
请长按识别下载
反馈
![]() UPDF AI
UPDF AI
UPDF是一个强大的AI OCR工具,支持识别38种语言,识别速度快、准确率高,可以轻松将扫描文档转换为可直接编辑的PDF文档。






使用UPDF软件打开扫描文档,点击工具栏的“OCR”图标。
软件弹出OCR设置弹窗,设置完成后点击执行。
软件自动识别文字,可直接修改,修改后保存文件。
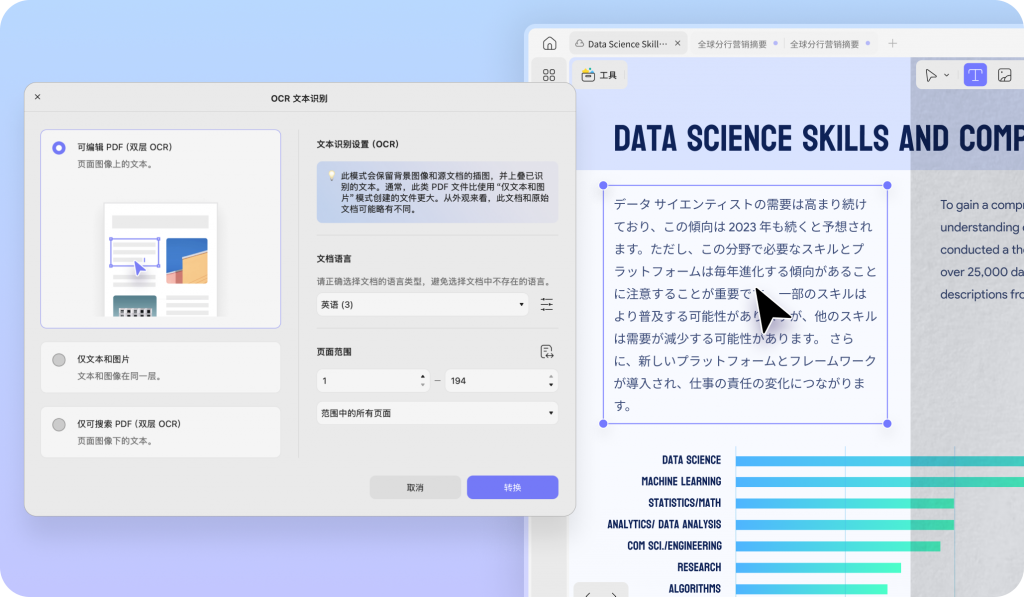
可编辑PDF:在保留原始文档视觉呈现的同时,实现了文本的可搜索、可复制功能。
仅文本和图片:将扫描文档转换为可编辑的PDF文档。
仅可搜索PDF:将扫描文档转换为可搜索(不可编辑)的PDF文档。

UPDF的OCR功能在语言支持上十分出色,提供了38种不同的语言选项供用户选择。你可以通过下拉菜单轻松找到并设定文件对应的语言,这一设计能让UPDF更精准地识别整个文件中的文字,为高效处理PDF内容打下良好基础。
经过OCR光学字符识别技术处理后,UPDF这款专业PDF工具能够精准留存文档原本的版式布局——无论是文字段落的缩进对齐、字体字号的层级区分,还是图片图表的位置分布、页眉页脚的格式规范,都能完整还原原始文档的排版细节,避免因识别过程导致的格式错乱,让处理后的文档既具备可编辑的文本属性,又保持与原件一致的视觉呈现效果。
使用简单
![]()
![]()
准确率
99.9%
80%
识别速度快
![]()
![]()
跨平台使用
一个账号即可在Windows、Mac设备上通用
仅支持一个平台
免费试用
![]()
![]()
支持语言
38种
少于 20 种
逆向 OCR
![]()
![]()
 AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF AI 生成书签
AI 生成书签 AI 总结书签
AI 总结书签 AI 生成水印
AI 生成水印 AI 生成背景
AI 生成背景 AI 生成贴纸
AI 生成贴纸 AI 生成印章
AI 生成印章 AI 编辑与润色
AI 编辑与润色 UPDF Copilot
UPDF Copilot AI 页面检查
AI 页面检查 AI 语义搜索
AI 语义搜索 PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南











 通义千问QwQ |
通义千问QwQ |
 DeepSeek R1
DeepSeek R1
 4.8
4.8

