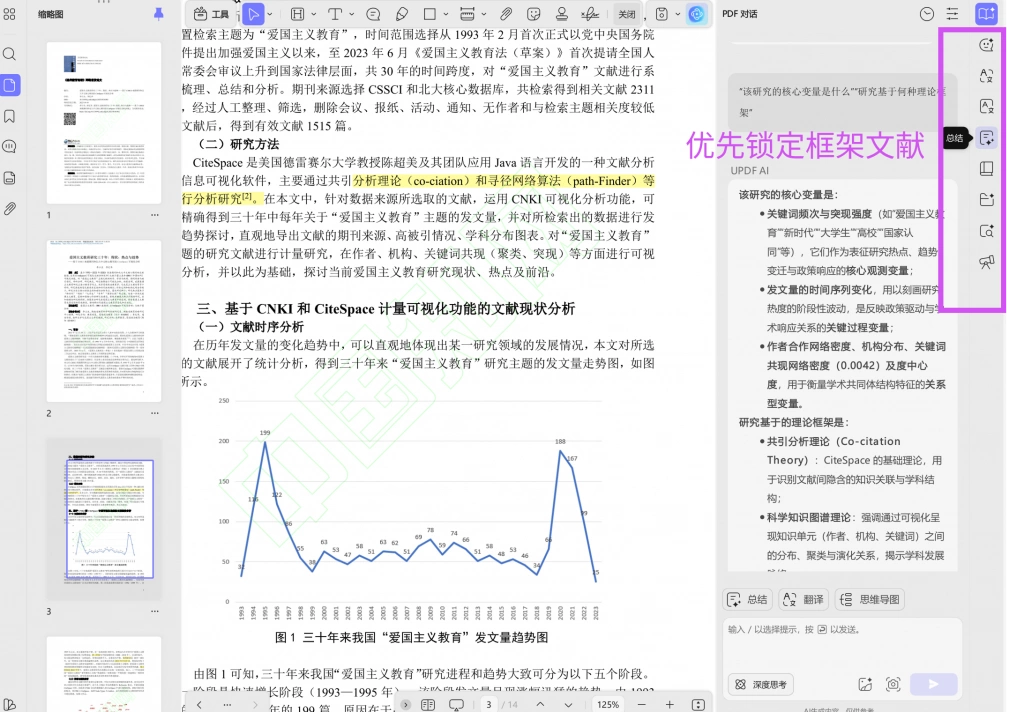
2、第一优先级:框架性文献的集中阅读
在完成初步结构识别之后,阅读的第一优先级应当聚焦于框架性文献。这类文献通常承担着定义研究问题、构建理论基础以及明确变量关系的功能,其特点在于能够在较短篇幅内提供对整个研究领域的系统性概括。
在识别框架性文献时,可以重点关注以下特征:其一,是否在摘要中呈现完整的变量关系或研究模型;其二,是否引用了该领域的经典理论或关键文献;其三,是否在不同检索结果中反复出现,从而表现出较高的结构中心性。
为了提高识别效率,可以利用UPDF的AI总结或文档对话功能对候选文献进行快速结构提取。例如,通过统一提问“该研究的核心变量是什么”“研究基于何种理论框架”,可以在不阅读全文的情况下判断其是否具备框架价值。这样一来,研究者可以优先阅读少量关键文献,而不是在大量边缘文献中消耗时间。
这一阶段的阅读目标,并不是获取细节信息,而是建立一个整体性的解释框架,从而为后续阅读提供参照。
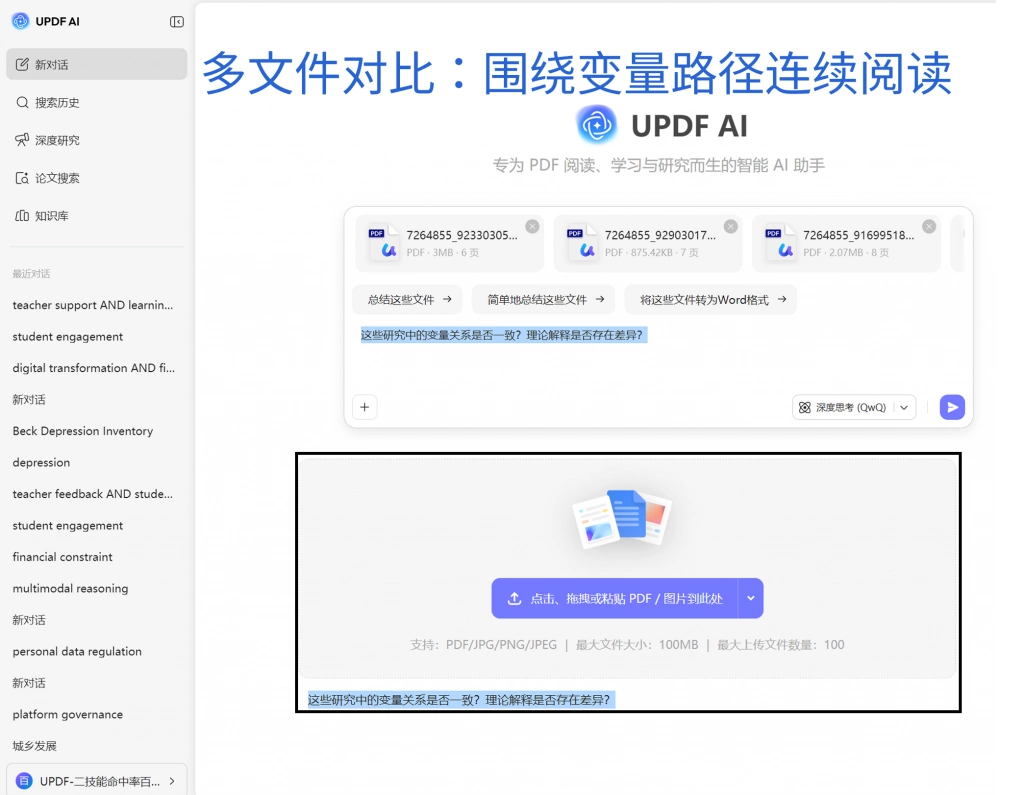
3、第二优先级:变量路径文献的系统展开
在框架文献阅读完成之后,研究者应当进入第二层级,即围绕具体变量关系展开的路径性文献。与框架文献相比,这类文献更加聚焦,通常围绕某一变量关系或研究假设展开,例如直接效应、中介机制或调节效应等。
在这一阶段,阅读顺序应当遵循“路径连续性原则”,即围绕同一变量关系进行集中阅读,而不是在不同路径之间频繁切换。这样做的优势在于,研究者可以在短时间内形成对某一研究路径的完整理解,从而避免在碎片化阅读中反复重建认知结构。
在操作层面,可以借助多文件对比功能对同一路径下的多篇文献进行统一分析。例如,通过同时提问“这些研究中的变量关系是否一致”“理论解释是否存在差异”,可以快速识别不同研究之间的共性与分歧,从而形成对该路径的系统性认识。
这一阶段的核心,不在于阅读数量,而在于通过连续阅读建立路径级理解。
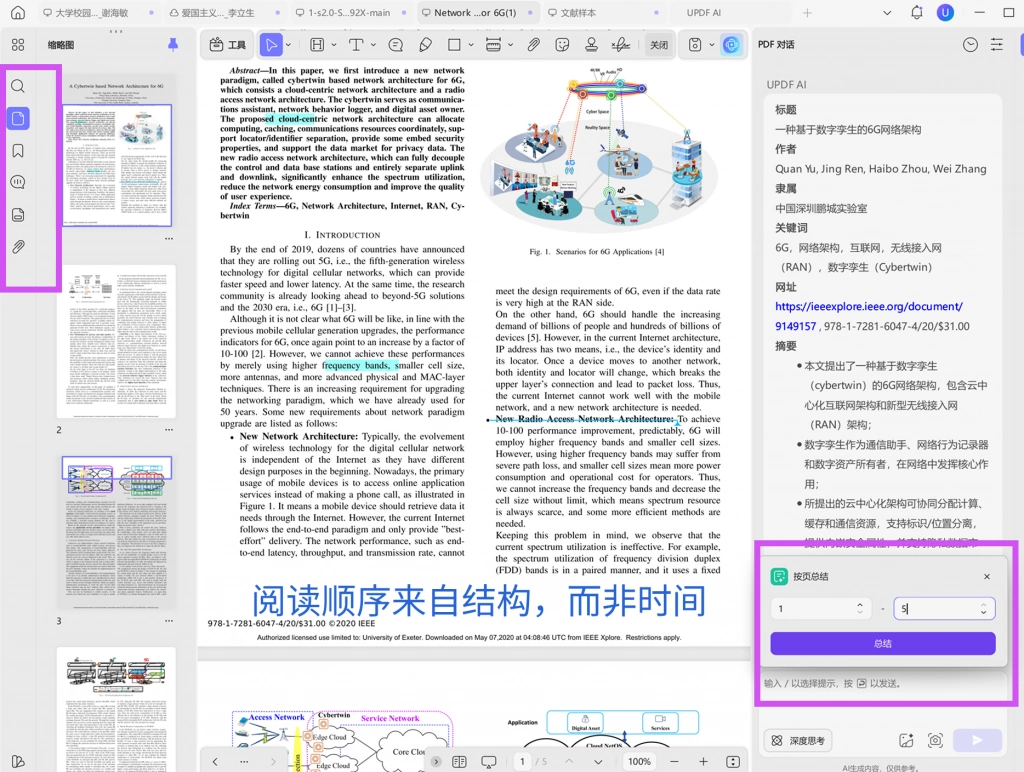
4、第三优先级:边缘文献与补充文献的选择性进入
在完成核心路径阅读之后,剩余文献通常属于补充性或边缘性文献。这类文献虽然在数量上占据多数,但其在研究结构中的作用相对有限,通常用于提供特定情境、补充数据或引入新方法。
如果在阅读初期就进入这一层文献,研究者很容易陷入细节,从而忽视整体结构。因此,这类文献应当在框架与路径明确之后,再进行选择性阅读。
在这一阶段,可以继续利用AI总结快速判断文献价值,从而决定是否需要深入阅读。需要强调的是,这一层阅读的目标不是覆盖全部文献,而是补充已有结构,使其更加完整。
5、阅读顺序的动态调整:从静态顺序到迭代机制
尽管上述三层结构提供了一个基本的阅读顺序,但在实际研究中,文献阅读是一个持续动态变化的过程。当新的文献不断加入时,原有结构可能会发生调整,因此阅读顺序也需要随之更新。
因此,有必要建立一种动态阅读机制,即在每一轮阅读之后,对已有结构进行评估与修正。例如,当某一新文献提供了更具解释力的理论路径时,原本的边缘路径可能需要被重新定位。
在这一过程中,可以通过文档对话快速验证新文献的结构位置,从而避免无效阅读。这种机制的核心,在于将阅读从一次性任务转变为持续迭代过程。
6、常见误区:阅读顺序失控的结构性原因
在实际操作中,阅读顺序混乱往往源于以下几个结构性问题:其一,将检索顺序等同于阅读顺序,从而忽视文献层级;其二,在尚未建立整体框架之前,过早进入细节阅读;其三,在不同变量路径之间频繁跳跃,导致理解不断中断;其四,缺乏路径分组,使文献始终处于孤立状态。
这些问题的共同特点在于:缺乏明确的优先级机制与结构意识。
7、常见问题
1️⃣ 为什么不能按检索顺序阅读? 因为检索顺序不反映研究结构。
2️⃣ 第一批应该读什么? 优先阅读框架性文献。
3️⃣ 如何判断阅读优先级? 依据变量结构与理论框架。
4️⃣ 阅读顺序可以固定吗? 需要动态调整。
总结
从方法论角度来看,文献阅读顺序并不是简单的先后安排,而是一种研究结构重建过程。它要求研究者在阅读过程中不断识别文献层级、建立路径关系,并通过分层阅读逐步形成完整的研究框架。当阅读能够按照这一逻辑展开时,文献处理将不再是重复劳动,而成为理解不断深化的过程。